 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGetting Better at Working With You: Compiling User Corrections into Runtime Enforcement for Coding Agents
Jun 11, 2026Interactive LLM agents are becoming part of daily work, but they do not reliably become easier to work with over time: a correction remembered in one session may still be violated in the next. We study this gap between preference access and preference compliance. In tasks derived from anonymized real-user friction cases, Mem0 memory still leaves 57.5% of applicable preference checks violated. We introduce Test-time Rule Acquisition and Compiled Enforcement (TRACE), a drop-in skill-layer pipeline for coding-agent runtimes that mines user corrections, rewrites them as atomic rules, and compiles them into runtime checks that must pass before an agent completes future tasks. Unlike runtime checks written ahead of time by developers, TRACE skills come from the user's own chat corrections. We evaluate TRACE with simulated user-in-the-loop experiments on ClawArena coding-agent tasks and MemoryArena-derived memory-intensive tasks. On ClawArena, TRACE reduces held-out preference violation from 100.0% to 37.6% on in-distribution tasks and from 100.0% to 2.0% on out-of-distribution tasks. On MemoryArena-derived tasks, TRACE reduces in-distribution violation from 100.0% to 60.5% while matching or exceeding the strongest memory baseline on task pass. These results suggest that compiling corrections into runtime enforcement can address a repeated-friction failure mode that memory alone does not reliably solve, reducing the need for users to restate the same correction across future sessions. Experiment code is available at https://github.com/YujunZhou/TRACE_exp, and the deployable skill is available at https://github.com/YujunZhou/tellonce.
PolicyLLM: Towards Excellent Comprehension of Public Policy for Large Language Models
Apr 14, 2026Large Language Models (LLMs) are increasingly integrated into real-world decision-making, including in the domain of public policy. Yet, their ability to comprehend and reason about policy-related content remains underexplored. To fill this gap, we present \textbf{\textit{PolicyBench}}, the first large-scale cross-system benchmark (US-China) evaluating policy comprehension, comprising 21K cases across a broad spectrum of policy areas, capturing the diversity and complexity of real-world governance. Following Bloom's taxonomy, the benchmark assesses three core capabilities: (1) \textbf{Memorization}: factual recall of policy knowledge, (2) \textbf{Understanding}: conceptual and contextual reasoning, and (3) \textbf{Application}: problem-solving in real-life policy scenarios. Building on this benchmark, we further propose \textbf{\textit{PolicyMoE}}, a domain-specialized Mixture-of-Experts (MoE) model with expert modules aligned to each cognitive level. The proposed models demonstrate stronger performance on application-oriented policy tasks than on memorization or conceptual understanding, and yields the highest accuracy on structured reasoning tasks. Our results reveal key limitations of current LLMs in policy understanding and suggest paths toward more reliable, policy-focused models.
Dual Optimal: Make Your LLM Peer-like with Dignity
Apr 02, 2026Current aligned language models exhibit a dual failure mode we term the Evasive Servant: they sycophantically validate flawed user beliefs while deflecting responsibility with boilerplate disclaimers. We propose the Dignified Peer framework, which counters servility with anti-sycophancy and trustworthiness, and mitigates evasiveness through empathy and creativity. Realizing this agent requires overcoming significant challenges in data supervision, objective collapse, and evaluation bias. We address these issues by introducing the PersonaKnob dataset which features a compositional partial order structure of multiple persona preference. This data is utilized alongside a tolerant constrained Lagrangian DPO algorithm that dynamically balances all persona dimensions to prevent behavioral collapse. Additionally, we employ a psychometrically calibrated Item Response Theory evaluation protocol to disentangle latent model persona capability from confounders like judge biases. Extensive empirical studies demonstrate that our approach successfully build a LLM agent with both dignity and peer.
Reliable Control-Point Selection for Steering Reasoning in Large Language Models
Apr 02, 2026Steering vectors offer a training-free mechanism for controlling reasoning behaviors in large language models, but constructing effective vectors requires identifying genuine behavioral signals in the model's hidden states. For behaviors that can be toggled via prompts, this is straightforward. However, many reasoning behaviors -- such as self-reflection -- emerge spontaneously and resist prompt-level control. Current methods detect these behaviors through keyword matching in chain-of-thought traces, implicitly assuming that every detected boundary encodes a genuine behavioral signal. We show that this assumption is overwhelmingly wrong: across 541 keyword-detected boundaries, 93.3\% are behaviorally unstable, failing to reproduce the detected behavior under re-generation from the same prefix. We develop a probabilistic model that formalizes intrinsic reasoning behaviors as stochastic events with context-dependent trigger probabilities, and show that unstable boundaries dilute the steering signal. Guided by this analysis, we propose stability filtering, which retains only boundaries where the model consistently reproduces the target behavior. Combined with a content-subspace projection that removes residual question-specific noise, our method achieves 0.784 accuracy on MATH-500 (+5.0 over the strongest baseline). The resulting steering vectors transfer across models in the same architecture family without re-extraction, improving Nemotron-Research-Reasoning-1.5B (+5.0) and DeepScaleR-1.5B-Preview (+6.0). Code is available at https://github.com/zhmzm/stability-steering.
ProbeLLM: Automating Principled Diagnosis of LLM Failures
Feb 13, 2026Understanding how and why large language models (LLMs) fail is becoming a central challenge as models rapidly evolve and static evaluations fall behind. While automated probing has been enabled by dynamic test generation, existing approaches often discover isolated failure cases, lack principled control over exploration, and provide limited insight into the underlying structure of model weaknesses. We propose ProbeLLM, a benchmark-agnostic automated probing framework that elevates weakness discovery from individual failures to structured failure modes. ProbeLLM formulates probing as a hierarchical Monte Carlo Tree Search, explicitly allocating limited probing budgets between global exploration of new failure regions and local refinement of recurring error patterns. By restricting probing to verifiable test cases and leveraging tool-augmented generation and verification, ProbeLLM grounds failure discovery in reliable evidence. Discovered failures are further consolidated into interpretable failure modes via failure-aware embeddings and boundary-aware induction. Across diverse benchmarks and LLMs, ProbeLLM reveals substantially broader, cleaner, and more fine-grained failure landscapes than static benchmarks and prior automated methods, supporting a shift from case-centric evaluation toward principled weakness discovery.
Capability-Oriented Training Induced Alignment Risk
Feb 12, 2026While most AI alignment research focuses on preventing models from generating explicitly harmful content, a more subtle risk is emerging: capability-oriented training induced exploitation. We investigate whether language models, when trained with reinforcement learning (RL) in environments with implicit loopholes, will spontaneously learn to exploit these flaws to maximize their reward, even without any malicious intent in their training. To test this, we design a suite of four diverse "vulnerability games", each presenting a unique, exploitable flaw related to context-conditional compliance, proxy metrics, reward tampering, and self-evaluation. Our experiments show that models consistently learn to exploit these vulnerabilities, discovering opportunistic strategies that significantly increase their reward at the expense of task correctness or safety. More critically, we find that these exploitative strategies are not narrow "tricks" but generalizable skills; they can be transferred to new tasks and even "distilled" from a capable teacher model to other student models through data alone. Our findings reveal that capability-oriented training induced risks pose a fundamental challenge to current alignment approaches, suggesting that future AI safety work must extend beyond content moderation to rigorously auditing and securing the training environments and reward mechanisms themselves. Code is available at https://github.com/YujunZhou/Capability_Oriented_Alignment_Risk.
Dissecting Logical Reasoning in LLMs: A Fine-Grained Evaluation and Supervision Study
Jun 05, 2025Logical reasoning is a core capability for many applications of large language models (LLMs), yet existing benchmarks often rely solely on final-answer accuracy, failing to capture the quality and structure of the reasoning process. We propose FineLogic, a fine-grained evaluation framework that assesses logical reasoning across three dimensions: overall benchmark accuracy, stepwise soundness, and representation-level alignment. In addition, to better understand how reasoning capabilities emerge, we conduct a comprehensive study on the effects of supervision format during fine-tuning. We construct four supervision styles (one natural language and three symbolic variants) and train LLMs under each. Our findings reveal that natural language supervision yields strong generalization even on out-of-distribution and long-context tasks, while symbolic reasoning styles promote more structurally sound and atomic inference chains. Further, our representation-level probing shows that fine-tuning primarily improves reasoning behaviors through step-by-step generation, rather than enhancing shortcut prediction or internalized correctness. Together, our framework and analysis provide a more rigorous and interpretable lens for evaluating and improving logical reasoning in LLMs.
AdaReasoner: Adaptive Reasoning Enables More Flexible Thinking
May 22, 2025LLMs often need effective configurations, like temperature and reasoning steps, to handle tasks requiring sophisticated reasoning and problem-solving, ranging from joke generation to mathematical reasoning. Existing prompting approaches usually adopt general-purpose, fixed configurations that work 'well enough' across tasks but seldom achieve task-specific optimality. To address this gap, we introduce AdaReasoner, an LLM-agnostic plugin designed for any LLM to automate adaptive reasoning configurations for tasks requiring different types of thinking. AdaReasoner is trained using a reinforcement learning (RL) framework, combining a factorized action space with a targeted exploration strategy, along with a pretrained reward model to optimize the policy model for reasoning configurations with only a few-shot guide. AdaReasoner is backed by theoretical guarantees and experiments of fast convergence and a sublinear policy gap. Across six different LLMs and a variety of reasoning tasks, it consistently outperforms standard baselines, preserves out-of-distribution robustness, and yield gains on knowledge-intensive tasks through tailored prompts.
Beyond Single-Value Metrics: Evaluating and Enhancing LLM Unlearning with Cognitive Diagnosis
Feb 19, 2025Due to the widespread use of LLMs and the rising critical ethical and safety concerns, LLM unlearning methods have been developed to remove harmful knowledge and undesirable capabilities. In this context, evaluations are mostly based on single-value metrics such as QA accuracy. However, these metrics often fail to capture the nuanced retention of harmful knowledge components, making it difficult to assess the true effectiveness of unlearning. To address this issue, we propose UNCD (UNlearning evaluation via Cognitive Diagnosis), a novel framework that leverages Cognitive Diagnosis Modeling for fine-grained evaluation of LLM unlearning. Our dedicated benchmark, UNCD-Cyber, provides a detailed assessment of the removal of dangerous capabilities. Moreover, we introduce UNCD-Agent, which refines unlearning by diagnosing knowledge remnants and generating targeted unlearning data. Extensive experiments across eight unlearning methods and two base models demonstrate that UNCD not only enhances evaluation but also effectively facilitates the removal of harmful LLM abilities.
UOE: Unlearning One Expert Is Enough For Mixture-of-experts LLMS
Nov 27, 2024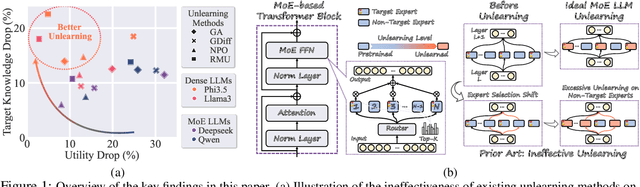

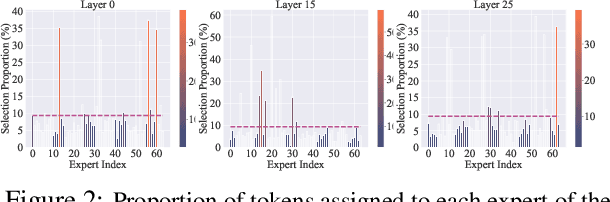
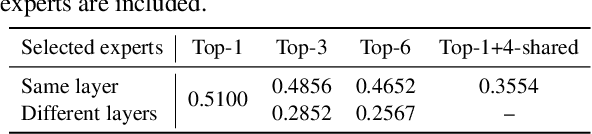
Recent advancements in large language model (LLM) unlearning have shown remarkable success in removing unwanted data-model influences while preserving the model's utility for legitimate knowledge. However, despite these strides, sparse Mixture-of-Experts (MoE) LLMs--a key subset of the LLM family--have received little attention and remain largely unexplored in the context of unlearning. As MoE LLMs are celebrated for their exceptional performance and highly efficient inference processes, we ask: How can unlearning be performed effectively and efficiently on MoE LLMs? And will traditional unlearning methods be applicable to MoE architectures? Our pilot study shows that the dynamic routing nature of MoE LLMs introduces unique challenges, leading to substantial utility drops when existing unlearning methods are applied. Specifically, unlearning disrupts the router's expert selection, causing significant selection shift from the most unlearning target-related experts to irrelevant ones. As a result, more experts than necessary are affected, leading to excessive forgetting and loss of control over which knowledge is erased. To address this, we propose a novel single-expert unlearning framework, referred to as UOE, for MoE LLMs. Through expert attribution, unlearning is concentrated on the most actively engaged expert for the specified knowledge. Concurrently, an anchor loss is applied to the router to stabilize the active state of this targeted expert, ensuring focused and controlled unlearning that preserves model utility. The proposed UOE framework is also compatible with various unlearning algorithms. Extensive experiments demonstrate that UOE enhances both forget quality up to 5% and model utility by 35% on MoE LLMs across various benchmarks, LLM architectures, while only unlearning 0.06% of the model parameters.