 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonaAnimator: Personalized Motion Transfer from Unconstrained Videos
Aug 27, 2025Recent advances in motion generation show remarkable progress. However, several limitations remain: (1) Existing pose-guided character motion transfer methods merely replicate motion without learning its style characteristics, resulting in inexpressive characters. (2) Motion style transfer methods rely heavily on motion capture data, which is difficult to obtain. (3) Generated motions sometimes violate physical laws. To address these challenges, this paper pioneers a new task: Video-to-Video Motion Personalization. We propose a novel framework, PersonaAnimator, which learns personalized motion patterns directly from unconstrained videos. This enables personalized motion transfer. To support this task, we introduce PersonaVid, the first video-based personalized motion dataset. It contains 20 motion content categories and 120 motion style categories. We further propose a Physics-aware Motion Style Regularization mechanism to enforce physical plausibility in the generated motions. Extensive experiments show that PersonaAnimator outperforms state-of-the-art motion transfer methods and sets a new benchmark for the Video-to-Video Motion Personalization task.
Toward Robust Incomplete Multimodal Sentiment Analysis via Hierarchical Representation Learning
Nov 05, 2024



Multimodal Sentiment Analysis (MSA) is an important research area that aims to understand and recognize human sentiment through multiple modalities. The complementary information provided by multimodal fusion promotes better sentiment analysis compared to utilizing only a single modality. Nevertheless, in real-world applications, many unavoidable factors may lead to situations of uncertain modality missing, thus hindering the effectiveness of multimodal modeling and degrading the model's performance. To this end, we propose a Hierarchical Representation Learning Framework (HRLF) for the MSA task under uncertain missing modalities. Specifically, we propose a fine-grained representation factorization module that sufficiently extracts valuable sentiment information by factorizing modality into sentiment-relevant and modality-specific representations through crossmodal translation and sentiment semantic reconstruction. Moreover, a hierarchical mutual information maximization mechanism is introduced to incrementally maximize the mutual information between multi-scale representations to align and reconstruct the high-level semantics in the representations. Ultimately, we propose a hierarchical adversarial learning mechanism that further aligns and adapts the latent distribution of sentiment-relevant representations to produce robust joint multimodal representations. Comprehensive experiments on three datasets demonstrate that HRLF significantly improves MSA performance under uncertain modality missing cases.
HybridOcc: NeRF Enhanced Transformer-based Multi-Camera 3D Occupancy Prediction
Aug 17, 2024



Vision-based 3D semantic scene completion (SSC) describes autonomous driving scenes through 3D volume representations. However, the occlusion of invisible voxels by scene surfaces poses challenges to current SSC methods in hallucinating refined 3D geometry. This paper proposes HybridOcc, a hybrid 3D volume query proposal method generated by Transformer framework and NeRF representation and refined in a coarse-to-fine SSC prediction framework. HybridOcc aggregates contextual features through the Transformer paradigm based on hybrid query proposals while combining it with NeRF representation to obtain depth supervision. The Transformer branch contains multiple scales and uses spatial cross-attention for 2D to 3D transformation. The newly designed NeRF branch implicitly infers scene occupancy through volume rendering, including visible and invisible voxels, and explicitly captures scene depth rather than generating RGB color. Furthermore, we present an innovative occupancy-aware ray sampling method to orient the SSC task instead of focusing on the scene surface, further improving the overall performance. Extensive experiments on nuScenes and SemanticKITTI datasets demonstrate the effectiveness of our HybridOcc on the SSC task.
SMCD: High Realism Motion Style Transfer via Mamba-based Diffusion
May 05, 2024



Motion style transfer is a significant research direction in multimedia applications. It enables the rapid switching of different styles of the same motion for virtual digital humans, thus vastly increasing the diversity and realism of movements. It is widely applied in multimedia scenarios such as movies, games, and the Metaverse. However, most of the current work in this field adopts the GAN, which may lead to instability and convergence issues, making the final generated motion sequence somewhat chaotic and unable to reflect a highly realistic and natural style. To address these problems, we consider style motion as a condition and propose the Style Motion Conditioned Diffusion (SMCD) framework for the first time, which can more comprehensively learn the style features of motion. Moreover, we apply Mamba model for the first time in the motion style transfer field, introducing the Motion Style Mamba (MSM) module to handle longer motion sequences. Thirdly, aiming at the SMCD framework, we propose Diffusion-based Content Consistency Loss and Content Consistency Loss to assist the overall framework's training. Finally, we conduct extensive experiments. The results reveal that our method surpasses state-of-the-art methods in both qualitative and quantitative comparisons, capable of generating more realistic motion sequences.
Correlation-Decoupled Knowledge Distillation for Multimodal Sentiment Analysis with Incomplete Modalities
Apr 25, 2024



Multimodal sentiment analysis (MSA) aims to understand human sentiment through multimodal data. Most MSA efforts are based on the assumption of modality completeness. However, in real-world applications, some practical factors cause uncertain modality missingness, which drastically degrades the model's performance. To this end, we propose a Correlation-decoupled Knowledge Distillation (CorrKD) framework for the MSA task under uncertain missing modalities. Specifically, we present a sample-level contrastive distillation mechanism that transfers comprehensive knowledge containing cross-sample correlations to reconstruct missing semantics. Moreover, a category-guided prototype distillation mechanism is introduced to capture cross-category correlations using category prototypes to align feature distributions and generate favorable joint representations. Eventually, we design a response-disentangled consistency distillation strategy to optimize the sentiment decision boundaries of the student network through response disentanglement and mutual information maximization. Comprehensive experiments on three datasets indicate that our framework can achieve favorable improvements compared with several baselines.
Human 3D Avatar Modeling with Implicit Neural Representation: A Brief Survey
Jun 06, 2023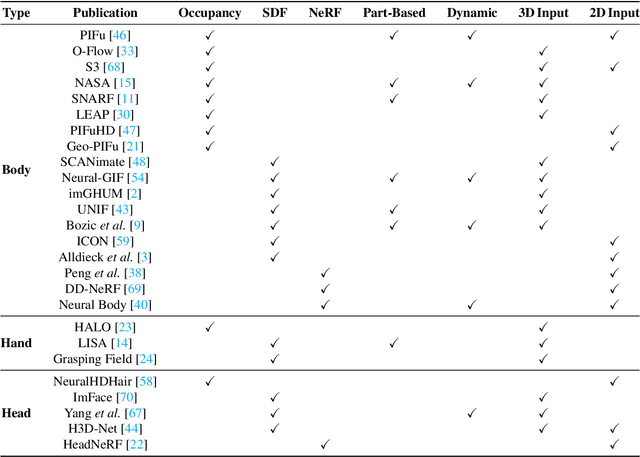
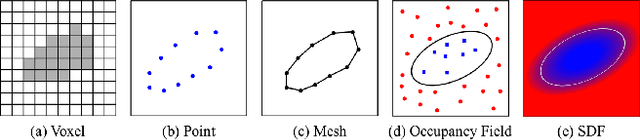
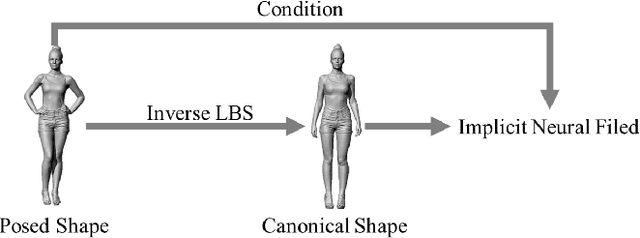
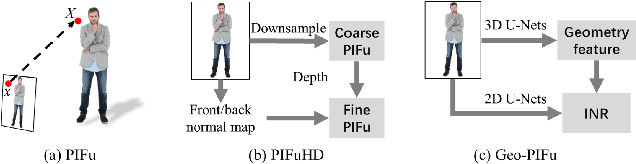
A human 3D avatar is one of the important elements in the metaverse, and the modeling effect directly affects people's visual experience. However, the human body has a complex topology and diverse details, so it is often expensive, time-consuming, and laborious to build a satisfactory model. Recent studies have proposed a novel method, implicit neural representation, which is a continuous representation method and can describe objects with arbitrary topology at arbitrary resolution. Researchers have applied implicit neural representation to human 3D avatar modeling and obtained more excellent results than traditional methods. This paper comprehensively reviews the application of implicit neural representation in human body modeling. First, we introduce three implicit representations of occupancy field, SDF, and NeRF, and make a classification of the literature investigated in this paper. Then the application of implicit modeling methods in the body, hand, and head are compared and analyzed respectively. Finally, we point out the shortcomings of current work and provide available suggestions for researchers.