 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre causal effect estimations enough for optimal recommendations under multitreatment scenarios?
Oct 07, 2024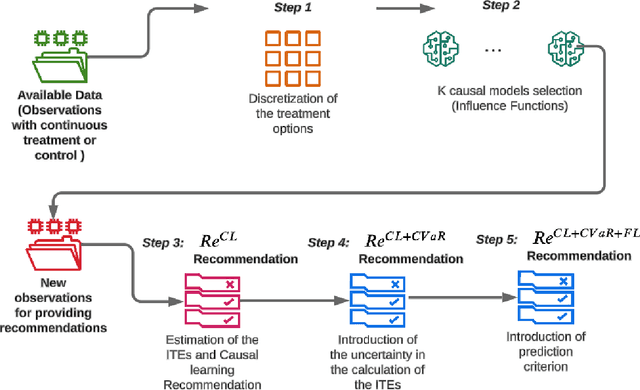
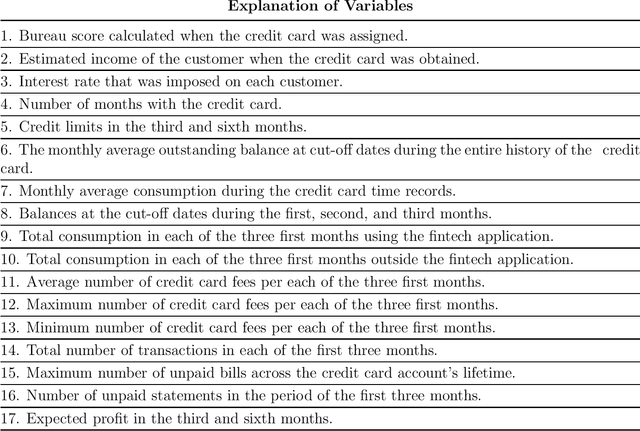
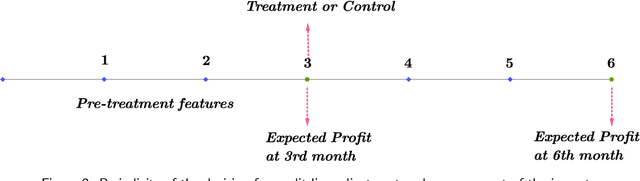

When making treatment selection decisions, it is essential to include a causal effect estimation analysis to compare potential outcomes under different treatments or controls, assisting in optimal selection. However, merely estimating individual treatment effects may not suffice for truly optimal decisions. Our study addressed this issue by incorporating additional criteria, such as the estimations' uncertainty, measured by the conditional value-at-risk, commonly used in portfolio and insurance management. For continuous outcomes observable before and after treatment, we incorporated a specific prediction condition. We prioritized treatments that could yield optimal treatment effect results and lead to post-treatment outcomes more desirable than pretreatment levels, with the latter condition being called the prediction criterion. With these considerations, we propose a comprehensive methodology for multitreatment selection. Our approach ensures satisfaction of the overlap assumption, crucial for comparing outcomes for treated and control groups, by training propensity score models as a preliminary step before employing traditional causal models. To illustrate a practical application of our methodology, we applied it to the credit card limit adjustment problem. Analyzing a fintech company's historical data, we found that relying solely on counterfactual predictions was inadequate for appropriate credit line modifications. Incorporating our proposed additional criteria significantly enhanced policy performance.
Optimizing Credit Limit Adjustments Under Adversarial Goals Using Reinforcement Learning
Jun 27, 2023Reinforcement learning has been explored for many problems, from video games with deterministic environments to portfolio and operations management in which scenarios are stochastic; however, there have been few attempts to test these methods in banking problems. In this study, we sought to find and automatize an optimal credit card limit adjustment policy by employing reinforcement learning techniques. In particular, because of the historical data available, we considered two possible actions per customer, namely increasing or maintaining an individual's current credit limit. To find this policy, we first formulated this decision-making question as an optimization problem in which the expected profit was maximized; therefore, we balanced two adversarial goals: maximizing the portfolio's revenue and minimizing the portfolio's provisions. Second, given the particularities of our problem, we used an offline learning strategy to simulate the impact of the action based on historical data from a super-app (i.e., a mobile application that offers various services from goods deliveries to financial products) in Latin America to train our reinforcement learning agent. Our results show that a Double Q-learning agent with optimized hyperparameters can outperform other strategies and generate a non-trivial optimal policy reflecting the complex nature of this decision. Our research not only establishes a conceptual structure for applying reinforcement learning framework to credit limit adjustment, presenting an objective technique to make these decisions primarily based on data-driven methods rather than relying only on expert-driven systems but also provides insights into the effect of alternative data usage for determining these modifications.