 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaskBEV: Towards A Unified Framework for BEV Detection and Map Segmentation
Paper and Code
Aug 17, 2024
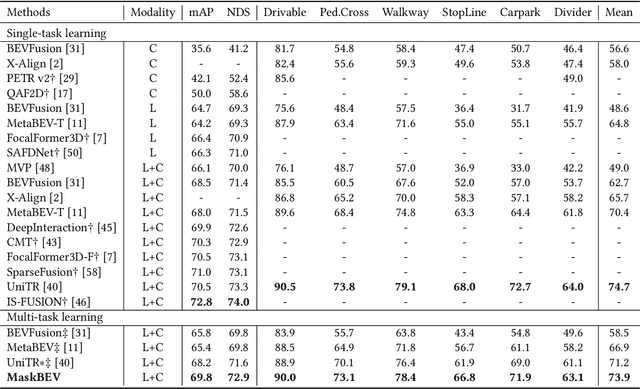

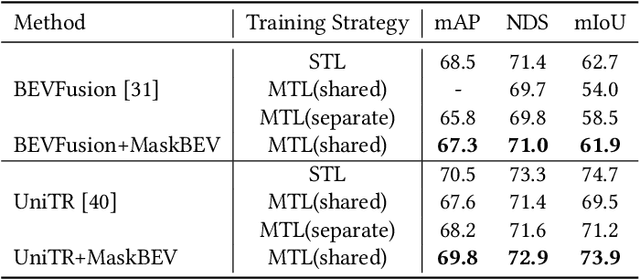
Accurate and robust multimodal multi-task perception is crucial for modern autonomous driving systems. However, current multimodal perception research follows independent paradigms designed for specific perception tasks, leading to a lack of complementary learning among tasks and decreased performance in multi-task learning (MTL) due to joint training. In this paper, we propose MaskBEV, a masked attention-based MTL paradigm that unifies 3D object detection and bird's eye view (BEV) map segmentation. MaskBEV introduces a task-agnostic Transformer decoder to process these diverse tasks, enabling MTL to be completed in a unified decoder without requiring additional design of specific task heads. To fully exploit the complementary information between BEV map segmentation and 3D object detection tasks in BEV space, we propose spatial modulation and scene-level context aggregation strategies. These strategies consider the inherent dependencies between BEV segmentation and 3D detection, naturally boosting MTL performance. Extensive experiments on nuScenes dataset show that compared with previous state-of-the-art MTL methods, MaskBEV achieves 1.3 NDS improvement in 3D object detection and 2.7 mIoU improvement in BEV map segmentation, while also demonstrating slightly leading inference speed.