 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Synoptic Review of High-Frequency Oscillations as a Biomarker in Neurodegenerative Disease
Aug 27, 2025High Frequency Oscillations (HFOs), rapid bursts of brain activity above 80 Hz, have emerged as a highly specific biomarker for epileptogenic tissue. Recent evidence suggests that HFOs are also present in Alzheimer's Disease (AD), reflecting underlying network hyperexcitability and offering a promising, noninvasive tool for early diagnosis and disease tracking. This synoptic review provides a comprehensive analysis of publicly available electroencephalography (EEG) datasets relevant to HFO research in neurodegenerative disorders. We conducted a bibliometric analysis of 1,222 articles, revealing a significant and growing research interest in HFOs, particularly within the last ten years. We then systematically profile and compare key public datasets, evaluating their participant cohorts, data acquisition parameters, and accessibility, with a specific focus on their technical suitability for HFO analysis. Our comparative synthesis highlights critical methodological heterogeneity across datasets, particularly in sampling frequency and recording paradigms, which poses challenges for cross-study validation, but also offers opportunities for robustness testing. By consolidating disparate information, clarifying nomenclature, and providing a detailed methodological framework, this review serves as a guide for researchers aiming to leverage public data to advance the role of HFOs as a cross-disease biomarker for AD and related conditions.
Deep learning for state estimation of commercial sodium-ion batteries using partial charging profiles: validation with a multi-temperature ageing dataset
Apr 01, 2025



Accurately predicting the state of health for sodium-ion batteries is crucial for managing battery modules, playing a vital role in ensuring operational safety. However, highly accurate models available thus far are rare due to a lack of aging data for sodium-ion batteries. In this study, we experimentally collected 53 single cells at four temperatures (0, 25, 35, and 45 {\deg}C), along with two battery modules in the lab. By utilizing the charging profiles, we were able to predict the SOC, capacity, and SOH simultaneously. This was achieved by designing a new framework that integrates the neural ordinary differential equation and 2D convolutional neural networks, using the partial charging profile as input. The charging profile is partitioned into segments, and each segment is fed into the network to output the SOC. For capacity and SOH prediction, we first aggregated the extracted features corresponding to segments from one cycle, after which an embedding block for temperature is concatenated for the final prediction. This novel approach eliminates the issue of multiple outputs for a single target. Our model demonstrated an $R^2$ accuracy of 0.998 for SOC and 0.997 for SOH across single cells at various temperatures. Furthermore, the trained model can be employed to predict single cells at temperatures outside the training set and battery modules with different capacity and current levels. The results presented here highlight the high accuracy of our model and its capability to predict multiple targets simultaneously using a partial charging profile.
Multi-Intent Attribute-Aware Text Matching in Searching
Feb 12, 2024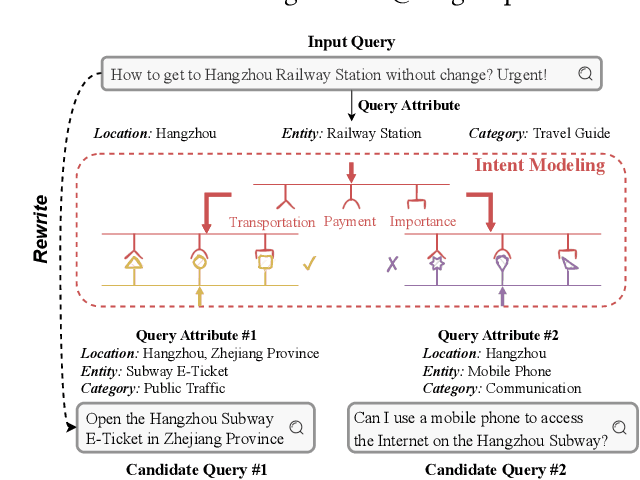
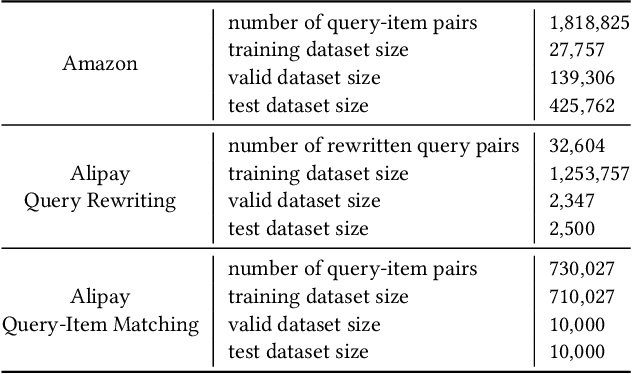
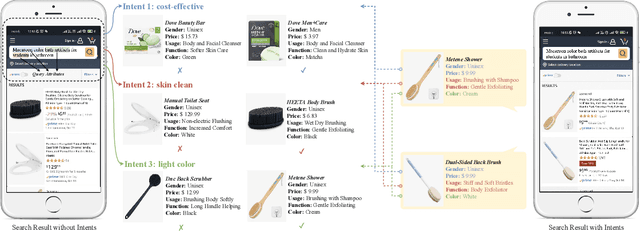
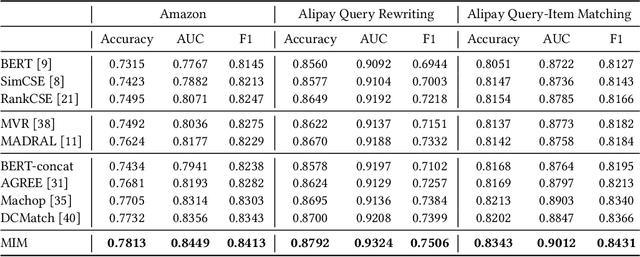
Text matching systems have become a fundamental service in most searching platforms. For instance, they are responsible for matching user queries to relevant candidate items, or rewriting the user-input query to a pre-selected high-performing one for a better search experience. In practice, both the queries and items often contain multiple attributes, such as the category of the item and the location mentioned in the query, which represent condensed key information that is helpful for matching. However, most of the existing works downplay the effectiveness of attributes by integrating them into text representations as supplementary information. Hence, in this work, we focus on exploring the relationship between the attributes from two sides. Since attributes from two ends are often not aligned in terms of number and type, we propose to exploit the benefit of attributes by multiple-intent modeling. The intents extracted from attributes summarize the diverse needs of queries and provide rich content of items, which are more refined and abstract, and can be aligned for paired inputs. Concretely, we propose a multi-intent attribute-aware matching model (MIM), which consists of three main components: attribute-aware encoder, multi-intent modeling, and intent-aware matching. In the attribute-aware encoder, the text and attributes are weighted and processed through a scaled attention mechanism with regard to the attributes' importance. Afterward, the multi-intent modeling extracts intents from two ends and aligns them. Herein, we come up with a distribution loss to ensure the learned intents are diverse but concentrated, and a kullback-leibler divergence loss that aligns the learned intents. Finally, in the intent-aware matching, the intents are evaluated by a self-supervised masking task, and then incorporated to output the final matching result.
A powerful and efficient set test for genetic markers that handles confounders
Apr 08, 2013
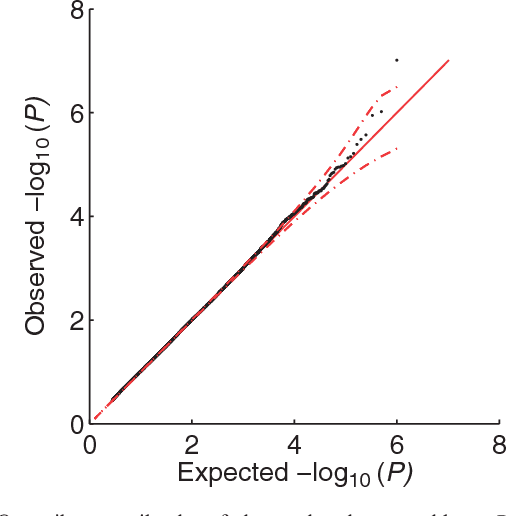
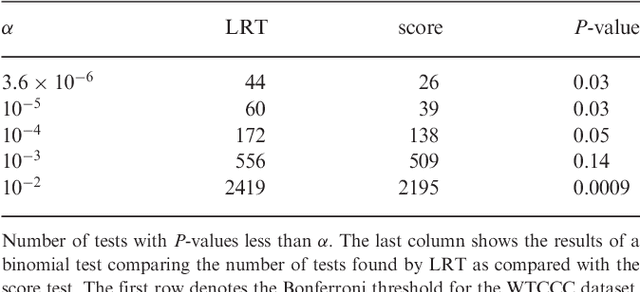

Approaches for testing sets of variants, such as a set of rare or common variants within a gene or pathway, for association with complex traits are important. In particular, set tests allow for aggregation of weak signal within a set, can capture interplay among variants, and reduce the burden of multiple hypothesis testing. Until now, these approaches did not address confounding by family relatedness and population structure, a problem that is becoming more important as larger data sets are used to increase power. Results: We introduce a new approach for set tests that handles confounders. Our model is based on the linear mixed model and uses two random effects-one to capture the set association signal and one to capture confounders. We also introduce a computational speedup for two-random-effects models that makes this approach feasible even for extremely large cohorts. Using this model with both the likelihood ratio test and score test, we find that the former yields more power while controlling type I error. Application of our approach to richly structured GAW14 data demonstrates that our method successfully corrects for population structure and family relatedness, while application of our method to a 15,000 individual Crohn's disease case-control cohort demonstrates that it additionally recovers genes not recoverable by univariate analysis. Availability: A Python-based library implementing our approach is available at http://mscompbio.codeplex.com