 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPARSEFIT: Few-shot Prompting with Sparse Fine-tuning for Jointly Generating Predictions and Natural Language Explanations
May 23, 2023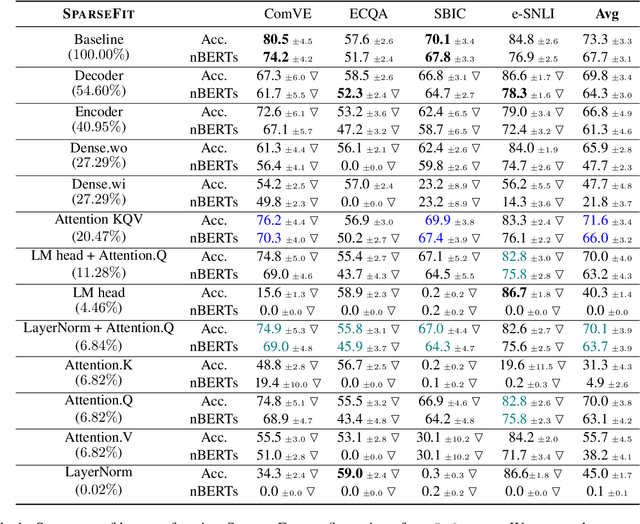
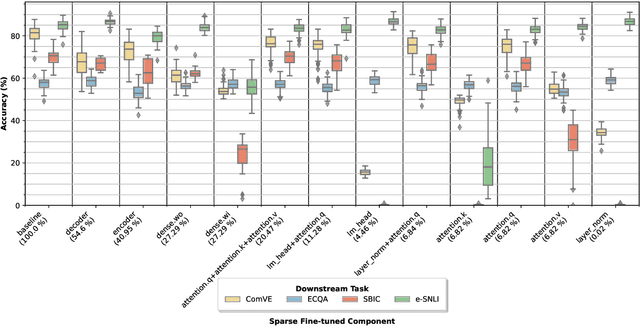
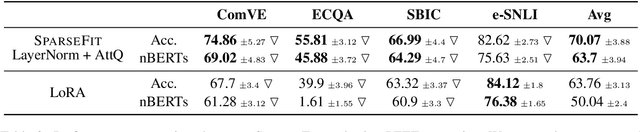
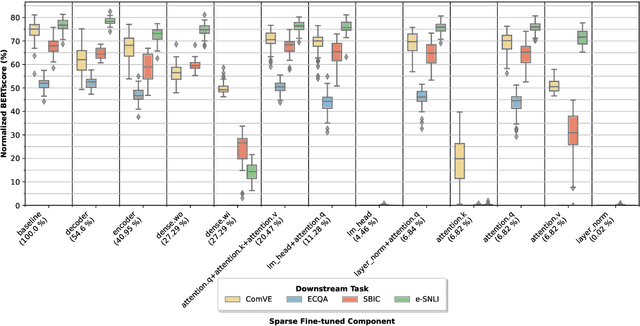
Explaining the decisions of neural models is crucial for ensuring their trustworthiness at deployment time. Using Natural Language Explanations (NLEs) to justify a model's predictions has recently gained increasing interest. However, this approach usually demands large datasets of human-written NLEs for the ground-truth answers, which are expensive and potentially infeasible for some applications. For models to generate high-quality NLEs when only a few NLEs are available, the fine-tuning of Pre-trained Language Models (PLMs) in conjunction with prompt-based learning recently emerged. However, PLMs typically have billions of parameters, making fine-tuning expensive. We propose SparseFit, a sparse few-shot fine-tuning strategy that leverages discrete prompts to jointly generate predictions and NLEs. We experiment with SparseFit on the T5 model and four datasets and compare it against state-of-the-art parameter-efficient fine-tuning techniques. We perform automatic and human evaluations to assess the quality of the model-generated NLEs, finding that fine-tuning only 6.8% of the model parameters leads to competitive results for both the task performance and the quality of the NLEs.
Feature-Level Fusion of Super-App and Telecommunication Alternative Data Sources for Credit Card Fraud Detection
Nov 05, 2021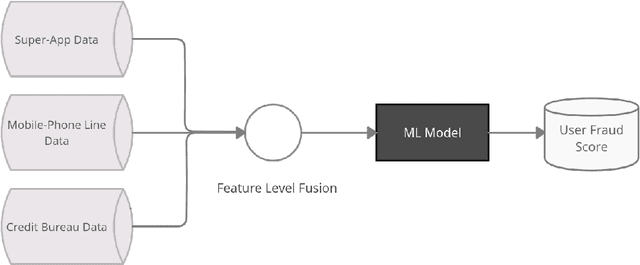
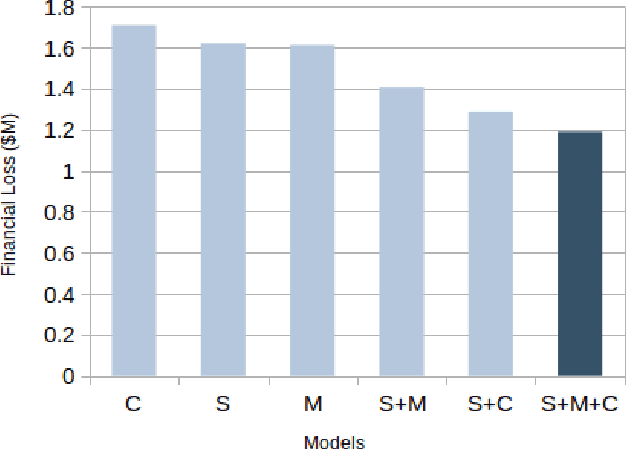
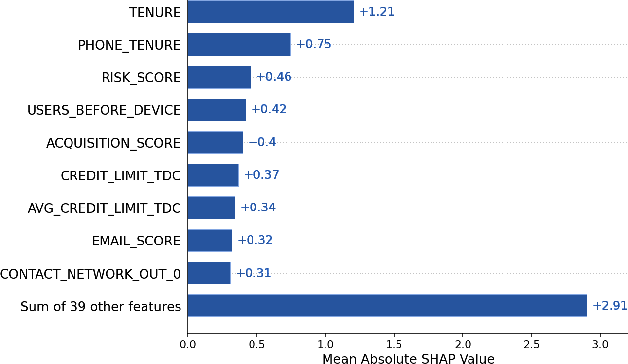

Identity theft is a major problem for credit lenders when there's not enough data to corroborate a customer's identity. Among super-apps large digital platforms that encompass many different services this problem is even more relevant; losing a client in one branch can often mean losing them in other services. In this paper, we review the effectiveness of a feature-level fusion of super-app customer information, mobile phone line data, and traditional credit risk variables for the early detection of identity theft credit card fraud. Through the proposed framework, we achieved better performance when using a model whose input is a fusion of alternative data and traditional credit bureau data, achieving a ROC AUC score of 0.81. We evaluate our approach over approximately 90,000 users from a credit lender's digital platform database. The evaluation was performed using not only traditional ML metrics but the financial costs as well.
FooBaR: Fault Fooling Backdoor Attack on Neural Network Training
Sep 23, 2021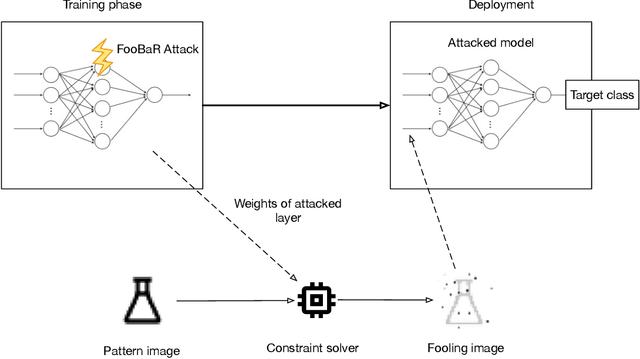
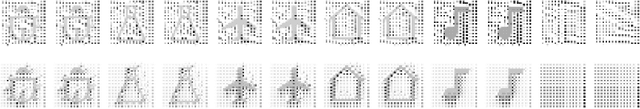
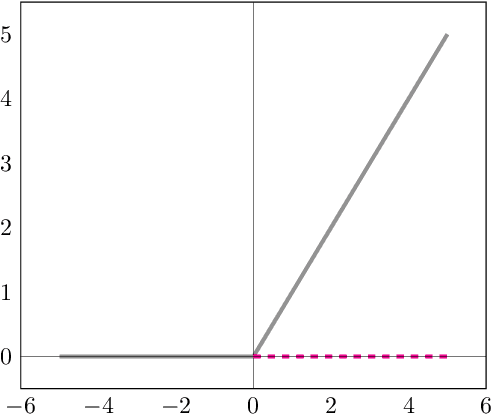
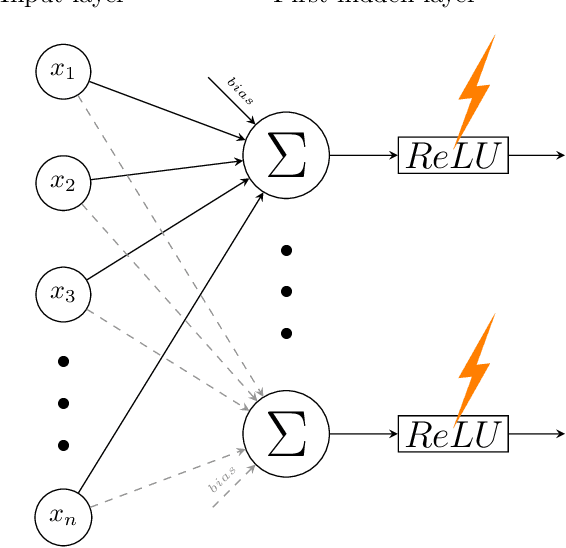
Neural network implementations are known to be vulnerable to physical attack vectors such as fault injection attacks. As of now, these attacks were only utilized during the inference phase with the intention to cause a misclassification. In this work, we explore a novel attack paradigm by injecting faults during the training phase of a neural network in a way that the resulting network can be attacked during deployment without the necessity of further faulting. In particular, we discuss attacks against ReLU activation functions that make it possible to generate a family of malicious inputs, which are called fooling inputs, to be used at inference time to induce controlled misclassifications. Such malicious inputs are obtained by mathematically solving a system of linear equations that would cause a particular behaviour on the attacked activation functions, similar to the one induced in training through faulting. We call such attacks fooling backdoors as the fault attacks at the training phase inject backdoors into the network that allow an attacker to produce fooling inputs. We evaluate our approach against multi-layer perceptron networks and convolutional networks on a popular image classification task obtaining high attack success rates (from 60% to 100%) and high classification confidence when as little as 25 neurons are attacked while preserving high accuracy on the originally intended classification task.