 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFysicsWorld: A Unified Full-Modality Benchmark for Any-to-Any Understanding, Generation, and Reasoning
Dec 14, 2025Despite rapid progress in multimodal large language models (MLLMs) and emerging omni-modal architectures, current benchmarks remain limited in scope and integration, suffering from incomplete modality coverage, restricted interaction to text-centric outputs, and weak interdependence and complementarity among modalities. To bridge these gaps, we introduce FysicsWorld, the first unified full-modality benchmark that supports bidirectional input-output across image, video, audio, and text, enabling comprehensive any-to-any evaluation across understanding, generation, and reasoning. FysicsWorld encompasses 16 primary tasks and 3,268 curated samples, aggregated from over 40 high-quality sources and covering a rich set of open-domain categories with diverse question types. We also propose the Cross-Modal Complementarity Screening (CMCS) strategy integrated in a systematic data construction framework that produces omni-modal data for spoken interaction and fusion-dependent cross-modal reasoning. Through a comprehensive evaluation of over 30 state-of-the-art baselines, spanning MLLMs, modality-specific models, unified understanding-generation models, and omni-modal language models, FysicsWorld exposes the performance disparities and limitations across models in understanding, generation, and reasoning. Our benchmark establishes a unified foundation and strong baselines for evaluating and advancing next-generation full-modality architectures.
Improving Multimodal Sentiment Analysis via Modality Optimization and Dynamic Primary Modality Selection
Nov 14, 2025Multimodal Sentiment Analysis (MSA) aims to predict sentiment from language, acoustic, and visual data in videos. However, imbalanced unimodal performance often leads to suboptimal fused representations. Existing approaches typically adopt fixed primary modality strategies to maximize dominant modality advantages, yet fail to adapt to dynamic variations in modality importance across different samples. Moreover, non-language modalities suffer from sequential redundancy and noise, degrading model performance when they serve as primary inputs. To address these issues, this paper proposes a modality optimization and dynamic primary modality selection framework (MODS). First, a Graph-based Dynamic Sequence Compressor (GDC) is constructed, which employs capsule networks and graph convolution to reduce sequential redundancy in acoustic/visual modalities. Then, we develop a sample-adaptive Primary Modality Selector (MSelector) for dynamic dominance determination. Finally, a Primary-modality-Centric Cross-Attention (PCCA) module is designed to enhance dominant modalities while facilitating cross-modal interaction. Extensive experiments on four benchmark datasets demonstrate that MODS outperforms state-of-the-art methods, achieving superior performance by effectively balancing modality contributions and eliminating redundant noise.
PersonaAnimator: Personalized Motion Transfer from Unconstrained Videos
Aug 27, 2025Recent advances in motion generation show remarkable progress. However, several limitations remain: (1) Existing pose-guided character motion transfer methods merely replicate motion without learning its style characteristics, resulting in inexpressive characters. (2) Motion style transfer methods rely heavily on motion capture data, which is difficult to obtain. (3) Generated motions sometimes violate physical laws. To address these challenges, this paper pioneers a new task: Video-to-Video Motion Personalization. We propose a novel framework, PersonaAnimator, which learns personalized motion patterns directly from unconstrained videos. This enables personalized motion transfer. To support this task, we introduce PersonaVid, the first video-based personalized motion dataset. It contains 20 motion content categories and 120 motion style categories. We further propose a Physics-aware Motion Style Regularization mechanism to enforce physical plausibility in the generated motions. Extensive experiments show that PersonaAnimator outperforms state-of-the-art motion transfer methods and sets a new benchmark for the Video-to-Video Motion Personalization task.
COPO: Consistency-Aware Policy Optimization
Aug 06, 2025Reinforcement learning has significantly enhanced the reasoning capabilities of Large Language Models (LLMs) in complex problem-solving tasks. Recently, the introduction of DeepSeek R1 has inspired a surge of interest in leveraging rule-based rewards as a low-cost alternative for computing advantage functions and guiding policy optimization. However, a common challenge observed across many replication and extension efforts is that when multiple sampled responses under a single prompt converge to identical outcomes, whether correct or incorrect, the group-based advantage degenerates to zero. This leads to vanishing gradients and renders the corresponding samples ineffective for learning, ultimately limiting training efficiency and downstream performance. To address this issue, we propose a consistency-aware policy optimization framework that introduces a structured global reward based on outcome consistency, the global loss based on it ensures that, even when model outputs show high intra-group consistency, the training process still receives meaningful learning signals, which encourages the generation of correct and self-consistent reasoning paths from a global perspective. Furthermore, we incorporate an entropy-based soft blending mechanism that adaptively balances local advantage estimation with global optimization, enabling dynamic transitions between exploration and convergence throughout training. Our method introduces several key innovations in both reward design and optimization strategy. We validate its effectiveness through substantial performance gains on multiple mathematical reasoning benchmarks, highlighting the proposed framework's robustness and general applicability. Code of this work has been released at https://github.com/hijih/copo-code.git.
MCCD: Multi-Agent Collaboration-based Compositional Diffusion for Complex Text-to-Image Generation
May 05, 2025Diffusion models have shown excellent performance in text-to-image generation. Nevertheless, existing methods often suffer from performance bottlenecks when handling complex prompts that involve multiple objects, characteristics, and relations. Therefore, we propose a Multi-agent Collaboration-based Compositional Diffusion (MCCD) for text-to-image generation for complex scenes. Specifically, we design a multi-agent collaboration-based scene parsing module that generates an agent system comprising multiple agents with distinct tasks, utilizing MLLMs to extract various scene elements effectively. In addition, Hierarchical Compositional diffusion utilizes a Gaussian mask and filtering to refine bounding box regions and enhance objects through region enhancement, resulting in the accurate and high-fidelity generation of complex scenes. Comprehensive experiments demonstrate that our MCCD significantly improves the performance of the baseline models in a training-free manner, providing a substantial advantage in complex scene generation.
Toward Robust Incomplete Multimodal Sentiment Analysis via Hierarchical Representation Learning
Nov 05, 2024



Multimodal Sentiment Analysis (MSA) is an important research area that aims to understand and recognize human sentiment through multiple modalities. The complementary information provided by multimodal fusion promotes better sentiment analysis compared to utilizing only a single modality. Nevertheless, in real-world applications, many unavoidable factors may lead to situations of uncertain modality missing, thus hindering the effectiveness of multimodal modeling and degrading the model's performance. To this end, we propose a Hierarchical Representation Learning Framework (HRLF) for the MSA task under uncertain missing modalities. Specifically, we propose a fine-grained representation factorization module that sufficiently extracts valuable sentiment information by factorizing modality into sentiment-relevant and modality-specific representations through crossmodal translation and sentiment semantic reconstruction. Moreover, a hierarchical mutual information maximization mechanism is introduced to incrementally maximize the mutual information between multi-scale representations to align and reconstruct the high-level semantics in the representations. Ultimately, we propose a hierarchical adversarial learning mechanism that further aligns and adapts the latent distribution of sentiment-relevant representations to produce robust joint multimodal representations. Comprehensive experiments on three datasets demonstrate that HRLF significantly improves MSA performance under uncertain modality missing cases.
MedAide: Towards an Omni Medical Aide via Specialized LLM-based Multi-Agent Collaboration
Oct 17, 2024

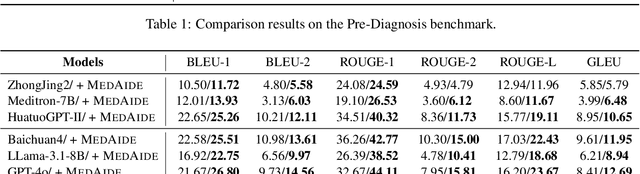

Large Language Model (LLM)-driven interactive systems currently show potential promise in healthcare domains. Despite their remarkable capabilities, LLMs typically lack personalized recommendations and diagnosis analysis in sophisticated medical applications, causing hallucinations and performance bottlenecks. To address these challenges, this paper proposes MedAide, an LLM-based omni medical multi-agent collaboration framework for specialized healthcare services. Specifically, MedAide first performs query rewriting through retrieval-augmented generation to accomplish accurate medical intent understanding. Immediately, we devise a contextual encoder to obtain intent prototype embeddings, which are used to recognize fine-grained intents by similarity matching. According to the intent relevance, the activated agents collaborate effectively to provide integrated decision analysis. Extensive experiments are conducted on four medical benchmarks with composite intents. Experimental results from automated metrics and expert doctor evaluations show that MedAide outperforms current LLMs and improves their medical proficiency and strategic reasoning.
Improving Factuality in Large Language Models via Decoding-Time Hallucinatory and Truthful Comparators
Aug 22, 2024



Despite their remarkable capabilities, Large Language Models (LLMs) are prone to generate responses that contradict verifiable facts, i.e., unfaithful hallucination content. Existing efforts generally focus on optimizing model parameters or editing semantic representations, which compromise the internal factual knowledge of target LLMs. In addition, hallucinations typically exhibit multifaceted patterns in downstream tasks, limiting the model's holistic performance across tasks. In this paper, we propose a Comparator-driven Decoding-Time (CDT) framework to alleviate the response hallucination. Firstly, we construct hallucinatory and truthful comparators with multi-task fine-tuning samples. In this case, we present an instruction prototype-guided mixture of experts strategy to enhance the ability of the corresponding comparators to capture different hallucination or truthfulness patterns in distinct task instructions. CDT constrains next-token predictions to factuality-robust distributions by contrasting the logit differences between the target LLMs and these comparators. Systematic experiments on multiple downstream tasks show that our framework can significantly improve the model performance and response factuality.
MaskBEV: Towards A Unified Framework for BEV Detection and Map Segmentation
Aug 17, 2024
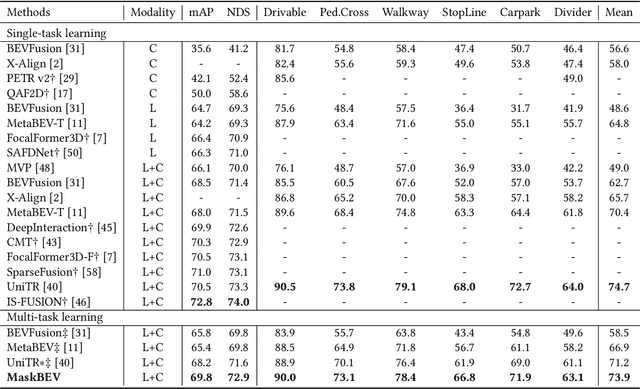

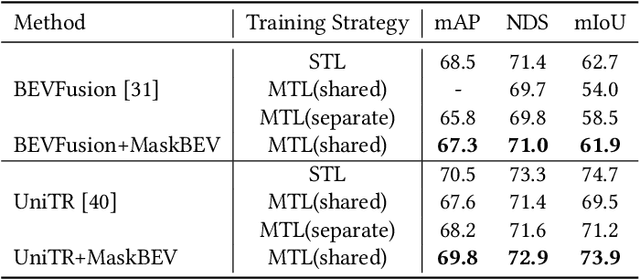
Accurate and robust multimodal multi-task perception is crucial for modern autonomous driving systems. However, current multimodal perception research follows independent paradigms designed for specific perception tasks, leading to a lack of complementary learning among tasks and decreased performance in multi-task learning (MTL) due to joint training. In this paper, we propose MaskBEV, a masked attention-based MTL paradigm that unifies 3D object detection and bird's eye view (BEV) map segmentation. MaskBEV introduces a task-agnostic Transformer decoder to process these diverse tasks, enabling MTL to be completed in a unified decoder without requiring additional design of specific task heads. To fully exploit the complementary information between BEV map segmentation and 3D object detection tasks in BEV space, we propose spatial modulation and scene-level context aggregation strategies. These strategies consider the inherent dependencies between BEV segmentation and 3D detection, naturally boosting MTL performance. Extensive experiments on nuScenes dataset show that compared with previous state-of-the-art MTL methods, MaskBEV achieves 1.3 NDS improvement in 3D object detection and 2.7 mIoU improvement in BEV map segmentation, while also demonstrating slightly leading inference speed.
HybridOcc: NeRF Enhanced Transformer-based Multi-Camera 3D Occupancy Prediction
Aug 17, 2024



Vision-based 3D semantic scene completion (SSC) describes autonomous driving scenes through 3D volume representations. However, the occlusion of invisible voxels by scene surfaces poses challenges to current SSC methods in hallucinating refined 3D geometry. This paper proposes HybridOcc, a hybrid 3D volume query proposal method generated by Transformer framework and NeRF representation and refined in a coarse-to-fine SSC prediction framework. HybridOcc aggregates contextual features through the Transformer paradigm based on hybrid query proposals while combining it with NeRF representation to obtain depth supervision. The Transformer branch contains multiple scales and uses spatial cross-attention for 2D to 3D transformation. The newly designed NeRF branch implicitly infers scene occupancy through volume rendering, including visible and invisible voxels, and explicitly captures scene depth rather than generating RGB color. Furthermore, we present an innovative occupancy-aware ray sampling method to orient the SSC task instead of focusing on the scene surface, further improving the overall performance. Extensive experiments on nuScenes and SemanticKITTI datasets demonstrate the effectiveness of our HybridOcc on the SSC task.