 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfluencer Detection with Dynamic Graph Neural Networks
Nov 15, 2022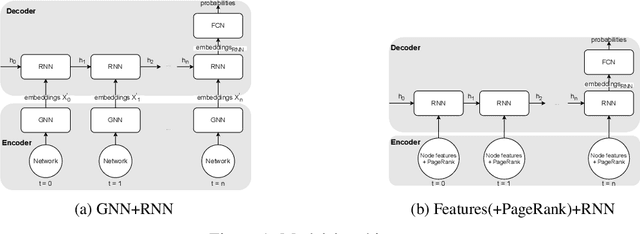
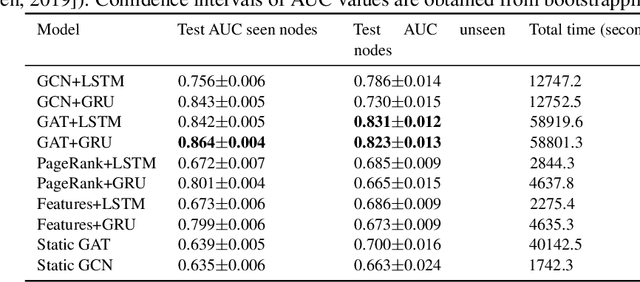
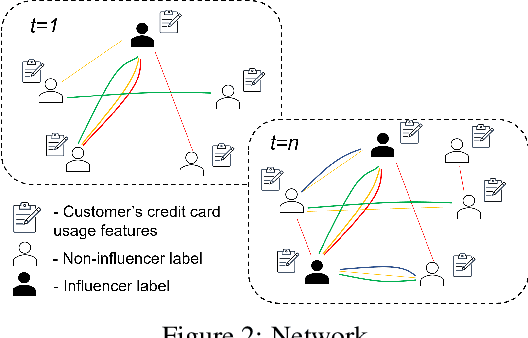
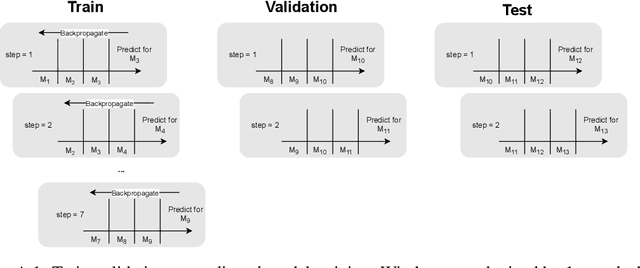
Leveraging network information for prediction tasks has become a common practice in many domains. Being an important part of targeted marketing, influencer detection can potentially benefit from incorporating dynamic network representation. In this work, we investigate different dynamic Graph Neural Networks (GNNs) configurations for influencer detection and evaluate their prediction performance using a unique corporate data set. We show that using deep multi-head attention in GNN and encoding temporal attributes significantly improves performance. Furthermore, our empirical evaluation illustrates that capturing neighborhood representation is more beneficial that using network centrality measures.
Privacy-Preserving Machine Learning for Collaborative Data Sharing via Auto-encoder Latent Space Embeddings
Nov 11, 2022Privacy-preserving machine learning in data-sharing processes is an ever-critical task that enables collaborative training of Machine Learning (ML) models without the need to share the original data sources. It is especially relevant when an organization must assure that sensitive data remains private throughout the whole ML pipeline, i.e., training and inference phases. This paper presents an innovative framework that uses Representation Learning via autoencoders to generate privacy-preserving embedded data. Thus, organizations can share the data representation to increase machine learning models' performance in scenarios with more than one data source for a shared predictive downstream task.
Ensemble of Example-Dependent Cost-Sensitive Decision Trees
May 18, 2015



Several real-world classification problems are example-dependent cost-sensitive in nature, where the costs due to misclassification vary between examples and not only within classes. However, standard classification methods do not take these costs into account, and assume a constant cost of misclassification errors. In previous works, some methods that take into account the financial costs into the training of different algorithms have been proposed, with the example-dependent cost-sensitive decision tree algorithm being the one that gives the highest savings. In this paper we propose a new framework of ensembles of example-dependent cost-sensitive decision-trees. The framework consists in creating different example-dependent cost-sensitive decision trees on random subsamples of the training set, and then combining them using three different combination approaches. Moreover, we propose two new cost-sensitive combination approaches; cost-sensitive weighted voting and cost-sensitive stacking, the latter being based on the cost-sensitive logistic regression method. Finally, using five different databases, from four real-world applications: credit card fraud detection, churn modeling, credit scoring and direct marketing, we evaluate the proposed method against state-of-the-art example-dependent cost-sensitive techniques, namely, cost-proportionate sampling, Bayes minimum risk and cost-sensitive decision trees. The results show that the proposed algorithms have better results for all databases, in the sense of higher savings.