 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Credit Limit Adjustments Under Adversarial Goals Using Reinforcement Learning
Jun 27, 2023

Reinforcement learning has been explored for many problems, from video games with deterministic environments to portfolio and operations management in which scenarios are stochastic; however, there have been few attempts to test these methods in banking problems. In this study, we sought to find and automatize an optimal credit card limit adjustment policy by employing reinforcement learning techniques. In particular, because of the historical data available, we considered two possible actions per customer, namely increasing or maintaining an individual's current credit limit. To find this policy, we first formulated this decision-making question as an optimization problem in which the expected profit was maximized; therefore, we balanced two adversarial goals: maximizing the portfolio's revenue and minimizing the portfolio's provisions. Second, given the particularities of our problem, we used an offline learning strategy to simulate the impact of the action based on historical data from a super-app (i.e., a mobile application that offers various services from goods deliveries to financial products) in Latin America to train our reinforcement learning agent. Our results show that a Double Q-learning agent with optimized hyperparameters can outperform other strategies and generate a non-trivial optimal policy reflecting the complex nature of this decision. Our research not only establishes a conceptual structure for applying reinforcement learning framework to credit limit adjustment, presenting an objective technique to make these decisions primarily based on data-driven methods rather than relying only on expert-driven systems but also provides insights into the effect of alternative data usage for determining these modifications.
Proactive Detractor Detection Framework Based on Message-Wise Sentiment Analysis Over Customer Support Interactions
Nov 08, 2022



In this work, we propose a framework relying solely on chat-based customer support (CS) interactions for predicting the recommendation decision of individual users. For our case study, we analyzed a total number of 16.4k users and 48.7k customer support conversations within the financial vertical of a large e-commerce company in Latin America. Consequently, our main contributions and objectives are to use Natural Language Processing (NLP) to assess and predict the recommendation behavior where, in addition to using static sentiment analysis, we exploit the predictive power of each user's sentiment dynamics. Our results show that, with respective feature interpretability, it is possible to predict the likelihood of a user to recommend a product or service, based solely on the message-wise sentiment evolution of their CS conversations in a fully automated way.
Feature-Level Fusion of Super-App and Telecommunication Alternative Data Sources for Credit Card Fraud Detection
Nov 05, 2021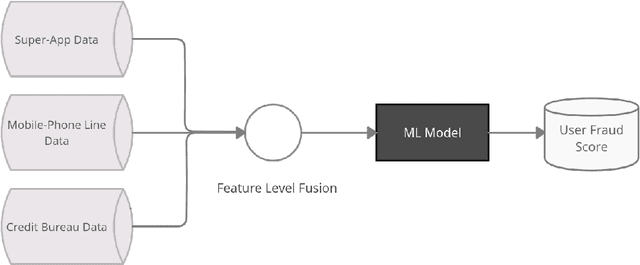

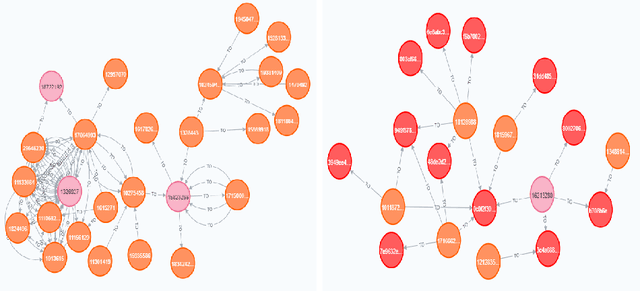
Identity theft is a major problem for credit lenders when there's not enough data to corroborate a customer's identity. Among super-apps large digital platforms that encompass many different services this problem is even more relevant; losing a client in one branch can often mean losing them in other services. In this paper, we review the effectiveness of a feature-level fusion of super-app customer information, mobile phone line data, and traditional credit risk variables for the early detection of identity theft credit card fraud. Through the proposed framework, we achieved better performance when using a model whose input is a fusion of alternative data and traditional credit bureau data, achieving a ROC AUC score of 0.81. We evaluate our approach over approximately 90,000 users from a credit lender's digital platform database. The evaluation was performed using not only traditional ML metrics but the financial costs as well.
Relational Graph Neural Networks for Fraud Detection in a Super-App environment
Jul 30, 2021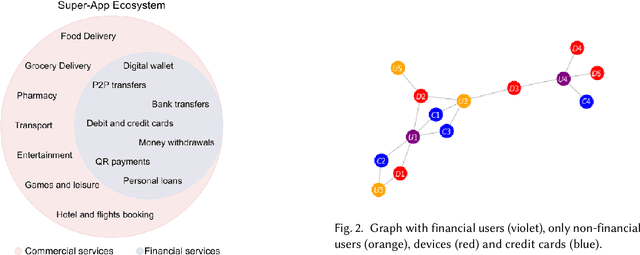

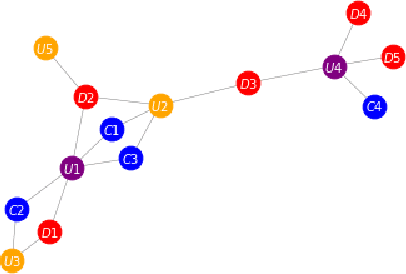

Large digital platforms create environments where different types of user interactions are captured, these relationships offer a novel source of information for fraud detection problems. In this paper we propose a framework of relational graph convolutional networks methods for fraudulent behaviour prevention in the financial services of a Super-App. To this end, we apply the framework on different heterogeneous graphs of users, devices, and credit cards; and finally use an interpretability algorithm for graph neural networks to determine the most important relations to the classification task of the users. Our results show that there is an added value when considering models that take advantage of the alternative data of the Super-App and the interactions found in their high connectivity, further proofing how they can leverage that into better decisions and fraud detection strategies.
Enhancing User' s Income Estimation with Super-App Alternative Data
Apr 12, 2021
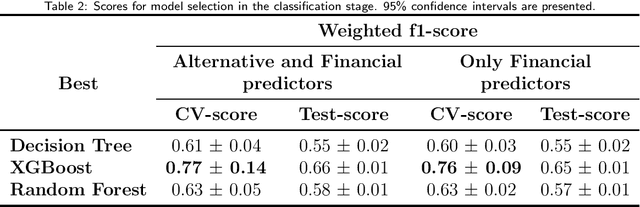
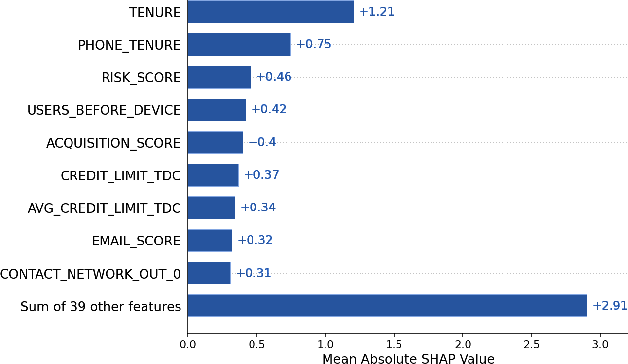
This paper presents the advantages of alternative data from Super-Apps to enhance user' s income estimation models. It compares the performance of these alternative data sources with the performance of industry-accepted bureau income estimators that takes into account only financial system information; successfully showing that the alternative data manage to capture information that bureau income estimators do not. By implementing the TreeSHAP method for Stochastic Gradient Boosting Interpretation, this paper highlights which of the customer' s behavioral and transactional patterns within a Super-App have a stronger predictive power when estimating user' s income. Ultimately, this paper shows the incentive for financial institutions to seek to incorporate alternative data into constructing their risk profiles.
Supporting Financial Inclusion with Graph Machine Learning and Super-App Alternative Data
Feb 19, 2021
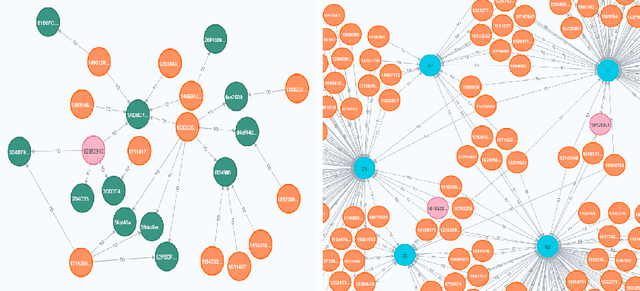
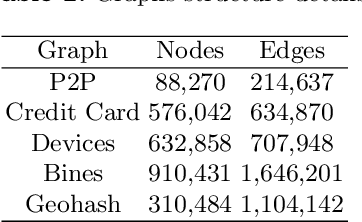
The presence of Super-Apps have changed the way we think about the interactions between users and commerce. It then comes as no surprise that it is also redefining the way banking is done. The paper investigates how different interactions between users within a Super-App provide a new source of information to predict borrower behavior. To this end, two experiments with different graph-based methodologies are proposed, the first uses graph based features as input in a classification model and the second uses graph neural networks. Our results show that variables of centrality, behavior of neighboring users and transactionality of a user constituted new forms of knowledge that enhance statistical and financial performance of credit risk models. Furthermore, opportunities are identified for Super-Apps to redefine the definition of credit risk by contemplating all the environment that their platforms entail, leading to a more inclusive financial system.
Super-App Behavioral Patterns in Credit Risk Models: Financial, Statistical and Regulatory Implications
May 09, 2020

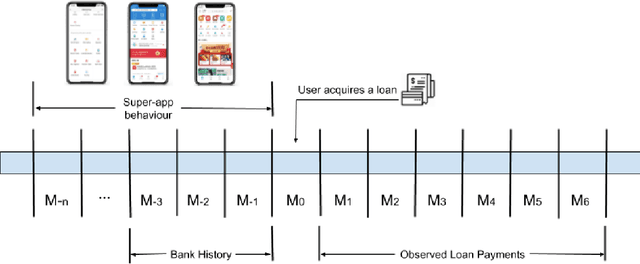

In this paper we present the impact of alternative data that originates from an app-based marketplace, in contrast to traditional bureau data, upon credit scoring models. These alternative data sources have shown themselves to be immensely powerful in predicting borrower behavior in segments traditionally underserved by banks and financial institutions. Our results, validated across two countries, show that these new sources of data are particularly useful for predicting financial behavior in low-wealth and young individuals, who are also the most likely to engage with alternative lenders. Furthermore, using the TreeSHAP method for Stochastic Gradient Boosting interpretation, our results also revealed interesting non-linear trends in the variables originating from the app, which would not normally be available to traditional banks. Our results represent an opportunity for technology companies to disrupt traditional banking by correctly identifying alternative data sources and handling this new information properly. At the same time alternative data must be carefully validated to overcome regulatory hurdles across diverse jurisdictions.