 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics-Informed Uncertainty Enables Reliable AI-driven Design
Jan 26, 2026Inverse design is a central goal in much of science and engineering, including frequency-selective surfaces (FSS) that are critical to microelectronics for telecommunications and optical metamaterials. Traditional surrogate-assisted optimization methods using deep learning can accelerate the design process but do not usually incorporate uncertainty quantification, leading to poorer optimization performance due to erroneous predictions in data-sparse regions. Here, we introduce and validate a fundamentally different paradigm of Physics-Informed Uncertainty, where the degree to which a model's prediction violates fundamental physical laws serves as a computationally-cheap and effective proxy for predictive uncertainty. By integrating physics-informed uncertainty into a multi-fidelity uncertainty-aware optimization workflow to design complex frequency-selective surfaces within the 20 - 30 GHz range, we increase the success rate of finding performant solutions from less than 10% to over 50%, while simultaneously reducing computational cost by an order of magnitude compared to the sole use of a high-fidelity solver. These results highlight the necessity of incorporating uncertainty quantification in machine-learning-driven inverse design for high-dimensional problems, and establish physics-informed uncertainty as a viable alternative to quantifying uncertainty in surrogate models for physical systems, thereby setting the stage for autonomous scientific discovery systems that can efficiently and robustly explore and evaluate candidate designs.
A Synoptic Review of High-Frequency Oscillations as a Biomarker in Neurodegenerative Disease
Aug 27, 2025High Frequency Oscillations (HFOs), rapid bursts of brain activity above 80 Hz, have emerged as a highly specific biomarker for epileptogenic tissue. Recent evidence suggests that HFOs are also present in Alzheimer's Disease (AD), reflecting underlying network hyperexcitability and offering a promising, noninvasive tool for early diagnosis and disease tracking. This synoptic review provides a comprehensive analysis of publicly available electroencephalography (EEG) datasets relevant to HFO research in neurodegenerative disorders. We conducted a bibliometric analysis of 1,222 articles, revealing a significant and growing research interest in HFOs, particularly within the last ten years. We then systematically profile and compare key public datasets, evaluating their participant cohorts, data acquisition parameters, and accessibility, with a specific focus on their technical suitability for HFO analysis. Our comparative synthesis highlights critical methodological heterogeneity across datasets, particularly in sampling frequency and recording paradigms, which poses challenges for cross-study validation, but also offers opportunities for robustness testing. By consolidating disparate information, clarifying nomenclature, and providing a detailed methodological framework, this review serves as a guide for researchers aiming to leverage public data to advance the role of HFOs as a cross-disease biomarker for AD and related conditions.
Effective Rank and the Staircase Phenomenon: New Insights into Neural Network Training Dynamics
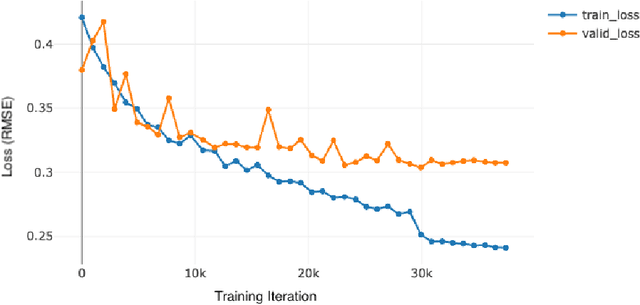
Dec 06, 2024In recent years, deep learning, powered by neural networks, has achieved widespread success in solving high-dimensional problems, particularly those with low-dimensional feature structures. This success stems from their ability to identify and learn low dimensional features tailored to the problems. Understanding how neural networks extract such features during training dynamics remains a fundamental question in deep learning theory. In this work, we propose a novel perspective by interpreting the neurons in the last hidden layer of a neural network as basis functions that represent essential features. To explore the linear independence of these basis functions throughout the deep learning dynamics, we introduce the concept of 'effective rank'. Our extensive numerical experiments reveal a notable phenomenon: the effective rank increases progressively during the learning process, exhibiting a staircase-like pattern, while the loss function concurrently decreases as the effective rank rises. We refer to this observation as the 'staircase phenomenon'. Specifically, for deep neural networks, we rigorously prove the negative correlation between the loss function and effective rank, demonstrating that the lower bound of the loss function decreases with increasing effective rank. Therefore, to achieve a rapid descent of the loss function, it is critical to promote the swift growth of effective rank. Ultimately, we evaluate existing advanced learning methodologies and find that these approaches can quickly achieve a higher effective rank, thereby avoiding redundant staircase processes and accelerating the rapid decline of the loss function.
DiffLight: A Partial Rewards Conditioned Diffusion Model for Traffic Signal Control with Missing Data
Oct 31, 2024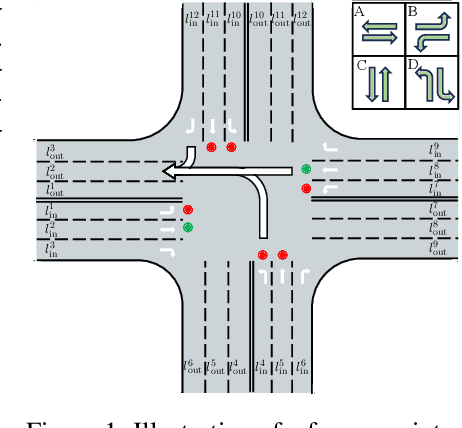
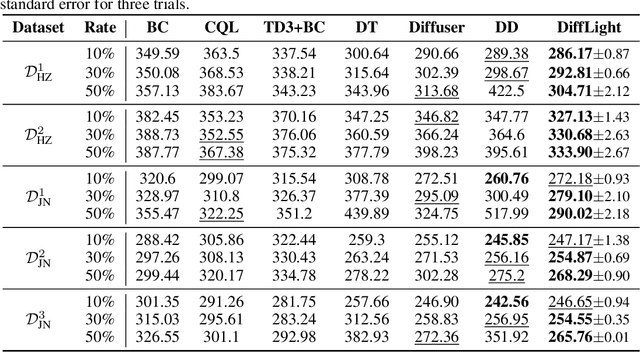
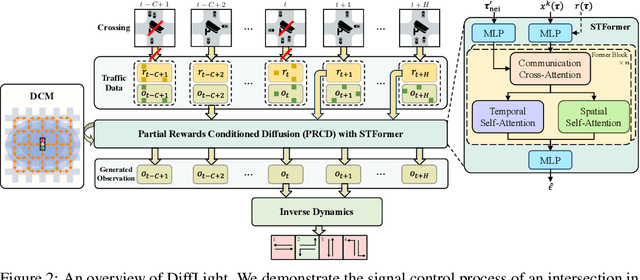
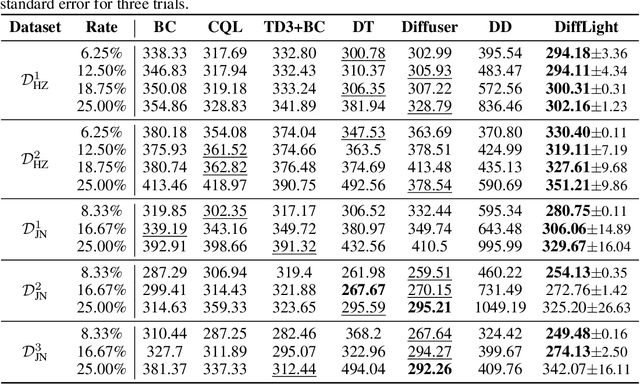
The application of reinforcement learning in traffic signal control (TSC) has been extensively researched and yielded notable achievements. However, most existing works for TSC assume that traffic data from all surrounding intersections is fully and continuously available through sensors. In real-world applications, this assumption often fails due to sensor malfunctions or data loss, making TSC with missing data a critical challenge. To meet the needs of practical applications, we introduce DiffLight, a novel conditional diffusion model for TSC under data-missing scenarios in the offline setting. Specifically, we integrate two essential sub-tasks, i.e., traffic data imputation and decision-making, by leveraging a Partial Rewards Conditioned Diffusion (PRCD) model to prevent missing rewards from interfering with the learning process. Meanwhile, to effectively capture the spatial-temporal dependencies among intersections, we design a Spatial-Temporal transFormer (STFormer) architecture. In addition, we propose a Diffusion Communication Mechanism (DCM) to promote better communication and control performance under data-missing scenarios. Extensive experiments on five datasets with various data-missing scenarios demonstrate that DiffLight is an effective controller to address TSC with missing data. The code of DiffLight is released at https://github.com/lokol5579/DiffLight-release.
Random resistive memory-based deep extreme point learning machine for unified visual processing
Dec 14, 2023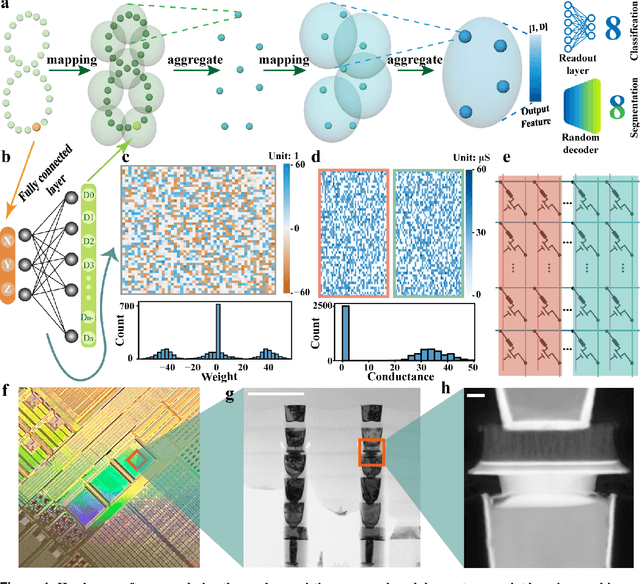
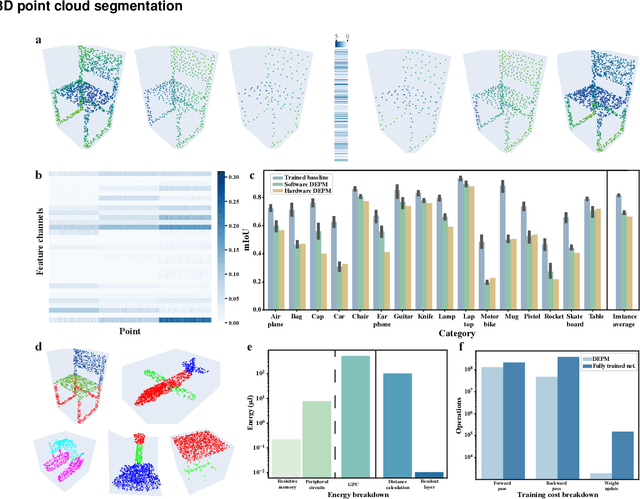
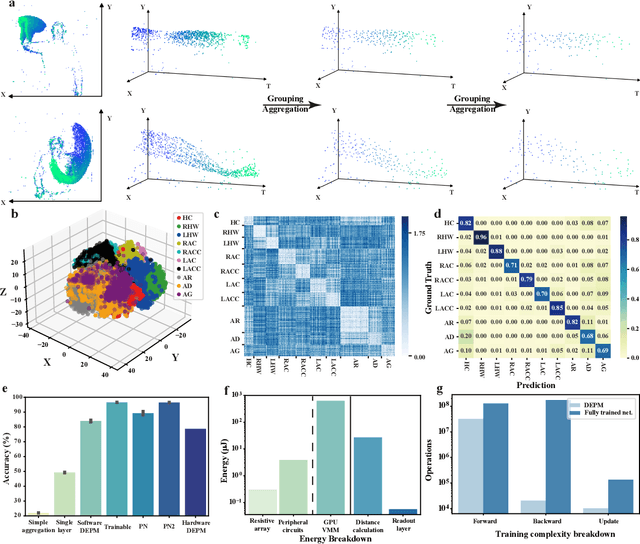
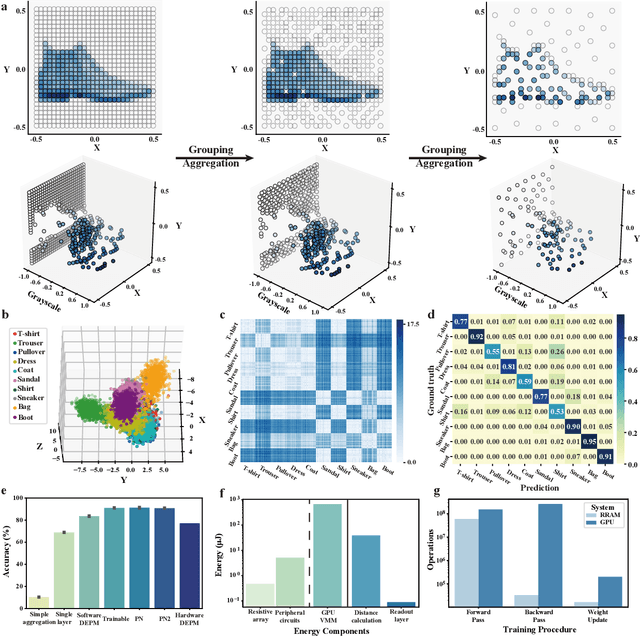
Visual sensors, including 3D LiDAR, neuromorphic DVS sensors, and conventional frame cameras, are increasingly integrated into edge-side intelligent machines. Realizing intensive multi-sensory data analysis directly on edge intelligent machines is crucial for numerous emerging edge applications, such as augmented and virtual reality and unmanned aerial vehicles, which necessitates unified data representation, unprecedented hardware energy efficiency and rapid model training. However, multi-sensory data are intrinsically heterogeneous, causing significant complexity in the system development for edge-side intelligent machines. In addition, the performance of conventional digital hardware is limited by the physically separated processing and memory units, known as the von Neumann bottleneck, and the physical limit of transistor scaling, which contributes to the slowdown of Moore's law. These limitations are further intensified by the tedious training of models with ever-increasing sizes. We propose a novel hardware-software co-design, random resistive memory-based deep extreme point learning machine (DEPLM), that offers efficient unified point set analysis. We show the system's versatility across various data modalities and two different learning tasks. Compared to a conventional digital hardware-based system, our co-design system achieves huge energy efficiency improvements and training cost reduction when compared to conventional systems. Our random resistive memory-based deep extreme point learning machine may pave the way for energy-efficient and training-friendly edge AI across various data modalities and tasks.
Human 3D Avatar Modeling with Implicit Neural Representation: A Brief Survey
Jun 06, 2023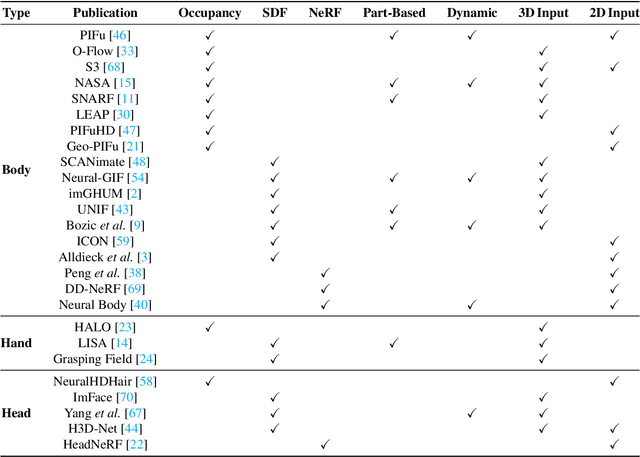
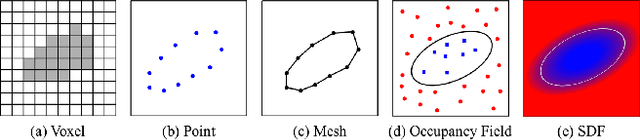
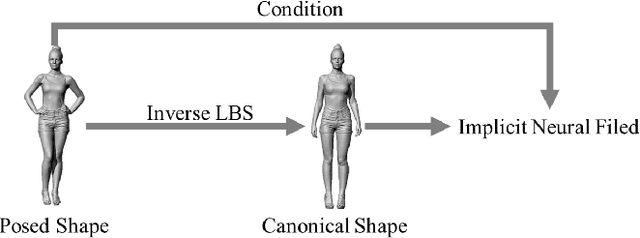
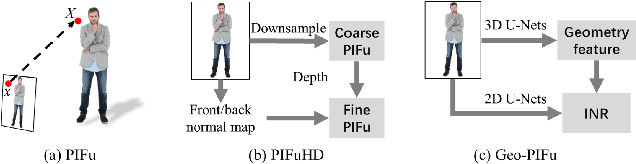
A human 3D avatar is one of the important elements in the metaverse, and the modeling effect directly affects people's visual experience. However, the human body has a complex topology and diverse details, so it is often expensive, time-consuming, and laborious to build a satisfactory model. Recent studies have proposed a novel method, implicit neural representation, which is a continuous representation method and can describe objects with arbitrary topology at arbitrary resolution. Researchers have applied implicit neural representation to human 3D avatar modeling and obtained more excellent results than traditional methods. This paper comprehensively reviews the application of implicit neural representation in human body modeling. First, we introduce three implicit representations of occupancy field, SDF, and NeRF, and make a classification of the literature investigated in this paper. Then the application of implicit modeling methods in the body, hand, and head are compared and analyzed respectively. Finally, we point out the shortcomings of current work and provide available suggestions for researchers.
High-Accuracy Absolute-Position-Aided Code Phase Tracking Based on RTK/INS Deep Integration in Challenging Static Scenarios
Dec 31, 2022

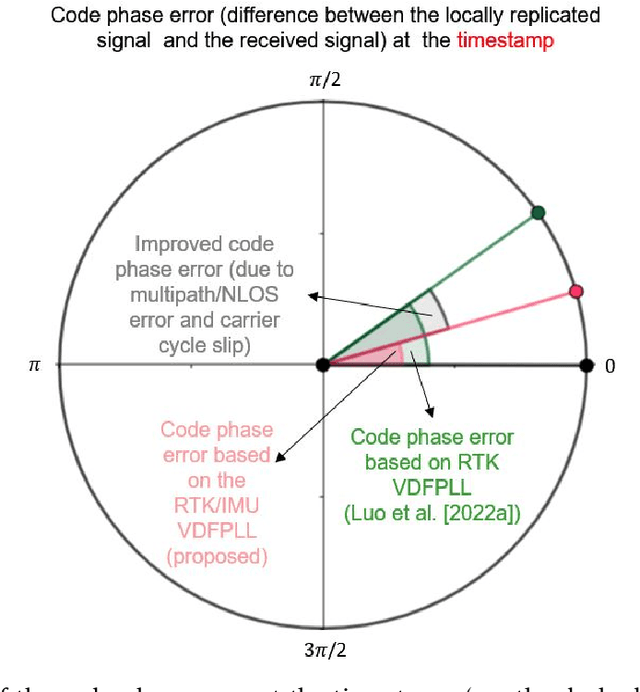
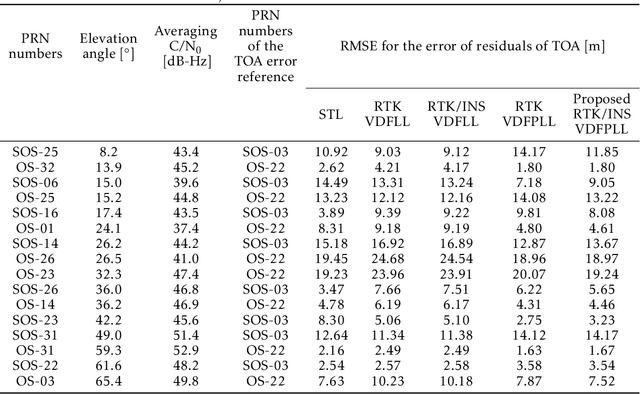
Many multi-sensor navigation systems urgently demand accurate positioning initialization from global navigation satellite systems (GNSSs) in challenging static scenarios. However, ground blockages against line-of-sight (LOS) signal reception make it difficult for GNSS users. Steering local codes in GNSS basebands is a desiring way to correct instantaneous signal phase misalignment, efficiently gathering useful signal power and increasing positioning accuracy. Besides, inertial navigation systems (INSs) have been used as a well-complementary dead reckoning (DR) sensor for GNSS receivers in kinematic scenarios resisting various interferences since early. But little work focuses on the case of whether the INS can improve GNSS receivers in static scenarios. Thus, this paper proposes an enhanced navigation system deeply integrated with low-cost INS solutions and GNSS high-accuracy carrier-based positioning. First, an absolute code phase is predicted from base station information, and integrated solution of the INS DR and real-time kinematic (RTK) results through an extended Kalman filter (EKF). Then, a numerically controlled oscillator (NCO) leverages the predicted code phase to improve the alignment between instantaneous local code phases and received ones. The proposed algorithm is realized in a vector-tracking GNSS software-defined radio (SDR). Real-world experiments demonstrate the proposed SDR regarding estimating time-of-arrival (TOA) and positioning accuracy.
Using Whole Slide Image Representations from Self-Supervised Contrastive Learning for Melanoma Concordance Regression
Oct 10, 2022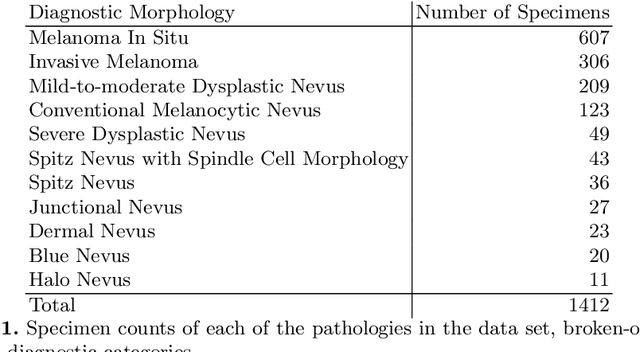
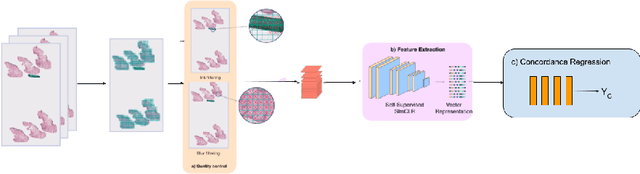

Although melanoma occurs more rarely than several other skin cancers, patients' long term survival rate is extremely low if the diagnosis is missed. Diagnosis is complicated by a high discordance rate among pathologists when distinguishing between melanoma and benign melanocytic lesions. A tool that provides potential concordance information to healthcare providers could help inform diagnostic, prognostic, and therapeutic decision-making for challenging melanoma cases. We present a melanoma concordance regression deep learning model capable of predicting the concordance rate of invasive melanoma or melanoma in-situ from digitized Whole Slide Images (WSIs). The salient features corresponding to melanoma concordance were learned in a self-supervised manner with the contrastive learning method, SimCLR. We trained a SimCLR feature extractor with 83,356 WSI tiles randomly sampled from 10,895 specimens originating from four distinct pathology labs. We trained a separate melanoma concordance regression model on 990 specimens with available concordance ground truth annotations from three pathology labs and tested the model on 211 specimens. We achieved a Root Mean Squared Error (RMSE) of 0.28 +/- 0.01 on the test set. We also investigated the performance of using the predicted concordance rate as a malignancy classifier, and achieved a precision and recall of 0.85 +/- 0.05 and 0.61 +/- 0.06, respectively, on the test set. These results are an important first step for building an artificial intelligence (AI) system capable of predicting the results of consulting a panel of experts and delivering a score based on the degree to which the experts would agree on a particular diagnosis. Such a system could be used to suggest additional testing or other action such as ordering additional stains or genetic tests.
Research on Cross-media Science and Technology Information Data Retrieval
Apr 11, 2022Since the era of big data, the Internet has been flooded with all kinds of information. Browsing information through the Internet has become an integral part of people's daily life. Unlike the news data and social data in the Internet, the cross-media technology information data has different characteristics. This data has become an important basis for researchers and scholars to track the current hot spots and explore the future direction of technology development. As the volume of science and technology information data becomes richer, the traditional science and technology information retrieval system, which only supports unimodal data retrieval and uses outdated data keyword matching model, can no longer meet the daily retrieval needs of science and technology scholars. Therefore, in view of the above research background, it is of profound practical significance to study the cross-media science and technology information data retrieval system based on deep semantic features, which is in line with the development trend of domestic and international technologies.
Research Scholar Interest Mining Method based on Load Centrality
Mar 21, 2022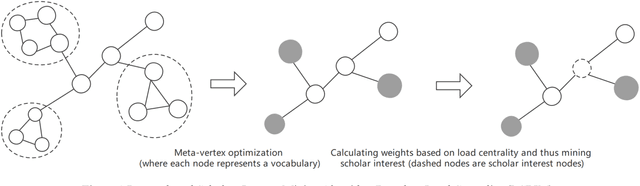
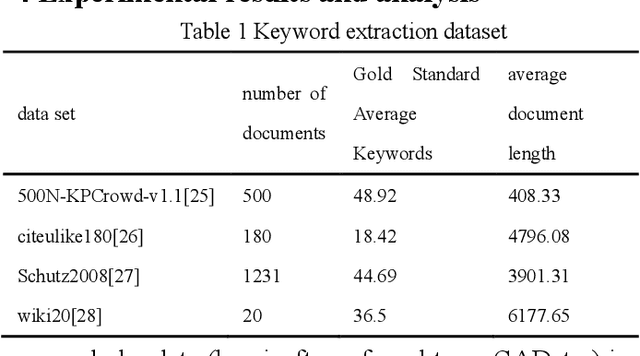
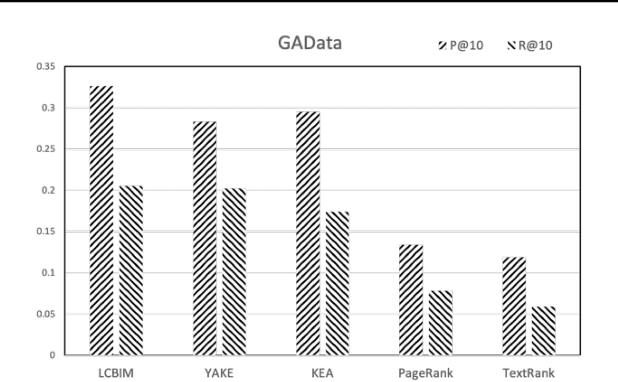
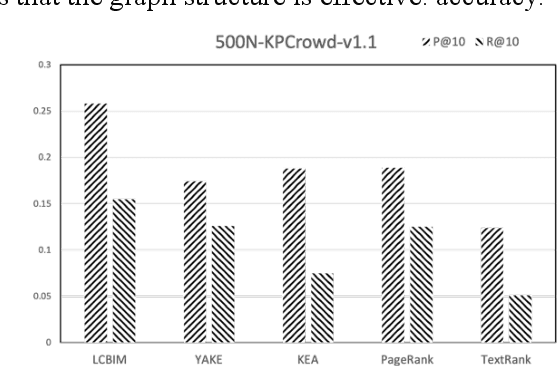
In the era of big data, it is possible to carry out cooperative research on the research results of researchers through papers, patents and other data, so as to study the role of researchers, and produce results in the analysis of results. For the important problems found in the research and application of reality, this paper also proposes a research scholar interest mining algorithm based on load centrality (LCBIM), which can accurately solve the problem according to the researcher's research papers and patent data. Graphs of creative algorithms in various fields of the study aggregated ideas, generated topic graphs by aggregating neighborhoods, used the generated topic information to construct with similar or similar topic spaces, and utilize keywords to construct one or more topics. The regional structure of each topic can be used to closely calculate the weight of the centrality research model of the node, which can analyze the field in the complete coverage principle. The scientific research cooperation based on the load rate center proposed in this paper can effectively extract the interests of scientific research scholars from papers and corpus.