 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacy-Preserving Machine Learning for Collaborative Data Sharing via Auto-encoder Latent Space Embeddings
Nov 11, 2022



Privacy-preserving machine learning in data-sharing processes is an ever-critical task that enables collaborative training of Machine Learning (ML) models without the need to share the original data sources. It is especially relevant when an organization must assure that sensitive data remains private throughout the whole ML pipeline, i.e., training and inference phases. This paper presents an innovative framework that uses Representation Learning via autoencoders to generate privacy-preserving embedded data. Thus, organizations can share the data representation to increase machine learning models' performance in scenarios with more than one data source for a shared predictive downstream task.
Supporting Financial Inclusion with Graph Machine Learning and Super-App Alternative Data
Feb 19, 2021
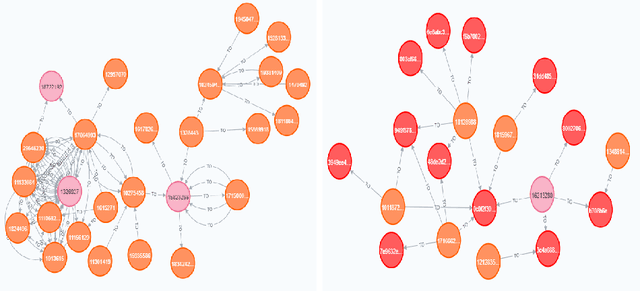
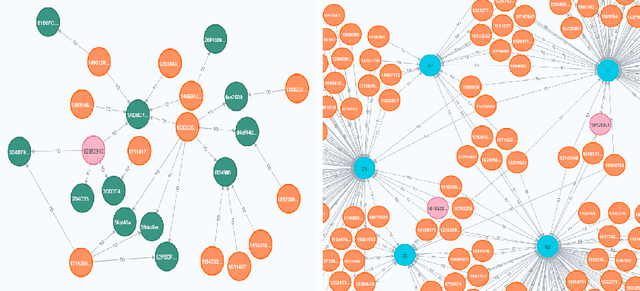
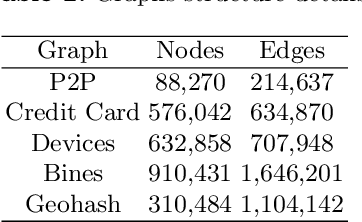
The presence of Super-Apps have changed the way we think about the interactions between users and commerce. It then comes as no surprise that it is also redefining the way banking is done. The paper investigates how different interactions between users within a Super-App provide a new source of information to predict borrower behavior. To this end, two experiments with different graph-based methodologies are proposed, the first uses graph based features as input in a classification model and the second uses graph neural networks. Our results show that variables of centrality, behavior of neighboring users and transactionality of a user constituted new forms of knowledge that enhance statistical and financial performance of credit risk models. Furthermore, opportunities are identified for Super-Apps to redefine the definition of credit risk by contemplating all the environment that their platforms entail, leading to a more inclusive financial system.