 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multimodal Approach to SME Credit Scoring Integrating Transaction and Ownership Networks
Oct 10, 2025



Small and Medium-sized Enterprises (SMEs) are known to play a vital role in economic growth, employment, and innovation. However, they tend to face significant challenges in accessing credit due to limited financial histories, collateral constraints, and exposure to macroeconomic shocks. These challenges make an accurate credit risk assessment by lenders crucial, particularly since SMEs frequently operate within interconnected firm networks through which default risk can propagate. This paper presents and tests a novel approach for modelling the risk of SME credit, using a unique large data set of SME loans provided by a prominent financial institution. Specifically, our approach employs Graph Neural Networks to predict SME default using multilayer network data derived from common ownership and financial transactions between firms. We show that combining this information with traditional structured data not only improves application scoring performance, but also explicitly models contagion risk between companies. Further analysis shows how the directionality and intensity of these connections influence financial risk contagion, offering a deeper understanding of the underlying processes. Our findings highlight the predictive power of network data, as well as the role of supply chain networks in exposing SMEs to correlated default risk.
Large-scale Time-Varying Portfolio Optimisation using Graph Attention Networks
Jul 22, 2024Apart from assessing individual asset performance, investors in financial markets also need to consider how a set of firms performs collectively as a portfolio. Whereas traditional Markowitz-based mean-variance portfolios are widespread, network-based optimisation techniques have built upon these developments. However, most studies do not contain firms at risk of default and remove any firms that drop off indices over a certain time. This is the first study to incorporate risky firms and use all the firms in portfolio optimisation. We propose and empirically test a novel method that leverages Graph Attention networks (GATs), a subclass of Graph Neural Networks (GNNs). GNNs, as deep learning-based models, can exploit network data to uncover nonlinear relationships. Their ability to handle high-dimensional features and accommodate customised layers for specific purposes makes them particularly appealing for large-scale problems such as mid- and small-cap portfolio optimization. This study utilises 30 years of data on mid-cap firms, creating graphs of firms using distance correlation and the Triangulated Maximally Filtered Graph approach. These graphs are the inputs to a GAT model that we train using custom layers which impose weight and allocation constraints and a loss function derived from the Sharpe ratio, thus directly maximising portfolio risk-adjusted returns. This new model is benchmarked against a network characteristic-based portfolio, a mean variance-based portfolio, and an equal-weighted portfolio. The results show that the portfolio produced by the GAT-based model outperforms all benchmarks and is consistently superior to other strategies over a long period while also being informative of market dynamics.
Attention-based Dynamic Multilayer Graph Neural Networks for Loan Default Prediction
Feb 01, 2024



Whereas traditional credit scoring tends to employ only individual borrower- or loan-level predictors, it has been acknowledged for some time that connections between borrowers may result in default risk propagating over a network. In this paper, we present a model for credit risk assessment leveraging a dynamic multilayer network built from a Graph Neural Network and a Recurrent Neural Network, each layer reflecting a different source of network connection. We test our methodology in a behavioural credit scoring context using a dataset provided by U.S. mortgage financier Freddie Mac, in which different types of connections arise from the geographical location of the borrower and their choice of mortgage provider. The proposed model considers both types of connections and the evolution of these connections over time. We enhance the model by using a custom attention mechanism that weights the different time snapshots according to their importance. After testing multiple configurations, a model with GAT, LSTM, and the attention mechanism provides the best results. Empirical results demonstrate that, when it comes to predicting probability of default for the borrowers, our proposed model brings both better results and novel insights for the analysis of the importance of connections and timestamps, compared to traditional methods.
A transformer-based model for default prediction in mid-cap corporate markets
Nov 18, 2021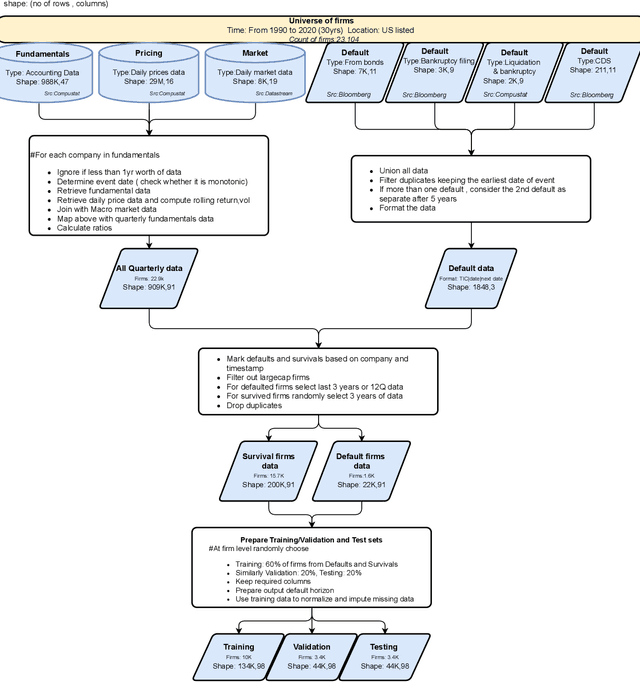
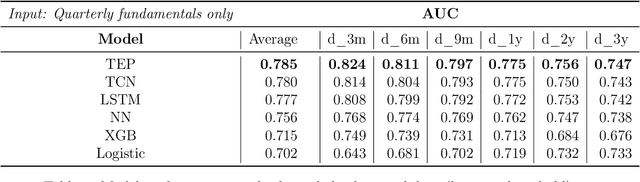
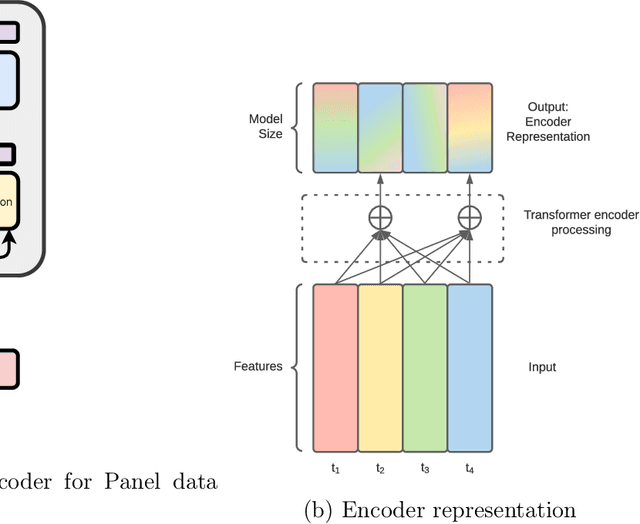
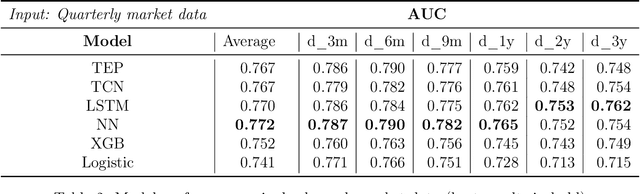
In this paper, we study mid-cap companies, i.e. publicly traded companies with less than US $10 billion in market capitalisation. Using a large dataset of US mid-cap companies observed over 30 years, we look to predict the default probability term structure over the medium term and understand which data sources (i.e. fundamental, market or pricing data) contribute most to the default risk. Whereas existing methods typically require that data from different time periods are first aggregated and turned into cross-sectional features, we frame the problem as a multi-label time-series classification problem. We adapt transformer models, a state-of-the-art deep learning model emanating from the natural language processing domain, to the credit risk modelling setting. We also interpret the predictions of these models using attention heat maps. To optimise the model further, we present a custom loss function for multi-label classification and a novel multi-channel architecture with differential training that gives the model the ability to use all input data efficiently. Our results show the proposed deep learning architecture's superior performance, resulting in a 13% improvement in AUC (Area Under the receiver operating characteristic Curve) over traditional models. We also demonstrate how to produce an importance ranking for the different data sources and the temporal relationships using a Shapley approach specific to these models.