 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCCD-CBT: Multi-Agent Therapeutic Interaction for CBT Guided by Cognitive Conceptualization Diagram
Apr 08, 2026Large language models show potential for scalable mental-health support by simulating Cognitive Behavioral Therapy (CBT) counselors. However, existing methods often rely on static cognitive profiles and omniscient single-agent simulation, failing to capture the dynamic, information-asymmetric nature of real therapy. We introduce CCD-CBT, a multi-agent framework that shifts CBT simulation along two axes: 1) from a static to a dynamically reconstructed Cognitive Conceptualization Diagram (CCD), updated by a dedicated Control Agent, and 2) from omniscient to information-asymmetric interaction, where the Therapist Agent must reason from inferred client states. We release CCDCHAT, a synthetic multi-turn CBT dataset generated under this framework. Evaluations with clinical scales and expert therapists show that models fine-tuned on CCDCHAT outperform strong baselines in both counseling fidelity and positive-affect enhancement, with ablations confirming the necessity of dynamic CCD guidance and asymmetric agent design. Our work offers a new paradigm for building theory-grounded, clinically-plausible conversational agents.
The Art of Socratic Inquiry: A Framework for Proactive Template-Guided Therapeutic Conversation Generation
Feb 02, 2026Proactive questioning, where therapists deliberately initiate structured, cognition-guiding inquiries, is a cornerstone of cognitive behavioral therapy (CBT). Yet, current psychological large language models (LLMs) remain overwhelmingly reactive, defaulting to empathetic but superficial responses that fail to surface latent beliefs or guide behavioral change. To bridge this gap, we propose the \textbf{Socratic Inquiry Framework (SIF)}, a lightweight, plug-and-play therapeutic intent planner that transforms LLMs from passive listeners into active cognitive guides. SIF decouples \textbf{when to ask} (via Strategy Anchoring) from \textbf{what to ask} (via Template Retrieval), enabling context-aware, theory-grounded questioning without end-to-end retraining. Complementing SIF, we introduce \textbf{Socratic-QA}, a high-quality dataset of strategy-aligned Socratic sequences that provides explicit supervision for proactive reasoning. Experiments show that SIF significantly enhances proactive questioning frequency, conversational depth, and therapeutic alignment, marking a clear shift from reactive comfort to proactive exploration. Our work establishes a new paradigm for psychologically informed LLMs: not just to respond, but to guide.
Advanced Framework for Animal Sound Classification With Features Optimization
Jul 03, 2024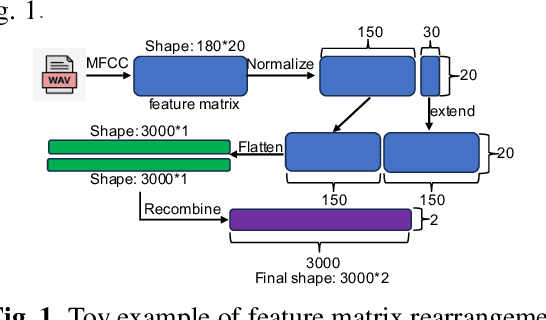
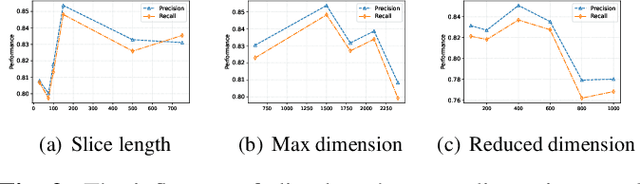
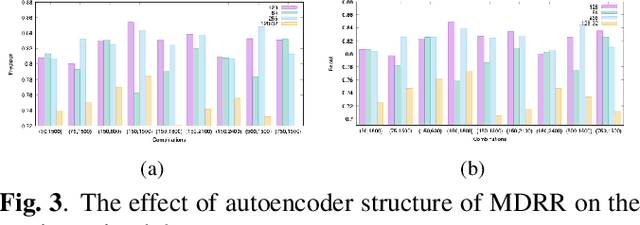
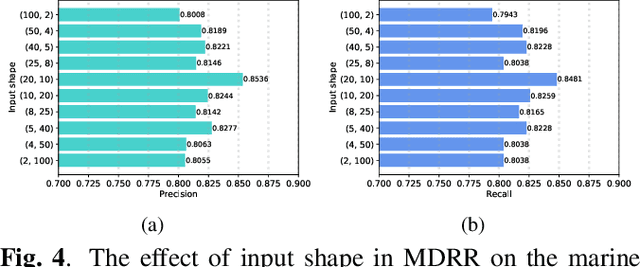
The automatic classification of animal sounds presents an enduring challenge in bioacoustics, owing to the diverse statistical properties of sound signals, variations in recording equipment, and prevalent low Signal-to-Noise Ratio (SNR) conditions. Deep learning models like Convolutional Neural Networks (CNN) and Long Short-Term Memory (LSTM) have excelled in human speech recognition but have not been effectively tailored to the intricate nature of animal sounds, which exhibit substantial diversity even within the same domain. We propose an automated classification framework applicable to general animal sound classification. Our approach first optimizes audio features from Mel-frequency cepstral coefficients (MFCC) including feature rearrangement and feature reduction. It then uses the optimized features for the deep learning model, i.e., an attention-based Bidirectional LSTM (Bi-LSTM), to extract deep semantic features for sound classification. We also contribute an animal sound benchmark dataset encompassing oceanic animals and birds1. Extensive experimentation with real-world datasets demonstrates that our approach consistently outperforms baseline methods by over 25% in precision, recall, and accuracy, promising advancements in animal sound classification.
Multi-Intent Attribute-Aware Text Matching in Searching
Feb 12, 2024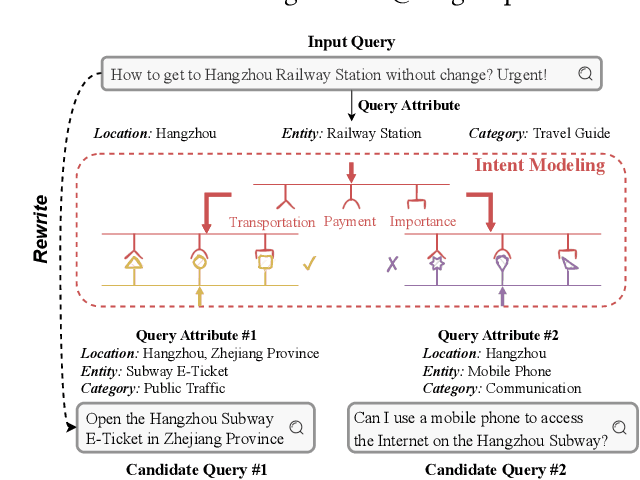
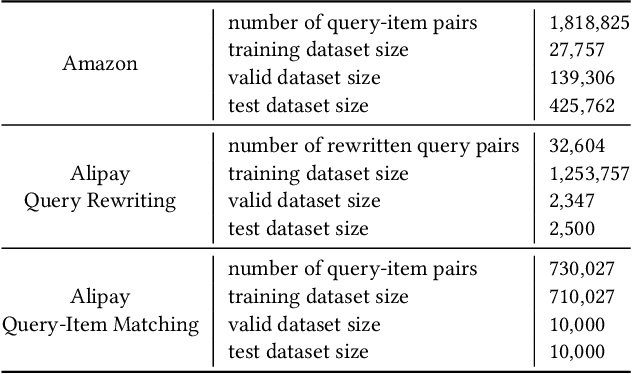
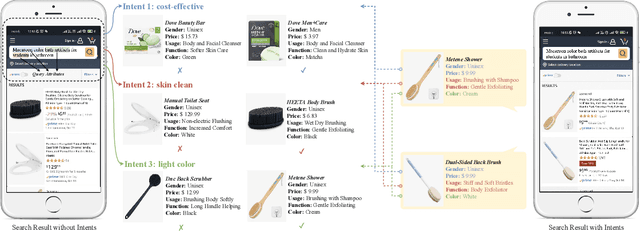
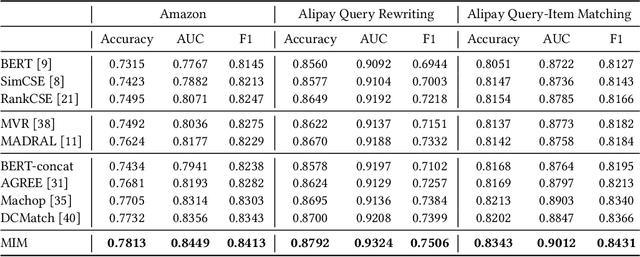
Text matching systems have become a fundamental service in most searching platforms. For instance, they are responsible for matching user queries to relevant candidate items, or rewriting the user-input query to a pre-selected high-performing one for a better search experience. In practice, both the queries and items often contain multiple attributes, such as the category of the item and the location mentioned in the query, which represent condensed key information that is helpful for matching. However, most of the existing works downplay the effectiveness of attributes by integrating them into text representations as supplementary information. Hence, in this work, we focus on exploring the relationship between the attributes from two sides. Since attributes from two ends are often not aligned in terms of number and type, we propose to exploit the benefit of attributes by multiple-intent modeling. The intents extracted from attributes summarize the diverse needs of queries and provide rich content of items, which are more refined and abstract, and can be aligned for paired inputs. Concretely, we propose a multi-intent attribute-aware matching model (MIM), which consists of three main components: attribute-aware encoder, multi-intent modeling, and intent-aware matching. In the attribute-aware encoder, the text and attributes are weighted and processed through a scaled attention mechanism with regard to the attributes' importance. Afterward, the multi-intent modeling extracts intents from two ends and aligns them. Herein, we come up with a distribution loss to ensure the learned intents are diverse but concentrated, and a kullback-leibler divergence loss that aligns the learned intents. Finally, in the intent-aware matching, the intents are evaluated by a self-supervised masking task, and then incorporated to output the final matching result.
Modeling non-uniform uncertainty in Reaction Prediction via Boosting and Dropout
Oct 07, 2023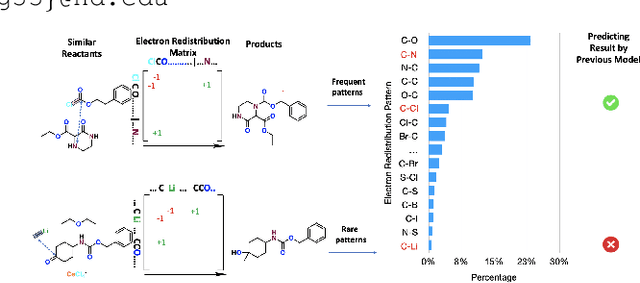
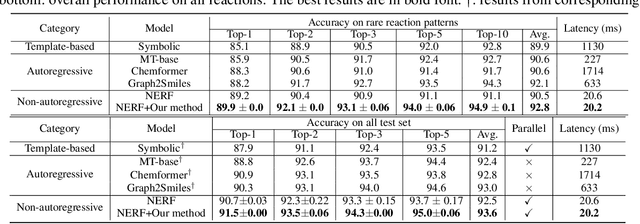
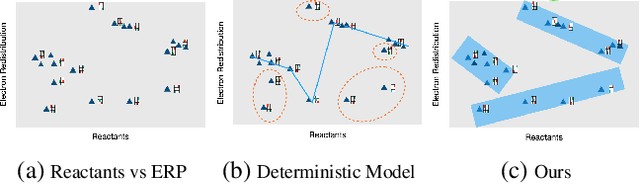
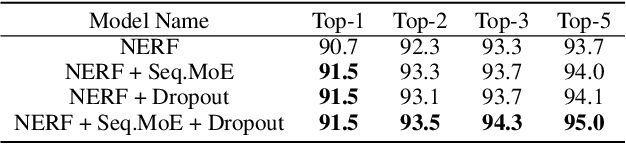
Reaction prediction has been recognized as a critical task in synthetic chemistry, where the goal is to predict the outcome of a reaction based on the given reactants. With the widespread adoption of generative models, the Variational Autoencoder(VAE) framework has typically been employed to tackle challenges in reaction prediction, where the reactants are encoded as a condition for the decoder, which then generates the product. Despite effectiveness, these conditional VAE (CVAE) models still fail to adequately account for the inherent uncertainty in reaction prediction, which primarily stems from the stochastic reaction process. The principal limitations are twofold. Firstly, in these CVAE models, the prior is independent of the reactants, leading to a default wide and assumed uniform distribution variance of the generated product. Secondly, reactants with analogous molecular representations are presumed to undergo similar electronic transition processes, thereby producing similar products. This hinders the ability to model diverse reaction mechanisms effectively. Since the variance in outcomes is inherently non-uniform, we are thus motivated to develop a framework that generates reaction products with non-uniform uncertainty. Firstly, we eliminate the latent variable in previous CVAE models to mitigate uncontrol-label noise. Instead, we introduce randomness into product generation via boosting to ensemble diverse models and cover the range of potential outcomes, and through dropout to secure models with minor variations. Additionally, we design a ranking method to union the predictions from boosting and dropout, prioritizing the most plausible products. Experimental results on the largest reaction prediction benchmark USPTO-MIT show the superior performance of our proposed method in modeling the non-uniform uncertainty compared to baselines.
SenWave: Monitoring the Global Sentiments under the COVID-19 Pandemic
Jun 18, 2020
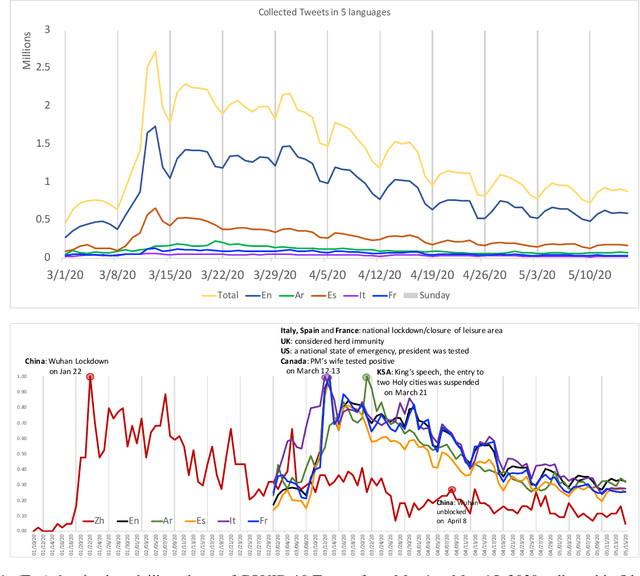
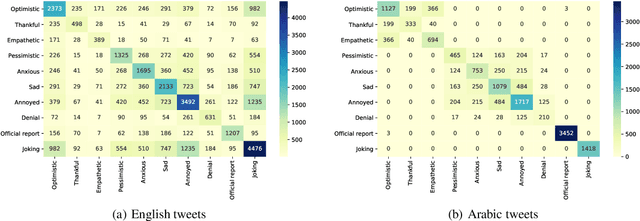

Since the first alert launched by the World Health Organization (5 January, 2020), COVID-19 has been spreading out to over 180 countries and territories. As of June 18, 2020, in total, there are now over 8,400,000 cases and over 450,000 related deaths. This causes massive losses in the economy and jobs globally and confining about 58% of the global population. In this paper, we introduce SenWave, a novel sentimental analysis work using 105+ million collected tweets and Weibo messages to evaluate the global rise and falls of sentiments during the COVID-19 pandemic. To make a fine-grained analysis on the feeling when we face this global health crisis, we annotate 10K tweets in English and 10K tweets in Arabic in 10 categories, including optimistic, thankful, empathetic, pessimistic, anxious, sad, annoyed, denial, official report, and joking. We then utilize an integrated transformer framework, called simpletransformer, to conduct multi-label sentimental classification by fine-tuning the pre-trained language model on the labeled data. Meanwhile, in order for a more complete analysis, we also translate the annotated English tweets into different languages (Spanish, Italian, and French) to generated training data for building sentiment analysis models for these languages. SenWave thus reveals the sentiment of global conversation in six different languages on COVID-19 (covering English, Spanish, French, Italian, Arabic and Chinese), followed the spread of the epidemic. The conversation showed a remarkably similar pattern of rapid rise and slow decline over time across all nations, as well as on special topics like the herd immunity strategies, to which the global conversation reacts strongly negatively. Overall, SenWave shows that optimistic and positive sentiments increased over time, foretelling a desire to seek, together, a reset for an improved COVID-19 world.
Outcome-Driven Clustering of Acute Coronary Syndrome Patients using Multi-Task Neural Network with Attention
Mar 27, 2019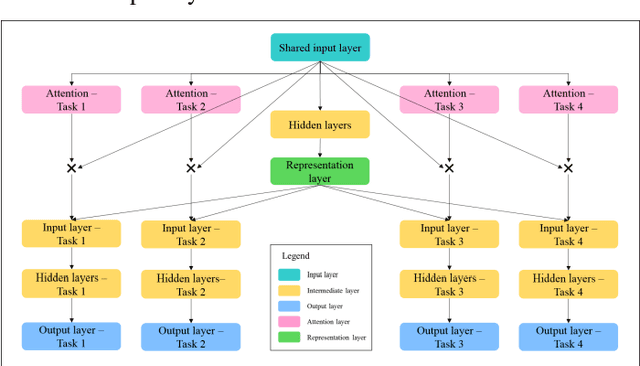
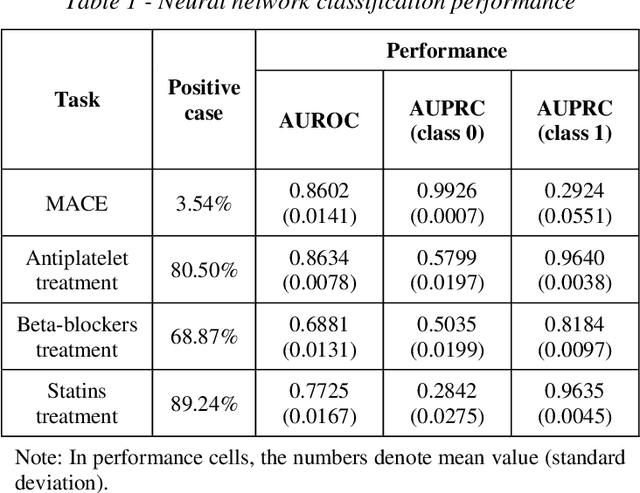
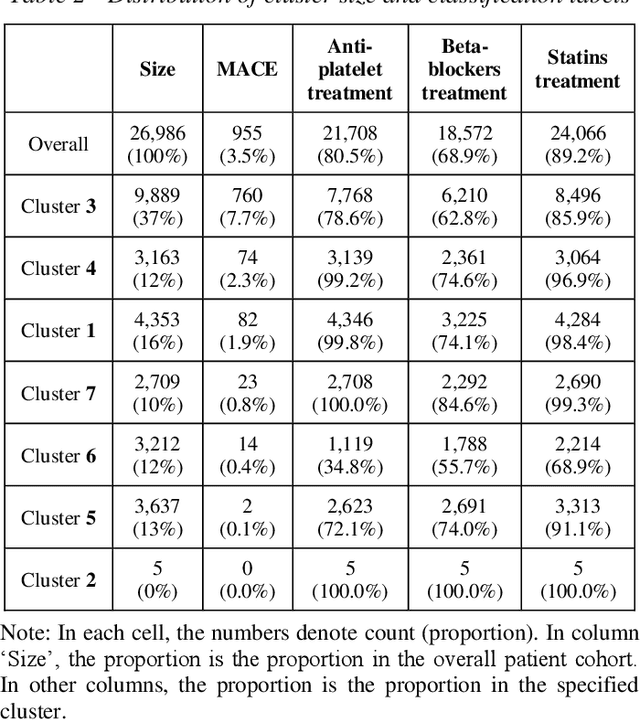
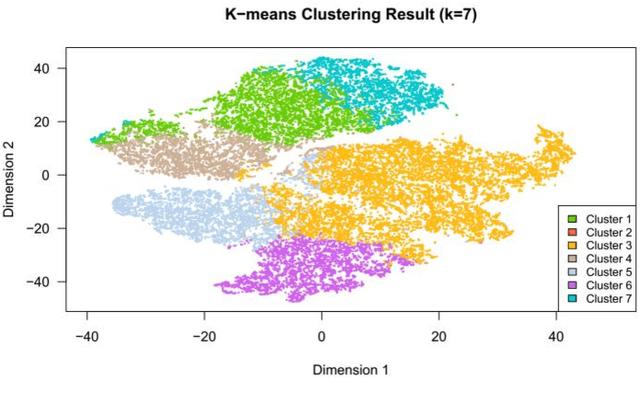
Cluster analysis aims at separating patients into phenotypically heterogenous groups and defining therapeutically homogeneous patient subclasses. It is an important approach in data-driven disease classification and subtyping. Acute coronary syndrome (ACS) is a syndrome due to sudden decrease of coronary artery blood flow, where disease classification would help to inform therapeutic strategies and provide prognostic insights. Here we conducted outcome-driven cluster analysis of ACS patients, which jointly considers treatment and patient outcome as indicators for patient state. Multi-task neural network with attention was used as a modeling framework, including learning of the patient state, cluster analysis, and feature importance profiling. Seven patient clusters were discovered. The clusters have different characteristics, as well as different risk profiles to the outcome of in-hospital major adverse cardiac events. The results demonstrate cluster analysis using outcome-driven multi-task neural network as promising for patient classification and subtyping.