 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Intent Attribute-Aware Text Matching in Searching
Paper and Code
Feb 12, 2024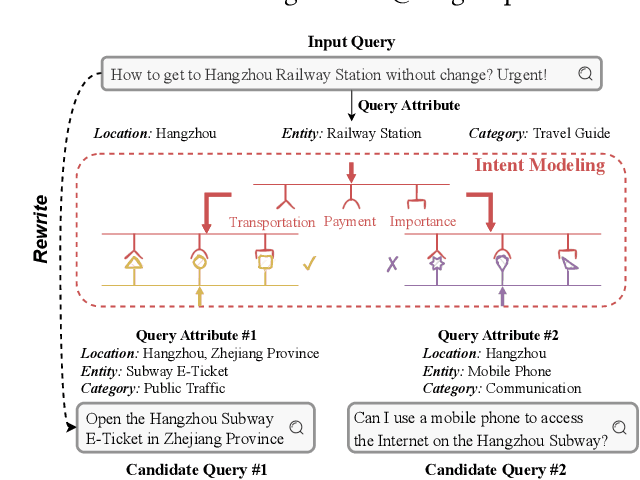
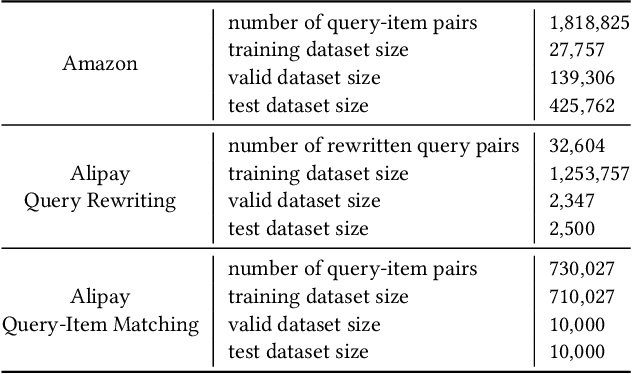
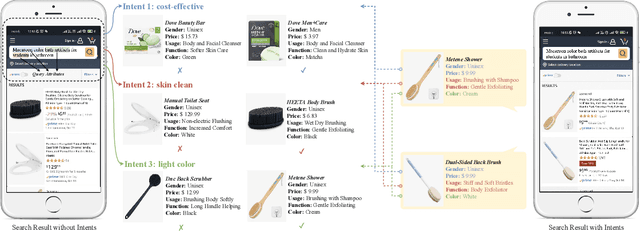
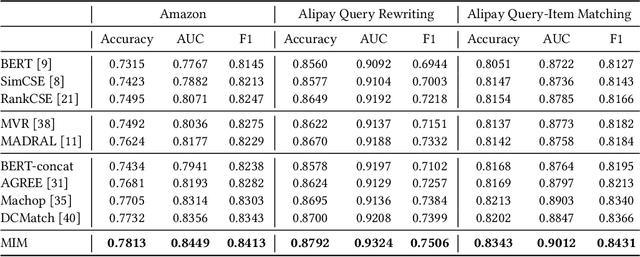
Text matching systems have become a fundamental service in most searching platforms. For instance, they are responsible for matching user queries to relevant candidate items, or rewriting the user-input query to a pre-selected high-performing one for a better search experience. In practice, both the queries and items often contain multiple attributes, such as the category of the item and the location mentioned in the query, which represent condensed key information that is helpful for matching. However, most of the existing works downplay the effectiveness of attributes by integrating them into text representations as supplementary information. Hence, in this work, we focus on exploring the relationship between the attributes from two sides. Since attributes from two ends are often not aligned in terms of number and type, we propose to exploit the benefit of attributes by multiple-intent modeling. The intents extracted from attributes summarize the diverse needs of queries and provide rich content of items, which are more refined and abstract, and can be aligned for paired inputs. Concretely, we propose a multi-intent attribute-aware matching model (MIM), which consists of three main components: attribute-aware encoder, multi-intent modeling, and intent-aware matching. In the attribute-aware encoder, the text and attributes are weighted and processed through a scaled attention mechanism with regard to the attributes' importance. Afterward, the multi-intent modeling extracts intents from two ends and aligns them. Herein, we come up with a distribution loss to ensure the learned intents are diverse but concentrated, and a kullback-leibler divergence loss that aligns the learned intents. Finally, in the intent-aware matching, the intents are evaluated by a self-supervised masking task, and then incorporated to output the final matching result.