 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-Local Autonomous LLM-Guided Neural Architecture Search for Multiclass Multimodal Time-Series Classification
Mar 16, 2026Applying machine learning to sensitive time-series data is often bottlenecked by the iteration loop: Performance depends strongly on preprocessing and architecture, yet training often has to run on-premise under strict data-local constraints. This is a common problem in healthcare and other privacy-constrained domains (e.g., a hospital developing deep learning models on patient EEG). This bottleneck is particularly challenging in multimodal fusion, where sensor modalities must be individually preprocessed and then combined. LLM-guided neural architecture search (NAS) can automate this exploration, but most existing workflows assume cloud execution or access to data-derived artifacts that cannot be exposed. We present a novel data-local, LLM-guided search framework that handles candidate pipelines remotely while executing all training and evaluation locally under a fixed protocol. The controller observes only trial-level summaries, such as pipeline descriptors, metrics, learning-curve statistics, and failure logs, without ever accessing raw samples or intermediate feature representations. Our framework targets multiclass, multimodal learning via one-vs-rest binary experts per class and modality, a lightweight fusion MLP, and joint search over expert architectures and modality-specific preprocessing. We evaluate our method on two regimes: UEA30 (public multivariate time-series classification dataset) and SleepEDFx sleep staging (heterogeneous clinical modalities such as EEG, EOG, and EMG). The results show that the modular baseline model is strong, and the LLM-guided NAS further improves it. Notably, our method finds models that perform within published ranges across most benchmark datasets. Across both settings, our method reduces manual intervention by enabling unattended architecture search while keeping sensitive data on-premise.
A Multimodal Approach to SME Credit Scoring Integrating Transaction and Ownership Networks
Oct 10, 2025



Small and Medium-sized Enterprises (SMEs) are known to play a vital role in economic growth, employment, and innovation. However, they tend to face significant challenges in accessing credit due to limited financial histories, collateral constraints, and exposure to macroeconomic shocks. These challenges make an accurate credit risk assessment by lenders crucial, particularly since SMEs frequently operate within interconnected firm networks through which default risk can propagate. This paper presents and tests a novel approach for modelling the risk of SME credit, using a unique large data set of SME loans provided by a prominent financial institution. Specifically, our approach employs Graph Neural Networks to predict SME default using multilayer network data derived from common ownership and financial transactions between firms. We show that combining this information with traditional structured data not only improves application scoring performance, but also explicitly models contagion risk between companies. Further analysis shows how the directionality and intensity of these connections influence financial risk contagion, offering a deeper understanding of the underlying processes. Our findings highlight the predictive power of network data, as well as the role of supply chain networks in exposing SMEs to correlated default risk.
Chaos into Order: Neural Framework for Expected Value Estimation of Stochastic Partial Differential Equations
Feb 05, 2025



Stochastic Partial Differential Equations (SPDEs) are fundamental to modeling complex systems in physics, finance, and engineering, yet their numerical estimation remains a formidable challenge. Traditional methods rely on discretization, introducing computational inefficiencies, and limiting applicability in high-dimensional settings. In this work, we introduce a novel neural framework for SPDE estimation that eliminates the need for discretization, enabling direct estimation of expected values across arbitrary spatio-temporal points. We develop and compare two distinct neural architectures: Loss Enforced Conditions (LEC), which integrates physical constraints into the loss function, and Model Enforced Conditions (MEC), which embeds these constraints directly into the network structure. Through extensive experiments on the stochastic heat equation, Burgers' equation, and Kardar-Parisi-Zhang (KPZ) equation, we reveal a trade-off: While LEC achieves superior residual minimization and generalization, MEC enforces initial conditions with absolute precision and exceptionally high accuracy in boundary condition enforcement. Our findings highlight the immense potential of neural-based SPDE solvers, particularly for high-dimensional problems where conventional techniques falter. By circumventing discretization and explicitly modeling uncertainty, our approach opens new avenues for solving SPDEs in fields ranging from quantitative finance to turbulence modeling. To the best of our knowledge, this is the first neural framework capable of directly estimating the expected values of SPDEs in an entirely non-discretized manner, offering a step forward in scientific computing.
Attention-based Dynamic Multilayer Graph Neural Networks for Loan Default Prediction
Feb 01, 2024



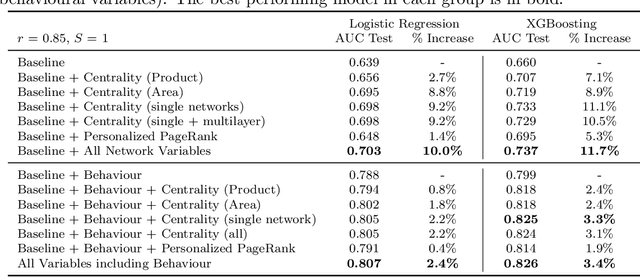
Whereas traditional credit scoring tends to employ only individual borrower- or loan-level predictors, it has been acknowledged for some time that connections between borrowers may result in default risk propagating over a network. In this paper, we present a model for credit risk assessment leveraging a dynamic multilayer network built from a Graph Neural Network and a Recurrent Neural Network, each layer reflecting a different source of network connection. We test our methodology in a behavioural credit scoring context using a dataset provided by U.S. mortgage financier Freddie Mac, in which different types of connections arise from the geographical location of the borrower and their choice of mortgage provider. The proposed model considers both types of connections and the evolution of these connections over time. We enhance the model by using a custom attention mechanism that weights the different time snapshots according to their importance. After testing multiple configurations, a model with GAT, LSTM, and the attention mechanism provides the best results. Empirical results demonstrate that, when it comes to predicting probability of default for the borrowers, our proposed model brings both better results and novel insights for the analysis of the importance of connections and timestamps, compared to traditional methods.
INFLECT-DGNN: Influencer Prediction with Dynamic Graph Neural Networks
Jul 16, 2023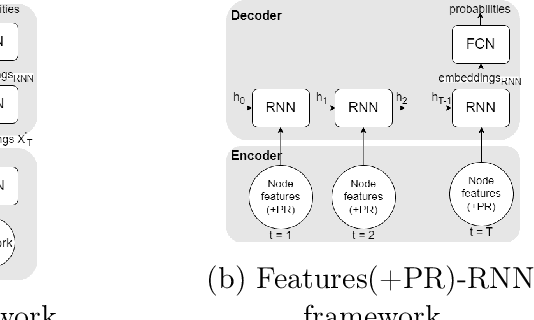

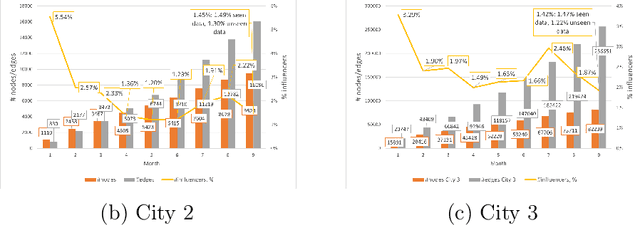
Leveraging network information for predictive modeling has become widespread in many domains. Within the realm of referral and targeted marketing, influencer detection stands out as an area that could greatly benefit from the incorporation of dynamic network representation due to the ongoing development of customer-brand relationships. To elaborate this idea, we introduce INFLECT-DGNN, a new framework for INFLuencer prEdiCTion with Dynamic Graph Neural Networks that combines Graph Neural Networks (GNN) and Recurrent Neural Networks (RNN) with weighted loss functions, the Synthetic Minority Oversampling TEchnique (SMOTE) adapted for graph data, and a carefully crafted rolling-window strategy. To evaluate predictive performance, we utilize a unique corporate data set with networks of three cities and derive a profit-driven evaluation methodology for influencer prediction. Our results show how using RNN to encode temporal attributes alongside GNNs significantly improves predictive performance. We compare the results of various models to demonstrate the importance of capturing graph representation, temporal dependencies, and using a profit-driven methodology for evaluation.
Influencer Detection with Dynamic Graph Neural Networks
Nov 15, 2022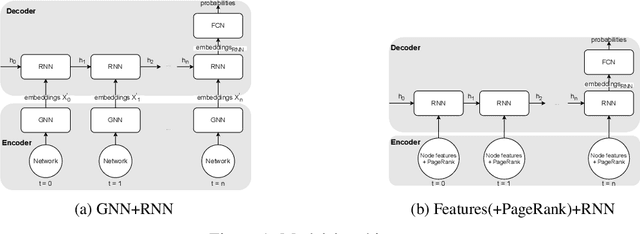
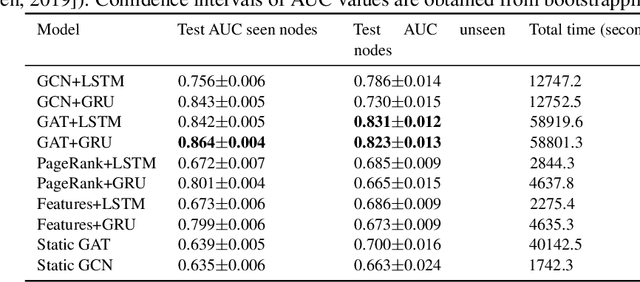
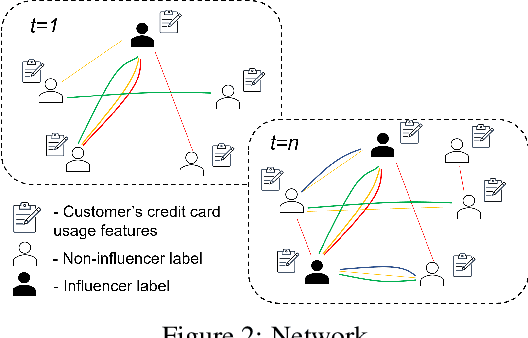
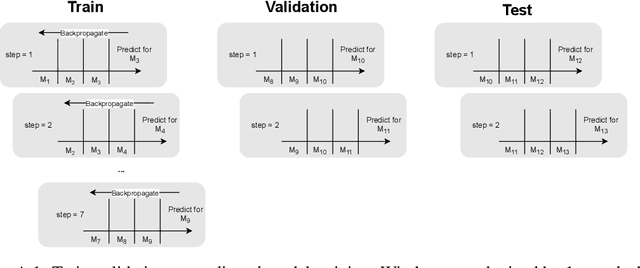
Leveraging network information for prediction tasks has become a common practice in many domains. Being an important part of targeted marketing, influencer detection can potentially benefit from incorporating dynamic network representation. In this work, we investigate different dynamic Graph Neural Networks (GNNs) configurations for influencer detection and evaluate their prediction performance using a unique corporate data set. We show that using deep multi-head attention in GNN and encoding temporal attributes significantly improves performance. Furthermore, our empirical evaluation illustrates that capturing neighborhood representation is more beneficial that using network centrality measures.
Multilayer Network Analysis for Improved Credit Risk Prediction
Oct 19, 2020
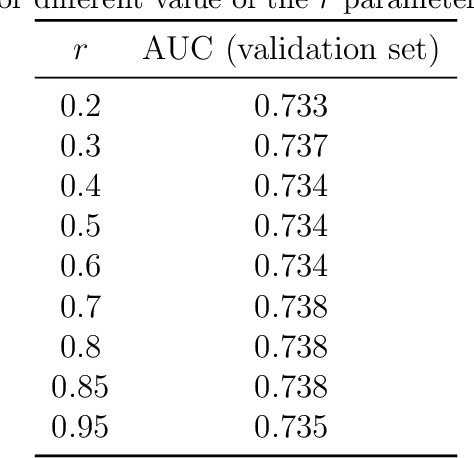
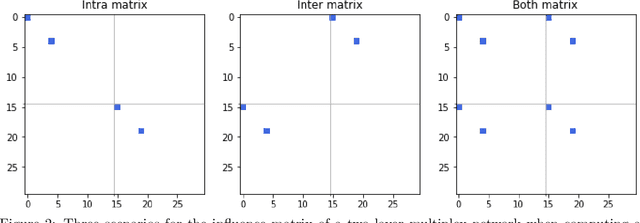
We present a multilayer network model for credit risk assessment. Our model accounts for multiple connections between borrowers (such as their geographic location and their economic activity) and allows for explicitly modelling the interaction between connected borrowers. We develop a multilayer personalized PageRank algorithm that allows quantifying the strength of the default exposure of any borrower in the network. We test our methodology in an agricultural lending framework, where it has been suspected for a long time default correlates between borrowers when they are subject to the same structural risks. Our results show there are significant predictive gains just by including centrality multilayer network information to the model, and this gains are increased by more complex information such as the multilayer PageRank variables. The results suggest default risk is highest when an individual is connected to many defaulters, but this risk is mitigated by the size of the neighbourhood of the individual, showing both default risk and financial stability propagate throughout the network.
Social network analytics for supervised fraud detection in insurance
Sep 15, 2020



Insurance fraud occurs when policyholders file claims that are exaggerated or based on intentional damages. This contribution develops a fraud detection strategy by extracting insightful information from the social network of a claim. First, we construct a network by linking claims with all their involved parties, including the policyholders, brokers, experts, and garages. Next, we establish fraud as a social phenomenon in the network and use the BiRank algorithm with a fraud specific query vector to compute a fraud score for each claim. From the network, we extract features related to the fraud scores as well as the claims' neighborhood structure. Finally, we combine these network features with the claim-specific features and build a supervised model with fraud in motor insurance as the target variable. Although we build a model for only motor insurance, the network includes claims from all available lines of business. Our results show that models with features derived from the network perform well when detecting fraud and even outperform the models using only the classical claim-specific features. Combining network and claim-specific features further improves the performance of supervised learning models to detect fraud. The resulting model flags highly suspicions claims that need to be further investigated. Our approach provides a guided and intelligent selection of claims and contributes to a more effective fraud investigation process.
Evolution of Credit Risk Using a Personalized Pagerank Algorithm for Multilayer Networks
May 25, 2020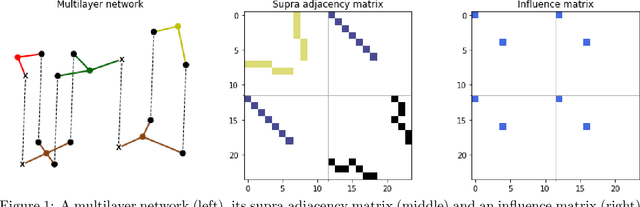
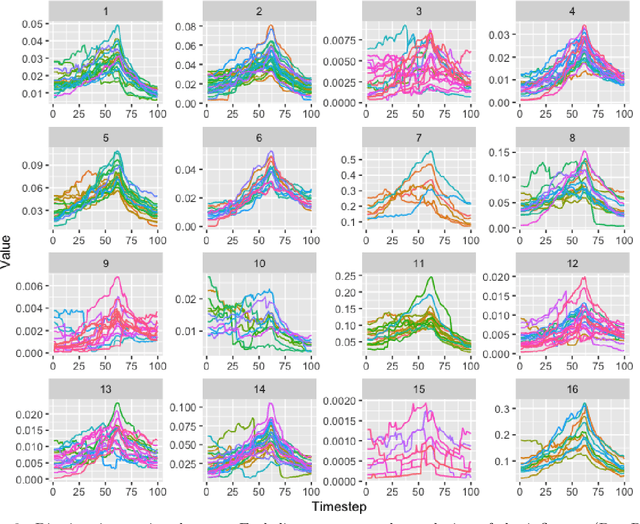
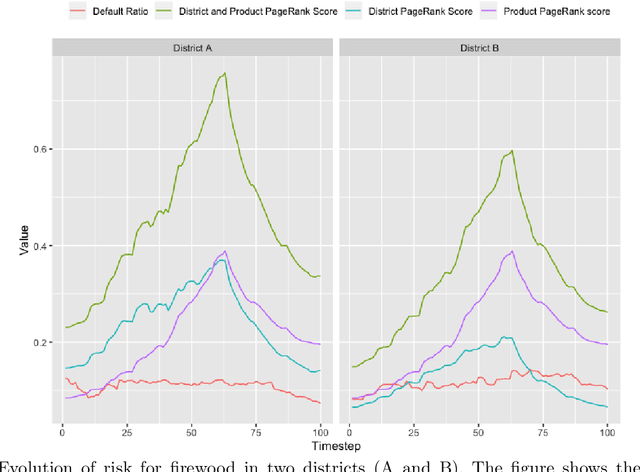
In this paper we present a novel algorithm to study the evolution of credit risk across complex multilayer networks. Pagerank-like algorithms allow for the propagation of an influence variable across single networks, and allow quantifying the risk single entities (nodes) are subject to given the connection they have to other nodes in the network. Multilayer networks, on the other hand, are networks where subset of nodes can be associated to a unique set (layer), and where edges connect elements either intra or inter networks. Our personalized PageRank algorithm for multilayer networks allows for quantifying how credit risk evolves across time and propagates through these networks. By using bipartite networks in each layer, we can quantify the risk of various components, not only the loans. We test our method in an agricultural lending dataset, and our results show how default risk is a challenging phenomenon that propagates and evolves through the network across time.
The Value of Big Data for Credit Scoring: Enhancing Financial Inclusion using Mobile Phone Data and Social Network Analytics
Feb 23, 2020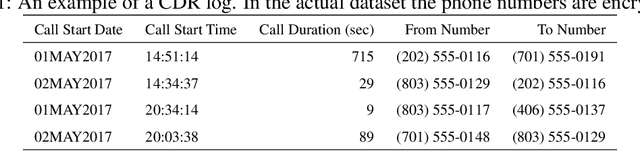
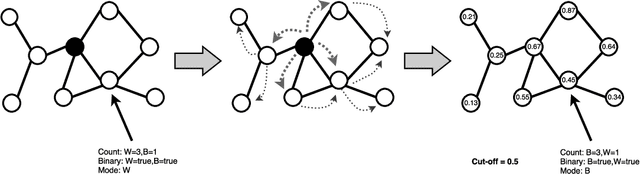

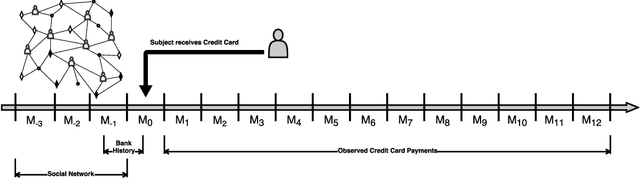
Credit scoring is without a doubt one of the oldest applications of analytics. In recent years, a multitude of sophisticated classification techniques have been developed to improve the statistical performance of credit scoring models. Instead of focusing on the techniques themselves, this paper leverages alternative data sources to enhance both statistical and economic model performance. The study demonstrates how including call networks, in the context of positive credit information, as a new Big Data source has added value in terms of profit by applying a profit measure and profit-based feature selection. A unique combination of datasets, including call-detail records, credit and debit account information of customers is used to create scorecards for credit card applicants. Call-detail records are used to build call networks and advanced social network analytics techniques are applied to propagate influence from prior defaulters throughout the network to produce influence scores. The results show that combining call-detail records with traditional data in credit scoring models significantly increases their performance when measured in AUC. In terms of profit, the best model is the one built with only calling behavior features. In addition, the calling behavior features are the most predictive in other models, both in terms of statistical and economic performance. The results have an impact in terms of ethical use of call-detail records, regulatory implications, financial inclusion, as well as data sharing and privacy.