 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"The Diagram is like Guardrails": Structuring GenAI-assisted Hypotheses Exploration with an Interactive Shared Representation
Mar 21, 2025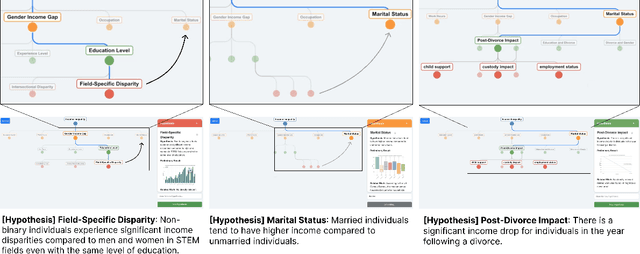
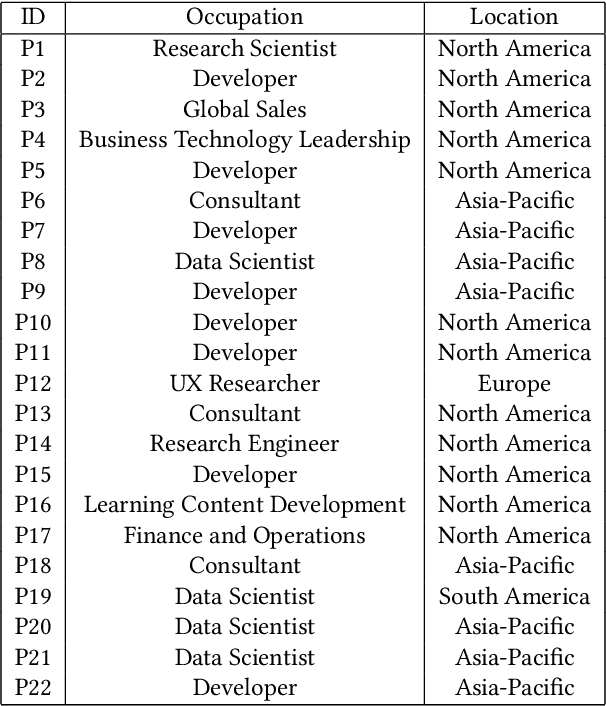
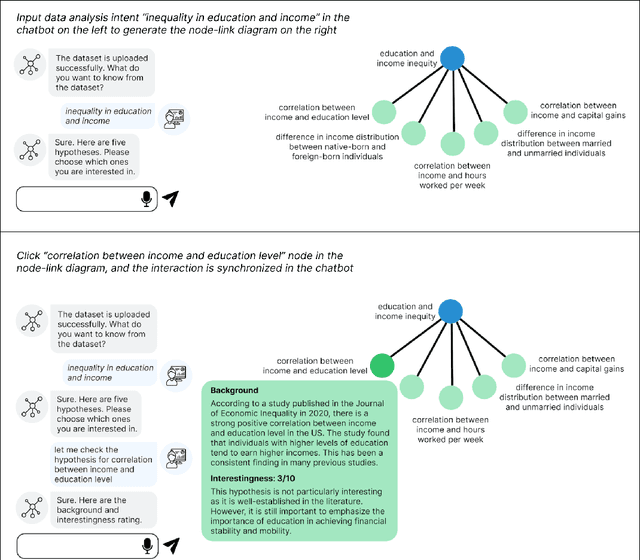
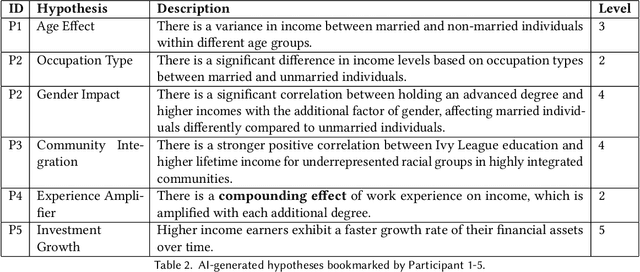
Data analysis encompasses a spectrum of tasks, from high-level conceptual reasoning to lower-level execution. While AI-powered tools increasingly support execution tasks, there remains a need for intelligent assistance in conceptual tasks. This paper investigates the design of an ordered node-link tree interface augmented with AI-generated information hints and visualizations, as a potential shared representation for hypothesis exploration. Through a design probe (n=22), participants generated diagrams averaging 21.82 hypotheses. Our findings showed that the node-link diagram acts as "guardrails" for hypothesis exploration, facilitating structured workflows, providing comprehensive overviews, and enabling efficient backtracking. The AI-generated information hints, particularly visualizations, aided users in transforming abstract ideas into data-backed concepts while reducing cognitive load. We further discuss how node-link diagrams can support both parallel exploration and iterative refinement in hypothesis formulation, potentially enhancing the breadth and depth of human-AI collaborative data analysis.
Intelligent Canvas: Enabling Design-Like Exploratory Visual Data Analysis with Generative AI through Rapid Prototyping, Iteration and Curation
Feb 16, 2024



Complex data analysis inherently seeks unexpected insights through exploratory \re{visual analysis} methods, transcending logical, step-by-step processing. However, \re{existing interfaces such as notebooks and dashboards have limitations in exploration and comparison for visual data analysis}. Addressing these limitations, we introduce a "design-like" intelligent canvas environment integrating generative AI into data analysis, offering rapid prototyping, iteration, and comparative visualization management. Our dual contributions include the integration of generative AI components into a canvas interface, and empirical findings from a user study (N=10) evaluating the effectiveness of the canvas interface.
Imitation of Life: A Search Engine for Biologically Inspired Design
Dec 20, 2023Biologically Inspired Design (BID), or Biomimicry, is a problem-solving methodology that applies analogies from nature to solve engineering challenges. For example, Speedo engineers designed swimsuits based on shark skin. Finding relevant biological solutions for real-world problems poses significant challenges, both due to the limited biological knowledge engineers and designers typically possess and to the limited BID resources. Existing BID datasets are hand-curated and small, and scaling them up requires costly human annotations. In this paper, we introduce BARcode (Biological Analogy Retriever), a search engine for automatically mining bio-inspirations from the web at scale. Using advances in natural language understanding and data programming, BARcode identifies potential inspirations for engineering challenges. Our experiments demonstrate that BARcode can retrieve inspirations that are valuable to engineers and designers tackling real-world problems, as well as recover famous historical BID examples. We release data and code; we view BARcode as a step towards addressing the challenges that have historically hindered the practical application of BID to engineering innovation.
Mapping the Design Space of Interactions in Human-AI Text Co-creation Tasks
Mar 14, 2023Large Language Models (LLMs) have demonstrated impressive text generation capabilities, prompting us to reconsider the future of human-AI co-creation and how humans interact with LLMs. In this paper, we present a spectrum of content generation tasks and their corresponding human-AI interaction patterns. These tasks include: 1) fixed-scope content curation tasks with minimal human-AI interactions, 2) independent creative tasks with precise human-AI interactions, and 3) complex and interdependent creative tasks with iterative human-AI interactions. We encourage the generative AI and HCI research communities to focus on the more complex and interdependent tasks, which require greater levels of human involvement.
Fluid Transformers and Creative Analogies: Exploring Large Language Models' Capacity for Augmenting Cross-Domain Analogical Creativity
Feb 27, 2023



Cross-domain analogical reasoning is a core creative ability that can be challenging for humans. Recent work has shown some proofs-of concept of Large language Models' (LLMs) ability to generate cross-domain analogies. However, the reliability and potential usefulness of this capacity for augmenting human creative work has received little systematic exploration. In this paper, we systematically explore LLMs capacity to augment cross-domain analogical reasoning. Across three studies, we found: 1) LLM-generated cross-domain analogies were frequently judged as helpful in the context of a problem reformulation task (median 4 out of 5 helpfulness rating), and frequently (~80% of cases) led to observable changes in problem formulations, and 2) there was an upper bound of 25% of outputs bring rated as potentially harmful, with a majority due to potentially upsetting content, rather than biased or toxic content. These results demonstrate the potential utility -- and risks -- of LLMs for augmenting cross-domain analogical creativity.
Scaling Creative Inspiration with Fine-Grained Functional Facets of Product Ideas
Feb 19, 2021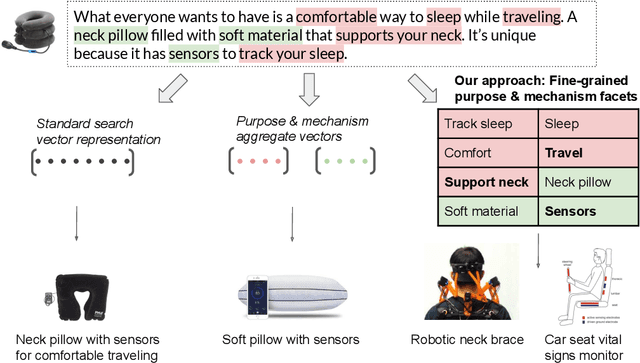
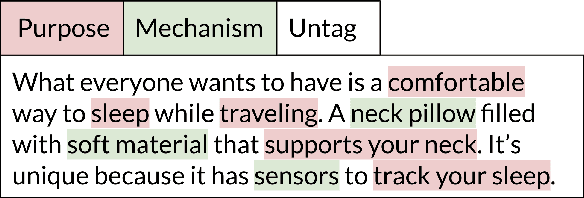

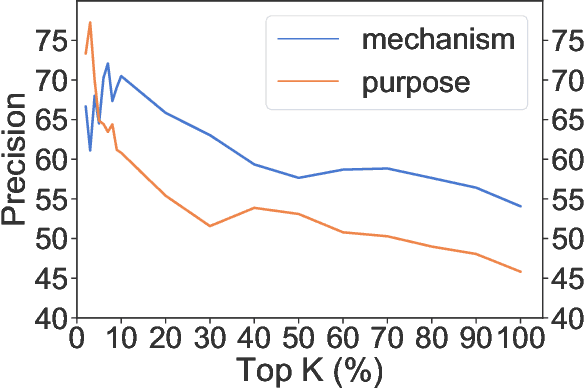
Web-scale repositories of products, patents and scientific papers offer an opportunity for creating automated systems that scour millions of ideas and assist users in discovering inspirations and solutions. Yet the common representation of ideas is in the form of raw textual descriptions, lacking important structure that is required for supporting creative innovation. Prior work has pointed to the importance of functional structure -- capturing the mechanisms and purposes of inventions -- for allowing users to discover structural connections across ideas and creatively adapt existing technologies. However, the use of functional representations was either coarse and limited in expressivity, or dependent on curated knowledge bases with poor coverage and significant manual effort from users. To help bridge this gap and unlock the potential of large-scale idea mining, we propose a novel computational representation that automatically breaks up products into fine-grained functional facets. We train a model to extract these facets from a challenging real-world corpus of invention descriptions, and represent each product as a set of facet embeddings. We design similarity metrics that support granular matching between functional facets across ideas, and use them to build a novel functional search capability that enables expressive queries for mechanisms and purposes. We construct a graph capturing hierarchical relations between purposes and mechanisms across an entire corpus of products, and use the graph to help problem-solvers explore the design space around a focal problem and view related problem perspectives. In empirical user studies, our approach leads to a significant boost in search accuracy and in the quality of creative inspirations, outperforming strong baselines and state-of-art representations of product texts by 50-60%.
ML-based Visualization Recommendation: Learning to Recommend Visualizations from Data
Sep 25, 2020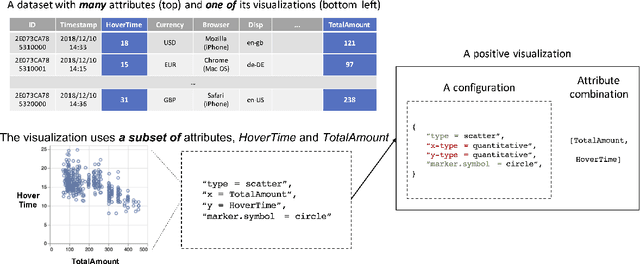

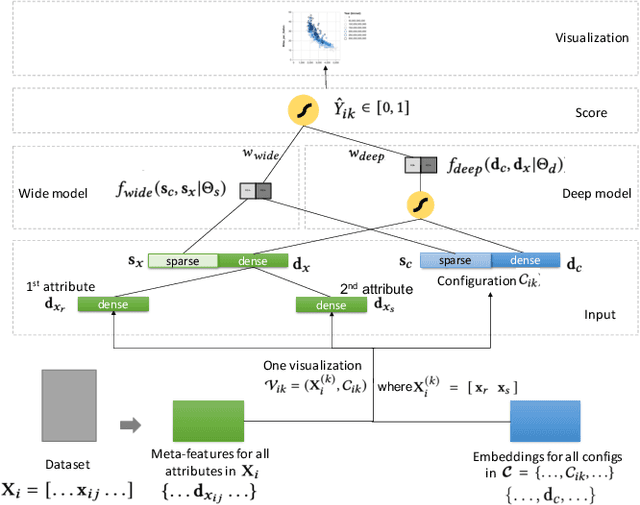
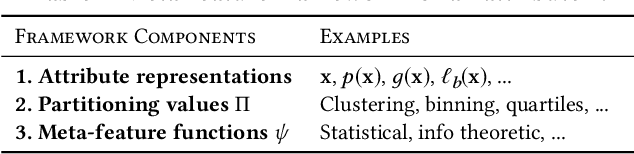
Visualization recommendation seeks to generate, score, and recommend to users useful visualizations automatically, and are fundamentally important for exploring and gaining insights into a new or existing dataset quickly. In this work, we propose the first end-to-end ML-based visualization recommendation system that takes as input a large corpus of datasets and visualizations, learns a model based on this data. Then, given a new unseen dataset from an arbitrary user, the model automatically generates visualizations for that new dataset, derive scores for the visualizations, and output a list of recommended visualizations to the user ordered by effectiveness. We also describe an evaluation framework to quantitatively evaluate visualization recommendation models learned from a large corpus of visualizations and datasets. Through quantitative experiments, a user study, and qualitative analysis, we show that our end-to-end ML-based system recommends more effective and useful visualizations compared to existing state-of-the-art rule-based systems. Finally, we observed a strong preference by the human experts in our user study towards the visualizations recommended by our ML-based system as opposed to the rule-based system (5.92 from a 7-point Likert scale compared to only 3.45).
Analogy Mining for Specific Design Needs
Dec 19, 2017
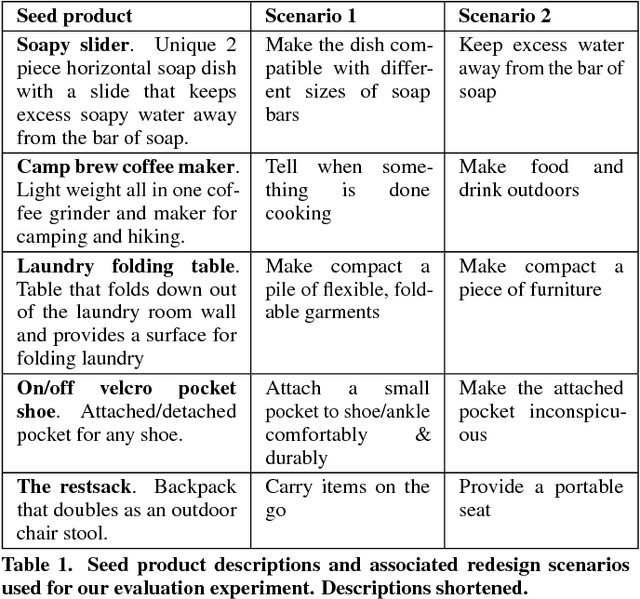


Finding analogical inspirations in distant domains is a powerful way of solving problems. However, as the number of inspirations that could be matched and the dimensions on which that matching could occur grow, it becomes challenging for designers to find inspirations relevant to their needs. Furthermore, designers are often interested in exploring specific aspects of a product-- for example, one designer might be interested in improving the brewing capability of an outdoor coffee maker, while another might wish to optimize for portability. In this paper we introduce a novel system for targeting analogical search for specific needs. Specifically, we contribute a novel analogical search engine for expressing and abstracting specific design needs that returns more distant yet relevant inspirations than alternate approaches.
Accelerating Innovation Through Analogy Mining
Jun 17, 2017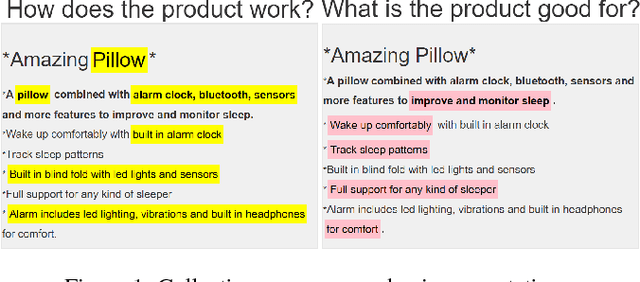

The availability of large idea repositories (e.g., the U.S. patent database) could significantly accelerate innovation and discovery by providing people with inspiration from solutions to analogous problems. However, finding useful analogies in these large, messy, real-world repositories remains a persistent challenge for either human or automated methods. Previous approaches include costly hand-created databases that have high relational structure (e.g., predicate calculus representations) but are very sparse. Simpler machine-learning/information-retrieval similarity metrics can scale to large, natural-language datasets, but struggle to account for structural similarity, which is central to analogy. In this paper we explore the viability and value of learning simpler structural representations, specifically, "problem schemas", which specify the purpose of a product and the mechanisms by which it achieves that purpose. Our approach combines crowdsourcing and recurrent neural networks to extract purpose and mechanism vector representations from product descriptions. We demonstrate that these learned vectors allow us to find analogies with higher precision and recall than traditional information-retrieval methods. In an ideation experiment, analogies retrieved by our models significantly increased people's likelihood of generating creative ideas compared to analogies retrieved by traditional methods. Our results suggest a promising approach to enabling computational analogy at scale is to learn and leverage weaker structural representations.