 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCapability-Oriented Training Induced Alignment Risk
Feb 12, 2026While most AI alignment research focuses on preventing models from generating explicitly harmful content, a more subtle risk is emerging: capability-oriented training induced exploitation. We investigate whether language models, when trained with reinforcement learning (RL) in environments with implicit loopholes, will spontaneously learn to exploit these flaws to maximize their reward, even without any malicious intent in their training. To test this, we design a suite of four diverse "vulnerability games", each presenting a unique, exploitable flaw related to context-conditional compliance, proxy metrics, reward tampering, and self-evaluation. Our experiments show that models consistently learn to exploit these vulnerabilities, discovering opportunistic strategies that significantly increase their reward at the expense of task correctness or safety. More critically, we find that these exploitative strategies are not narrow "tricks" but generalizable skills; they can be transferred to new tasks and even "distilled" from a capable teacher model to other student models through data alone. Our findings reveal that capability-oriented training induced risks pose a fundamental challenge to current alignment approaches, suggesting that future AI safety work must extend beyond content moderation to rigorously auditing and securing the training environments and reward mechanisms themselves. Code is available at https://github.com/YujunZhou/Capability_Oriented_Alignment_Risk.
From Verification Burden to Trusted Collaboration: Design Goals for LLM-Assisted Literature Reviews
Dec 12, 2025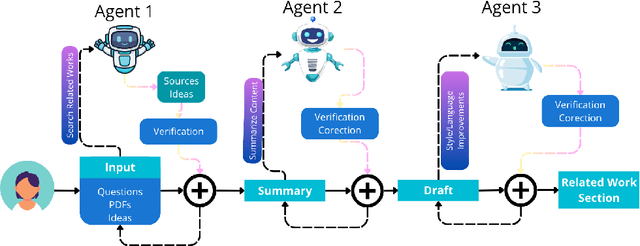
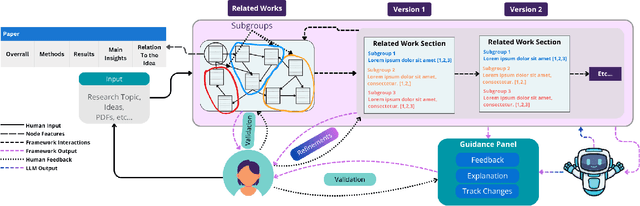
Large Language Models (LLMs) are increasingly embedded in academic writing practices. Although numerous studies have explored how researchers employ these tools for scientific writing, their concrete implementation, limitations, and design challenges within the literature review process remain underexplored. In this paper, we report a user study with researchers across multiple disciplines to characterize current practices, benefits, and \textit{pain points} in using LLMs to investigate related work. We identified three recurring gaps: (i) lack of trust in outputs, (ii) persistent verification burden, and (iii) requiring multiple tools. This motivates our proposal of six design goals and a high-level framework that operationalizes them through improved related papers visualization, verification at every step, and human-feedback alignment with generation-guided explanations. Overall, by grounding our work in the practical, day-to-day needs of researchers, we designed a framework that addresses these limitations and models real-world LLM-assisted writing, advancing trust through verifiable actions and fostering practical collaboration between researchers and AI systems.
Generate, Evaluate, Iterate: Synthetic Data for Human-in-the-Loop Refinement of LLM Judges
Nov 06, 2025The LLM-as-a-judge paradigm enables flexible, user-defined evaluation, but its effectiveness is often limited by the scarcity of diverse, representative data for refining criteria. We present a tool that integrates synthetic data generation into the LLM-as-a-judge workflow, empowering users to create tailored and challenging test cases with configurable domains, personas, lengths, and desired outcomes, including borderline cases. The tool also supports AI-assisted inline editing of existing test cases. To enhance transparency and interpretability, it reveals the prompts and explanations behind each generation. In a user study (N=24), 83% of participants preferred the tool over manually creating or selecting test cases, as it allowed them to rapidly generate diverse synthetic data without additional workload. The generated synthetic data proved as effective as hand-crafted data for both refining evaluation criteria and aligning with human preferences. These findings highlight synthetic data as a promising alternative, particularly in contexts where efficiency and scalability are critical.
Highlight All the Phrases: Enhancing LLM Transparency through Visual Factuality Indicators
Aug 09, 2025Large language models (LLMs) are susceptible to generating inaccurate or false information, often referred to as "hallucinations" or "confabulations." While several technical advancements have been made to detect hallucinated content by assessing the factuality of the model's responses, there is still limited research on how to effectively communicate this information to users. To address this gap, we conducted two scenario-based experiments with a total of 208 participants to systematically compare the effects of various design strategies for communicating factuality scores by assessing participants' ratings of trust, ease in validating response accuracy, and preference. Our findings reveal that participants preferred and trusted a design in which all phrases within a response were color-coded based on factuality scores. Participants also found it easier to validate accuracy of the response in this style compared to a baseline with no style applied. Our study offers practical design guidelines for LLM application developers and designers, aimed at calibrating user trust, aligning with user preferences, and enhancing users' ability to scrutinize LLM outputs.
Hide or Highlight: Understanding the Impact of Factuality Expression on User Trust
Aug 09, 2025Large language models are known to produce outputs that are plausible but factually incorrect. To prevent people from making erroneous decisions by blindly trusting AI, researchers have explored various ways of communicating factuality estimates in AI-generated outputs to end-users. However, little is known about whether revealing content estimated to be factually incorrect influences users' trust when compared to hiding it altogether. We tested four different ways of disclosing an AI-generated output with factuality assessments: transparent (highlights less factual content), attention (highlights factual content), opaque (removes less factual content), ambiguity (makes less factual content vague), and compared them with a baseline response without factuality information. We conducted a human subjects research (N = 148) using the strategies in question-answering scenarios. We found that the opaque and ambiguity strategies led to higher trust while maintaining perceived answer quality, compared to the other strategies. We discuss the efficacy of hiding presumably less factual content to build end-user trust.
A Case Study Investigating the Role of Generative AI in Quality Evaluations of Epics in Agile Software Development
May 12, 2025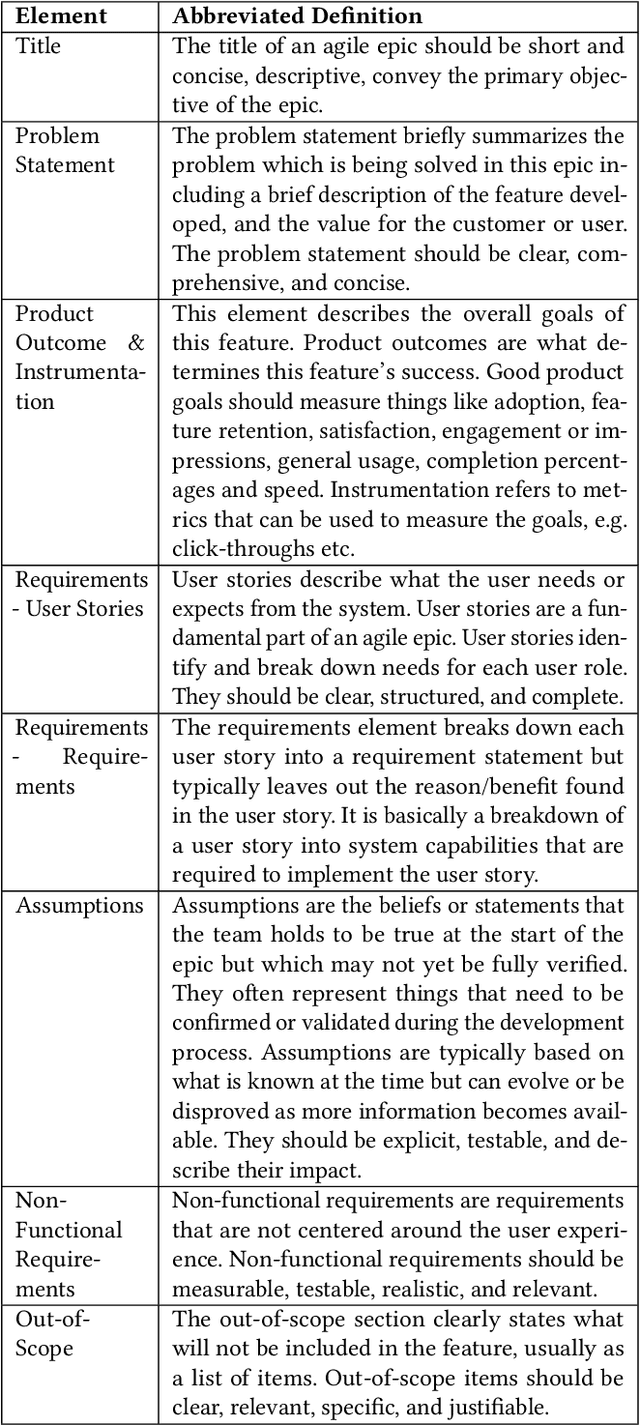
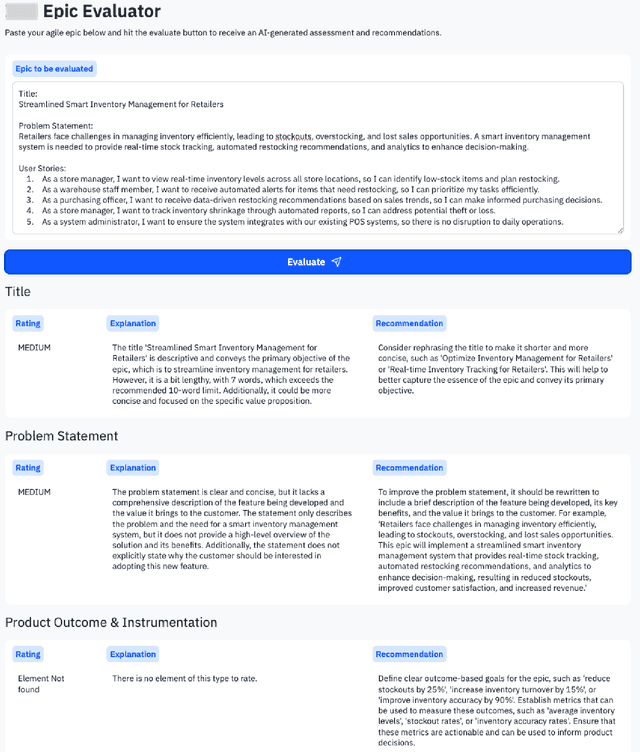
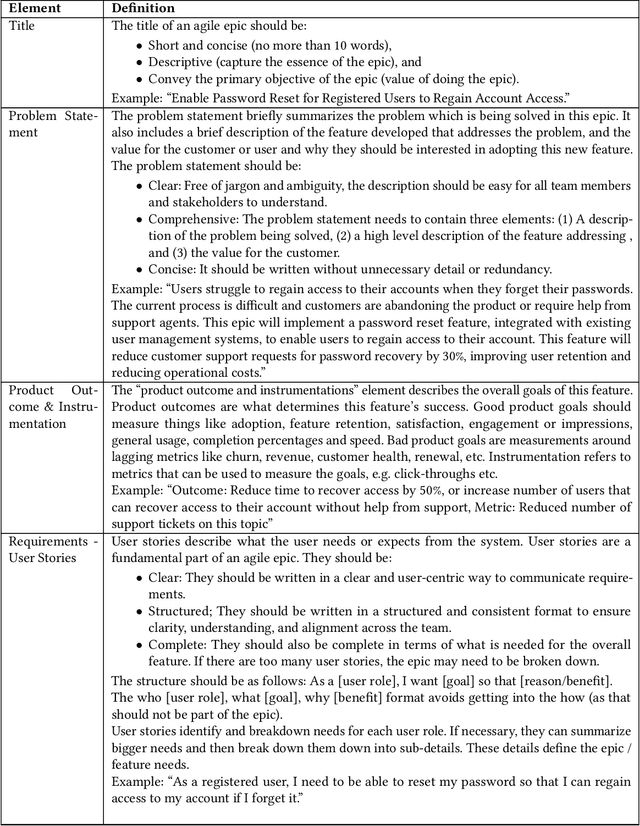
The broad availability of generative AI offers new opportunities to support various work domains, including agile software development. Agile epics are a key artifact for product managers to communicate requirements to stakeholders. However, in practice, they are often poorly defined, leading to churn, delivery delays, and cost overruns. In this industry case study, we investigate opportunities for large language models (LLMs) to evaluate agile epic quality in a global company. Results from a user study with 17 product managers indicate how LLM evaluations could be integrated into their work practices, including perceived values and usage in improving their epics. High levels of satisfaction indicate that agile epics are a new, viable application of AI evaluations. However, our findings also outline challenges, limitations, and adoption barriers that can inform both practitioners and researchers on the integration of such evaluations into future agile work practices.
"The Diagram is like Guardrails": Structuring GenAI-assisted Hypotheses Exploration with an Interactive Shared Representation
Mar 21, 2025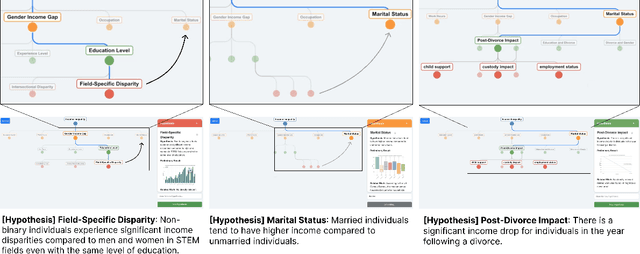
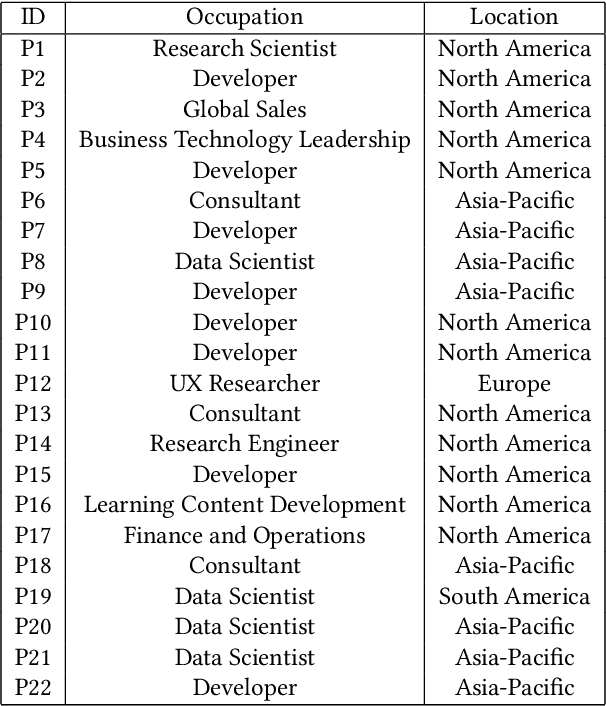
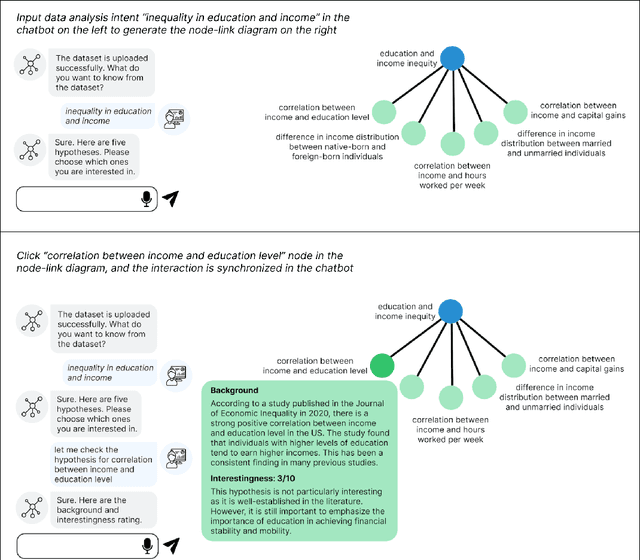
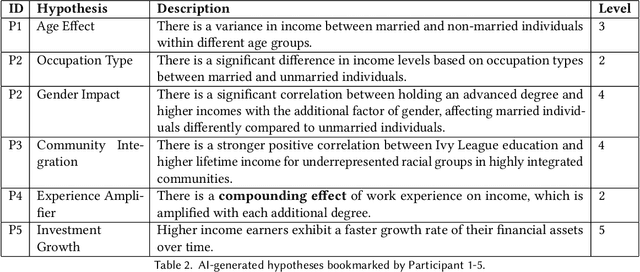
Data analysis encompasses a spectrum of tasks, from high-level conceptual reasoning to lower-level execution. While AI-powered tools increasingly support execution tasks, there remains a need for intelligent assistance in conceptual tasks. This paper investigates the design of an ordered node-link tree interface augmented with AI-generated information hints and visualizations, as a potential shared representation for hypothesis exploration. Through a design probe (n=22), participants generated diagrams averaging 21.82 hypotheses. Our findings showed that the node-link diagram acts as "guardrails" for hypothesis exploration, facilitating structured workflows, providing comprehensive overviews, and enabling efficient backtracking. The AI-generated information hints, particularly visualizations, aided users in transforming abstract ideas into data-backed concepts while reducing cognitive load. We further discuss how node-link diagrams can support both parallel exploration and iterative refinement in hypothesis formulation, potentially enhancing the breadth and depth of human-AI collaborative data analysis.
NGQA: A Nutritional Graph Question Answering Benchmark for Personalized Health-aware Nutritional Reasoning
Dec 20, 2024



Diet plays a critical role in human health, yet tailoring dietary reasoning to individual health conditions remains a major challenge. Nutrition Question Answering (QA) has emerged as a popular method for addressing this problem. However, current research faces two critical limitations. On one hand, the absence of datasets involving user-specific medical information severely limits \textit{personalization}. This challenge is further compounded by the wide variability in individual health needs. On the other hand, while large language models (LLMs), a popular solution for this task, demonstrate strong reasoning abilities, they struggle with the domain-specific complexities of personalized healthy dietary reasoning, and existing benchmarks fail to capture these challenges. To address these gaps, we introduce the Nutritional Graph Question Answering (NGQA) benchmark, the first graph question answering dataset designed for personalized nutritional health reasoning. NGQA leverages data from the National Health and Nutrition Examination Survey (NHANES) and the Food and Nutrient Database for Dietary Studies (FNDDS) to evaluate whether a food is healthy for a specific user, supported by explanations of the key contributing nutrients. The benchmark incorporates three question complexity settings and evaluates reasoning across three downstream tasks. Extensive experiments with LLM backbones and baseline models demonstrate that the NGQA benchmark effectively challenges existing models. In sum, NGQA addresses a critical real-world problem while advancing GraphQA research with a novel domain-specific benchmark.
Granite Guardian
Dec 10, 2024



We introduce the Granite Guardian models, a suite of safeguards designed to provide risk detection for prompts and responses, enabling safe and responsible use in combination with any large language model (LLM). These models offer comprehensive coverage across multiple risk dimensions, including social bias, profanity, violence, sexual content, unethical behavior, jailbreaking, and hallucination-related risks such as context relevance, groundedness, and answer relevance for retrieval-augmented generation (RAG). Trained on a unique dataset combining human annotations from diverse sources and synthetic data, Granite Guardian models address risks typically overlooked by traditional risk detection models, such as jailbreaks and RAG-specific issues. With AUC scores of 0.871 and 0.854 on harmful content and RAG-hallucination-related benchmarks respectively, Granite Guardian is the most generalizable and competitive model available in the space. Released as open-source, Granite Guardian aims to promote responsible AI development across the community. https://github.com/ibm-granite/granite-guardian
LabSafety Bench: Benchmarking LLMs on Safety Issues in Scientific Labs
Oct 18, 2024



Laboratory accidents pose significant risks to human life and property, underscoring the importance of robust safety protocols. Despite advancements in safety training, laboratory personnel may still unknowingly engage in unsafe practices. With the increasing reliance on large language models (LLMs) for guidance in various fields, including laboratory settings, there is a growing concern about their reliability in critical safety-related decision-making. Unlike trained human researchers, LLMs lack formal lab safety education, raising questions about their ability to provide safe and accurate guidance. Existing research on LLM trustworthiness primarily focuses on issues such as ethical compliance, truthfulness, and fairness but fails to fully cover safety-critical real-world applications, like lab safety. To address this gap, we propose the Laboratory Safety Benchmark (LabSafety Bench), a comprehensive evaluation framework based on a new taxonomy aligned with Occupational Safety and Health Administration (OSHA) protocols. This benchmark includes 765 multiple-choice questions verified by human experts, assessing LLMs and vision language models (VLMs) performance in lab safety contexts. Our evaluations demonstrate that while GPT-4o outperforms human participants, it is still prone to critical errors, highlighting the risks of relying on LLMs in safety-critical environments. Our findings emphasize the need for specialized benchmarks to accurately assess the trustworthiness of LLMs in real-world safety applications.