 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond TVLA: Anderson-Darling Leakage Assessment for Neural Network Side-Channel Leakage Detection
Mar 19, 2026Test Vector Leakage Assessment (TVLA) based on Welch's $t$-test has become a standard tool for detecting side-channel leakage. However, its mean-based nature can limit sensitivity when leakage manifests primarily through higher-order distributional differences. As our experiments show, this property becomes especially crucial when it comes to evaluating neural network implementations. In this work, we propose Anderson--Darling Leakage Assessment (ADLA), a leakage detection framework that applies the two-sample Anderson--Darling test for leakage detection. Unlike TVLA, ADLA tests equality of the full cumulative distribution functions and does not rely on a purely mean-shift model. We evaluate ADLA on a multilayer perceptron (MLP) trained on MNIST and implemented on a ChipWhisperer-Husky evaluation platform. We consider protected implementations employing shuffling and random jitter countermeasures. Our results show that ADLA can provide improved leakage-detection sensitivity in protected implementations for a low number of traces compared to TVLA.
The Weight of a Bit: EMFI Sensitivity Analysis of Embedded Deep Learning Models
Feb 18, 2026Fault injection attacks on embedded neural network models have been shown as a potent threat. Numerous works studied resilience of models from various points of view. As of now, there is no comprehensive study that would evaluate the influence of number representations used for model parameters against electromagnetic fault injection (EMFI) attacks. In this paper, we investigate how four different number representations influence the success of an EMFI attack on embedded neural network models. We chose two common floating-point representations (32-bit, and 16-bit), and two integer representations (8-bit, and 4-bit). We deployed four common image classifiers, ResNet-18, ResNet-34, ResNet-50, and VGG-11, on an embedded memory chip, and utilized a low-cost EMFI platform to trigger faults. Our results show that while floating-point representations exhibit almost a complete degradation in accuracy (Top-1 and Top-5) after a single fault injection, integer representations offer better resistance overall. Especially, when considering the the 8-bit representation on a relatively large network (VGG-11), the Top-1 accuracies stay at around 70% and the Top-5 at around 90%.
MCCD: Multi-Agent Collaboration-based Compositional Diffusion for Complex Text-to-Image Generation
May 05, 2025Diffusion models have shown excellent performance in text-to-image generation. Nevertheless, existing methods often suffer from performance bottlenecks when handling complex prompts that involve multiple objects, characteristics, and relations. Therefore, we propose a Multi-agent Collaboration-based Compositional Diffusion (MCCD) for text-to-image generation for complex scenes. Specifically, we design a multi-agent collaboration-based scene parsing module that generates an agent system comprising multiple agents with distinct tasks, utilizing MLLMs to extract various scene elements effectively. In addition, Hierarchical Compositional diffusion utilizes a Gaussian mask and filtering to refine bounding box regions and enhance objects through region enhancement, resulting in the accurate and high-fidelity generation of complex scenes. Comprehensive experiments demonstrate that our MCCD significantly improves the performance of the baseline models in a training-free manner, providing a substantial advantage in complex scene generation.
Make Shuffling Great Again: A Side-Channel Resistant Fisher-Yates Algorithm for Protecting Neural Networks
Jan 01, 2025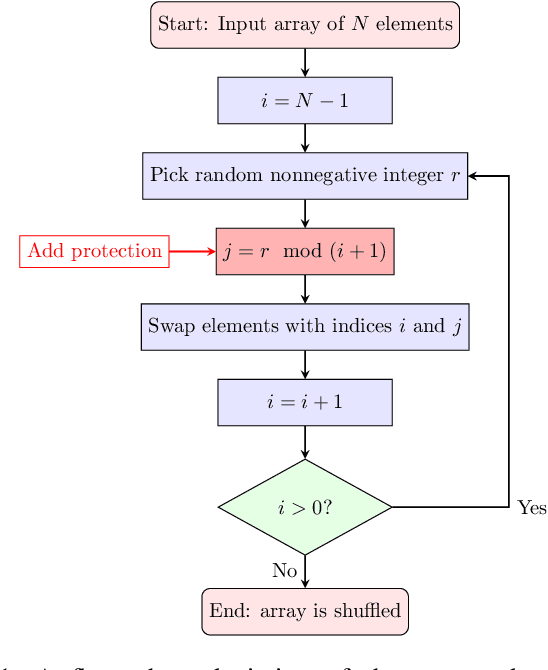
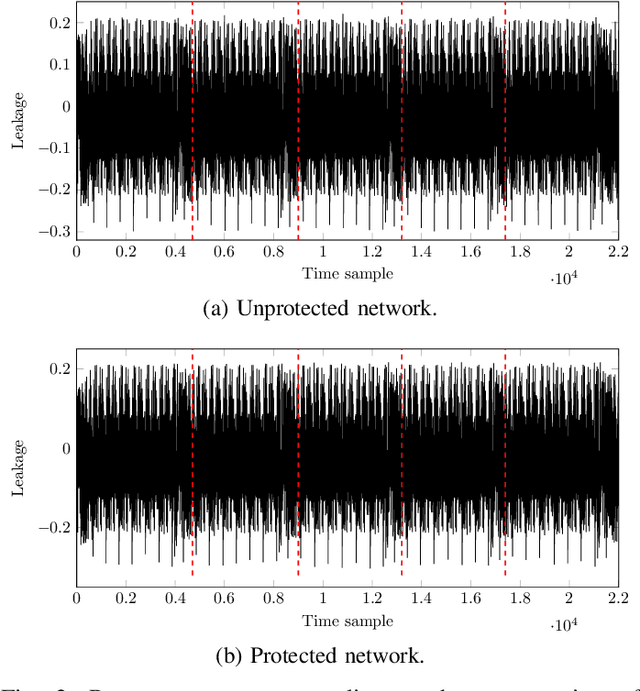
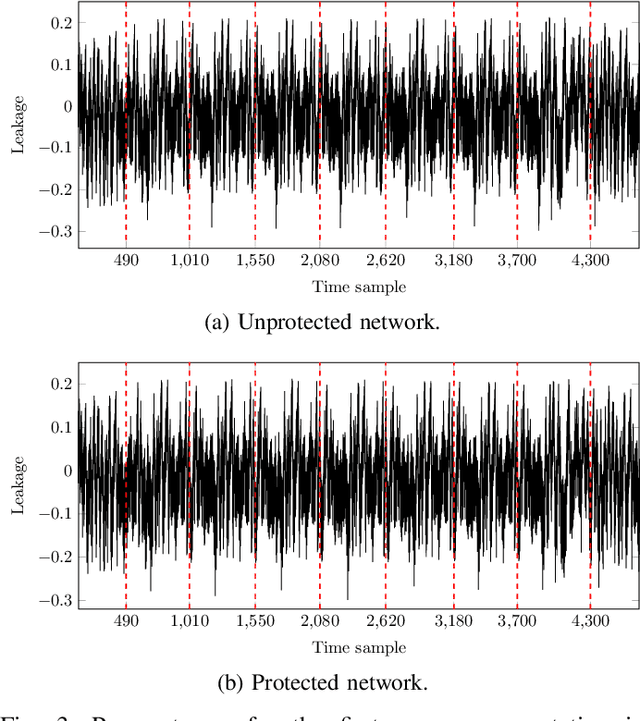
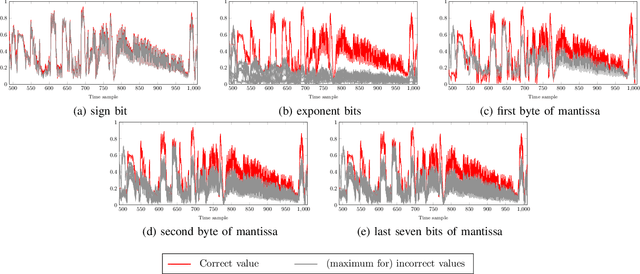
Neural network models implemented in embedded devices have been shown to be susceptible to side-channel attacks (SCAs), allowing recovery of proprietary model parameters, such as weights and biases. There are already available countermeasure methods currently used for protecting cryptographic implementations that can be tailored to protect embedded neural network models. Shuffling, a hiding-based countermeasure that randomly shuffles the order of computations, was shown to be vulnerable to SCA when the Fisher-Yates algorithm is used. In this paper, we propose a design of an SCA-secure version of the Fisher-Yates algorithm. By integrating the masking technique for modular reduction and Blakely's method for modular multiplication, we effectively remove the vulnerability in the division operation that led to side-channel leakage in the original version of the algorithm. We experimentally evaluate that the countermeasure is effective against SCA by implementing a correlation power analysis attack on an embedded neural network model implemented on ARM Cortex-M4. Compared to the original proposal, the memory overhead is $2\times$ the biggest layer of the network, while the time overhead varies from $4\%$ to $0.49\%$ for a layer with $100$ and $1000$ neurons, respectively.
Toward Robust Incomplete Multimodal Sentiment Analysis via Hierarchical Representation Learning
Nov 05, 2024



Multimodal Sentiment Analysis (MSA) is an important research area that aims to understand and recognize human sentiment through multiple modalities. The complementary information provided by multimodal fusion promotes better sentiment analysis compared to utilizing only a single modality. Nevertheless, in real-world applications, many unavoidable factors may lead to situations of uncertain modality missing, thus hindering the effectiveness of multimodal modeling and degrading the model's performance. To this end, we propose a Hierarchical Representation Learning Framework (HRLF) for the MSA task under uncertain missing modalities. Specifically, we propose a fine-grained representation factorization module that sufficiently extracts valuable sentiment information by factorizing modality into sentiment-relevant and modality-specific representations through crossmodal translation and sentiment semantic reconstruction. Moreover, a hierarchical mutual information maximization mechanism is introduced to incrementally maximize the mutual information between multi-scale representations to align and reconstruct the high-level semantics in the representations. Ultimately, we propose a hierarchical adversarial learning mechanism that further aligns and adapts the latent distribution of sentiment-relevant representations to produce robust joint multimodal representations. Comprehensive experiments on three datasets demonstrate that HRLF significantly improves MSA performance under uncertain modality missing cases.
MedAide: Towards an Omni Medical Aide via Specialized LLM-based Multi-Agent Collaboration
Oct 17, 2024

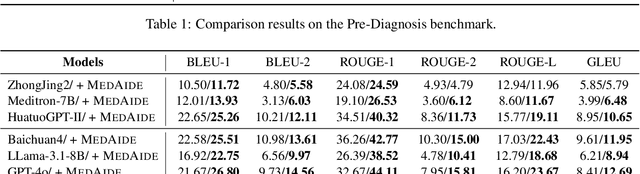

Large Language Model (LLM)-driven interactive systems currently show potential promise in healthcare domains. Despite their remarkable capabilities, LLMs typically lack personalized recommendations and diagnosis analysis in sophisticated medical applications, causing hallucinations and performance bottlenecks. To address these challenges, this paper proposes MedAide, an LLM-based omni medical multi-agent collaboration framework for specialized healthcare services. Specifically, MedAide first performs query rewriting through retrieval-augmented generation to accomplish accurate medical intent understanding. Immediately, we devise a contextual encoder to obtain intent prototype embeddings, which are used to recognize fine-grained intents by similarity matching. According to the intent relevance, the activated agents collaborate effectively to provide integrated decision analysis. Extensive experiments are conducted on four medical benchmarks with composite intents. Experimental results from automated metrics and expert doctor evaluations show that MedAide outperforms current LLMs and improves their medical proficiency and strategic reasoning.
Side-Channel Analysis of OpenVINO-based Neural Network Models
Jul 23, 2024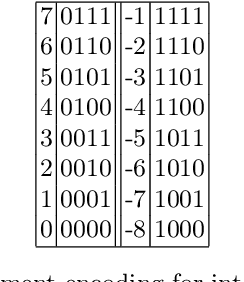
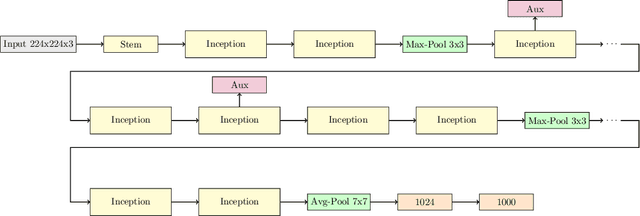

Embedded devices with neural network accelerators offer great versatility for their users, reducing the need to use cloud-based services. At the same time, they introduce new security challenges in the area of hardware attacks, the most prominent being side-channel analysis (SCA). It was shown that SCA can recover model parameters with a high accuracy, posing a threat to entities that wish to keep their models confidential. In this paper, we explore the susceptibility of quantized models implemented in OpenVINO, an embedded framework for deploying neural networks on embedded and Edge devices. We show that it is possible to recover model parameters with high precision, allowing the recovered model to perform very close to the original one. Our experiments on GoogleNet v1 show only a 1% difference in the Top 1 and a 0.64% difference in the Top 5 accuracies.
Detecting and Evaluating Medical Hallucinations in Large Vision Language Models
Jun 14, 2024



Large Vision Language Models (LVLMs) are increasingly integral to healthcare applications, including medical visual question answering and imaging report generation. While these models inherit the robust capabilities of foundational Large Language Models (LLMs), they also inherit susceptibility to hallucinations-a significant concern in high-stakes medical contexts where the margin for error is minimal. However, currently, there are no dedicated methods or benchmarks for hallucination detection and evaluation in the medical field. To bridge this gap, we introduce Med-HallMark, the first benchmark specifically designed for hallucination detection and evaluation within the medical multimodal domain. This benchmark provides multi-tasking hallucination support, multifaceted hallucination data, and hierarchical hallucination categorization. Furthermore, we propose the MediHall Score, a new medical evaluative metric designed to assess LVLMs' hallucinations through a hierarchical scoring system that considers the severity and type of hallucination, thereby enabling a granular assessment of potential clinical impacts. We also present MediHallDetector, a novel Medical LVLM engineered for precise hallucination detection, which employs multitask training for hallucination detection. Through extensive experimental evaluations, we establish baselines for popular LVLMs using our benchmark. The findings indicate that MediHall Score provides a more nuanced understanding of hallucination impacts compared to traditional metrics and demonstrate the enhanced performance of MediHallDetector. We hope this work can significantly improve the reliability of LVLMs in medical applications. All resources of this work will be released soon.
DeepNcode: Encoding-Based Protection against Bit-Flip Attacks on Neural Networks
May 22, 2024Fault injection attacks are a potent threat against embedded implementations of neural network models. Several attack vectors have been proposed, such as misclassification, model extraction, and trojan/backdoor planting. Most of these attacks work by flipping bits in the memory where quantized model parameters are stored. In this paper, we introduce an encoding-based protection method against bit-flip attacks on neural networks, titled DeepNcode. We experimentally evaluate our proposal with several publicly available models and datasets, by using state-of-the-art bit-flip attacks: BFA, T-BFA, and TA-LBF. Our results show an increase in protection margin of up to $7.6\times$ for $4-$bit and $12.4\times$ for $8-$bit quantized networks. Memory overheads start at $50\%$ of the original network size, while the time overheads are negligible. Moreover, DeepNcode does not require retraining and does not change the original accuracy of the model.
Efficiency in Focus: LayerNorm as a Catalyst for Fine-tuning Medical Visual Language Pre-trained Models
Apr 25, 2024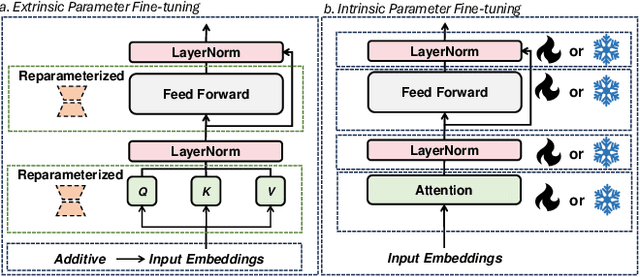
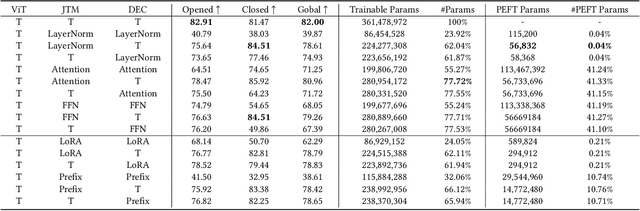
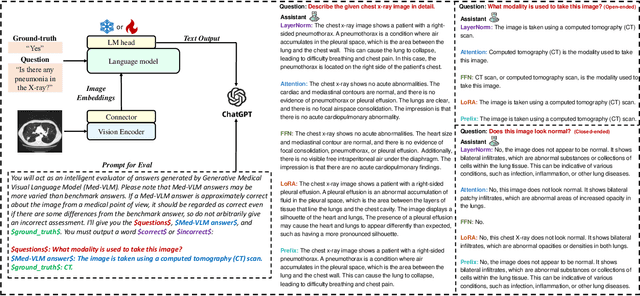
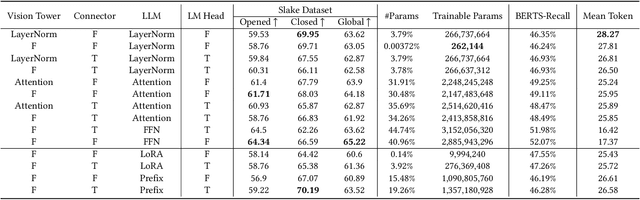
In the realm of Medical Visual Language Models (Med-VLMs), the quest for universal efficient fine-tuning mechanisms remains paramount, especially given researchers in interdisciplinary fields are often extremely short of training resources, yet largely unexplored. Given the unique challenges in the medical domain, such as limited data scope and significant domain-specific requirements, evaluating and adapting Parameter-Efficient Fine-Tuning (PEFT) methods specifically for Med-VLMs is essential. Most of the current PEFT methods on Med-VLMs have yet to be comprehensively investigated but mainly focus on adding some components to the model's structure or input. However, fine-tuning intrinsic model components often yields better generality and consistency, and its impact on the ultimate performance of Med-VLMs has been widely overlooked and remains understudied. In this paper, we endeavour to explore an alternative to traditional PEFT methods, especially the impact of fine-tuning LayerNorm layers, FFNs and Attention layers on the Med-VLMs. Our comprehensive studies span both small-scale and large-scale Med-VLMs, evaluating their performance under various fine-tuning paradigms across tasks such as Medical Visual Question Answering and Medical Imaging Report Generation. The findings reveal unique insights into the effects of intrinsic parameter fine-tuning methods on fine-tuning Med-VLMs to downstream tasks and expose fine-tuning solely the LayerNorm layers not only surpasses the efficiency of traditional PEFT methods but also retains the model's accuracy and generalization capabilities across a spectrum of medical downstream tasks. The experiments show LayerNorm fine-tuning's superior adaptability and scalability, particularly in the context of large-scale Med-VLMs.