 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChart-to-Experience: Benchmarking Multimodal LLMs for Predicting Experiential Impact of Charts
May 23, 2025
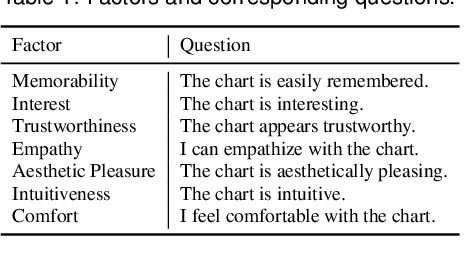

The field of Multimodal Large Language Models (MLLMs) has made remarkable progress in visual understanding tasks, presenting a vast opportunity to predict the perceptual and emotional impact of charts. However, it also raises concerns, as many applications of LLMs are based on overgeneralized assumptions from a few examples, lacking sufficient validation of their performance and effectiveness. We introduce Chart-to-Experience, a benchmark dataset comprising 36 charts, evaluated by crowdsourced workers for their impact on seven experiential factors. Using the dataset as ground truth, we evaluated capabilities of state-of-the-art MLLMs on two tasks: direct prediction and pairwise comparison of charts. Our findings imply that MLLMs are not as sensitive as human evaluators when assessing individual charts, but are accurate and reliable in pairwise comparisons.
Optimizing Data Delivery: Insights from User Preferences on Visuals, Tables, and Text
Nov 12, 2024

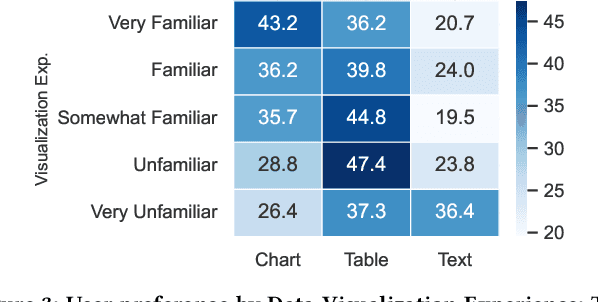

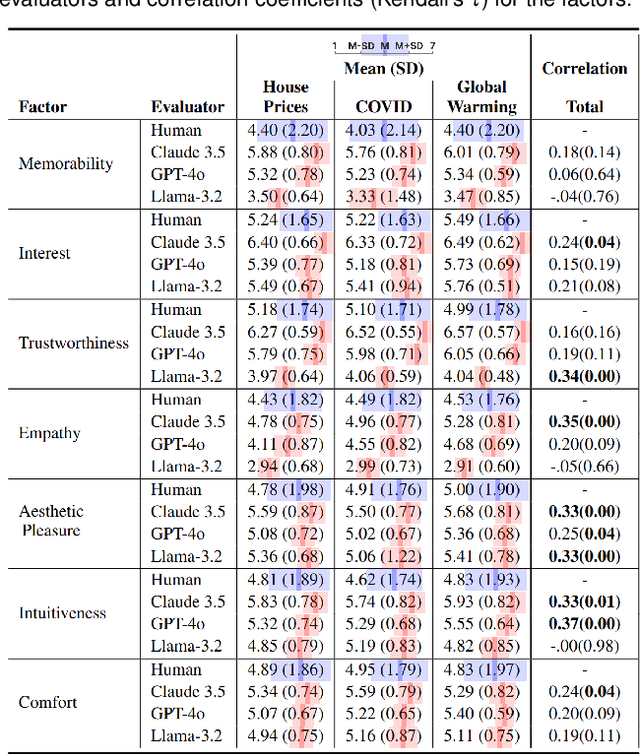
In this work, we research user preferences to see a chart, table, or text given a question asked by the user. This enables us to understand when it is best to show a chart, table, or text to the user for the specific question. For this, we conduct a user study where users are shown a question and asked what they would prefer to see and used the data to establish that a user's personal traits does influence the data outputs that they prefer. Understanding how user characteristics impact a user's preferences is critical to creating data tools with a better user experience. Additionally, we investigate to what degree an LLM can be used to replicate a user's preference with and without user preference data. Overall, these findings have significant implications pertaining to the development of data tools and the replication of human preferences using LLMs. Furthermore, this work demonstrates the potential use of LLMs to replicate user preference data which has major implications for future user modeling and personalization research.
LLM-Driven Learning Analytics Dashboard for Teachers in EFL Writing Education
Oct 19, 2024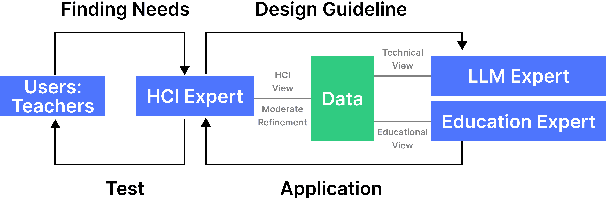
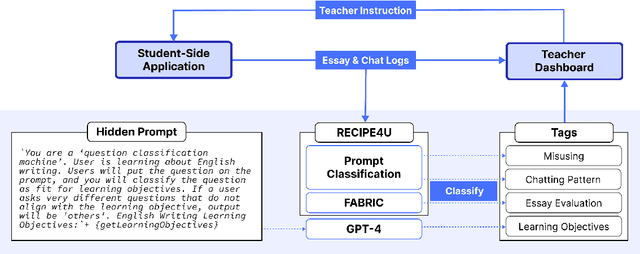
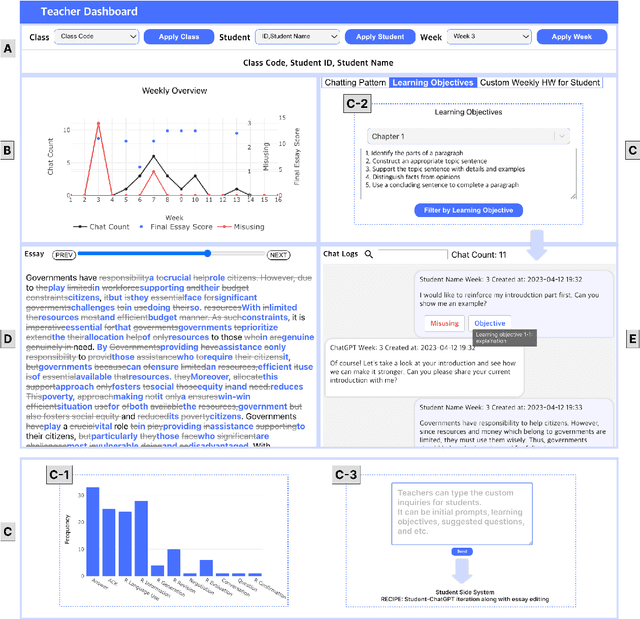
This paper presents the development of a dashboard designed specifically for teachers in English as a Foreign Language (EFL) writing education. Leveraging LLMs, the dashboard facilitates the analysis of student interactions with an essay writing system, which integrates ChatGPT for real-time feedback. The dashboard aids teachers in monitoring student behavior, identifying noneducational interaction with ChatGPT, and aligning instructional strategies with learning objectives. By combining insights from NLP and Human-Computer Interaction (HCI), this study demonstrates how a human-centered approach can enhance the effectiveness of teacher dashboards, particularly in ChatGPT-integrated learning.
RECIPE4U: Student-ChatGPT Interaction Dataset in EFL Writing Education
Mar 13, 2024
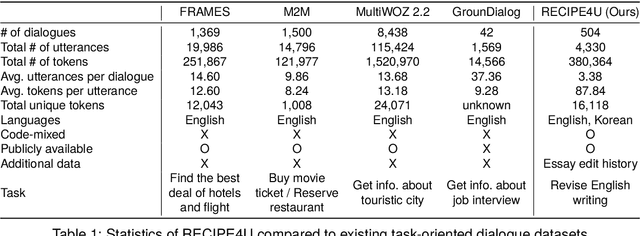
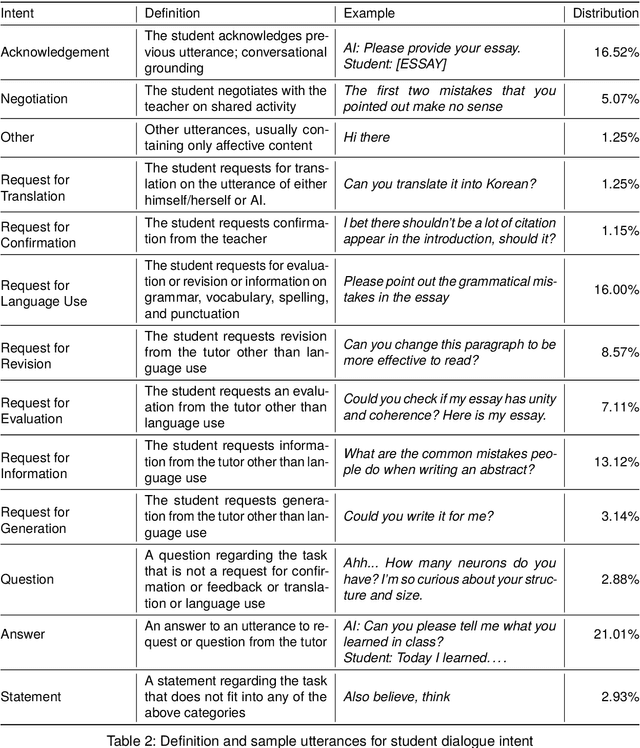
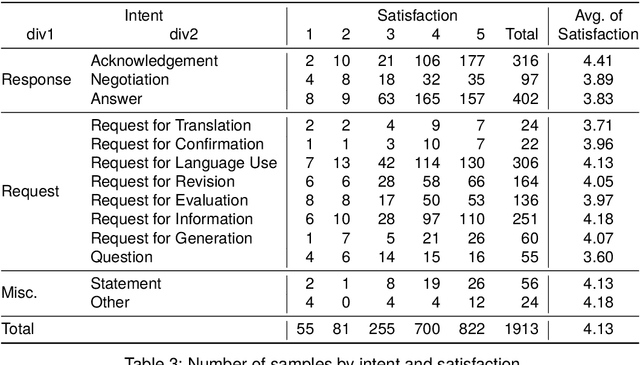
The integration of generative AI in education is expanding, yet empirical analyses of large-scale and real-world interactions between students and AI systems still remain limited. Addressing this gap, we present RECIPE4U (RECIPE for University), a dataset sourced from a semester-long experiment with 212 college students in English as Foreign Language (EFL) writing courses. During the study, students engaged in dialogues with ChatGPT to revise their essays. RECIPE4U includes comprehensive records of these interactions, including conversation logs, students' intent, students' self-rated satisfaction, and students' essay edit histories. In particular, we annotate the students' utterances in RECIPE4U with 13 intention labels based on our coding schemes. We establish baseline results for two subtasks in task-oriented dialogue systems within educational contexts: intent detection and satisfaction estimation. As a foundational step, we explore student-ChatGPT interaction patterns through RECIPE4U and analyze them by focusing on students' dialogue, essay data statistics, and students' essay edits. We further illustrate potential applications of RECIPE4U dataset for enhancing the incorporation of LLMs in educational frameworks. RECIPE4U is publicly available at https://zeunie.github.io/RECIPE4U/.
FABRIC: Automated Scoring and Feedback Generation for Essays
Oct 08, 2023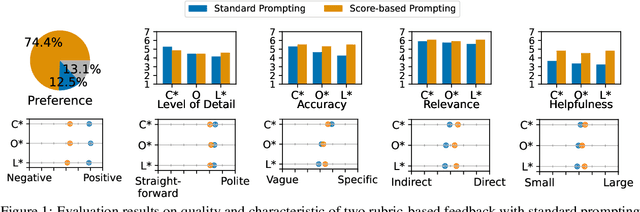
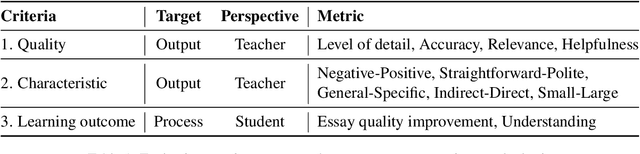
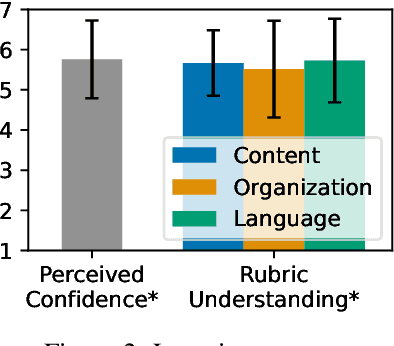
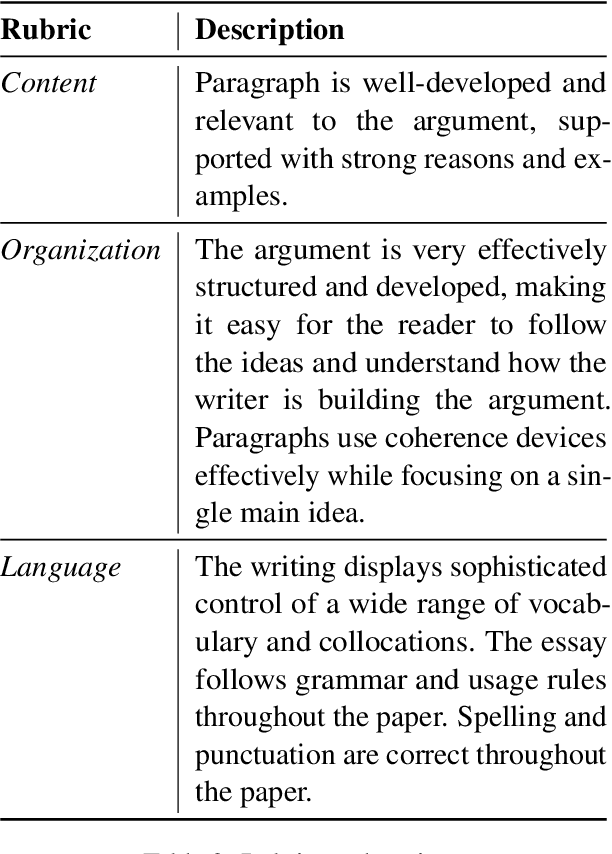
Automated essay scoring (AES) provides a useful tool for students and instructors in writing classes by generating essay scores in real-time. However, previous AES models do not provide more specific rubric-based scores nor feedback on how to improve the essays, which can be even more important than the overall scores for learning. We present FABRIC, a pipeline to help students and instructors in English writing classes by automatically generating 1) the overall scores, 2) specific rubric-based scores, and 3) detailed feedback on how to improve the essays. Under the guidance of English education experts, we chose the rubrics for the specific scores as content, organization, and language. The first component of the FABRIC pipeline is DREsS, a real-world Dataset for Rubric-based Essay Scoring (DREsS). The second component is CASE, a Corruption-based Augmentation Strategy for Essays, with which we can improve the accuracy of the baseline model by 45.44%. The third component is EssayCoT, the Essay Chain-of-Thought prompting strategy which uses scores predicted from the AES model to generate better feedback. We evaluate the effectiveness of the new dataset DREsS and the augmentation strategy CASE quantitatively and show significant improvements over the models trained with existing datasets. We evaluate the feedback generated by EssayCoT with English education experts to show significant improvements in the helpfulness of the feedback across all rubrics. Lastly, we evaluate the FABRIC pipeline with students in a college English writing class who rated the generated scores and feedback with an average of 6 on the Likert scale from 1 to 7.
ChEDDAR: Student-ChatGPT Dialogue in EFL Writing Education
Sep 23, 2023


The integration of generative AI in education is expanding, yet empirical analyses of large-scale, real-world interactions between students and AI systems still remain limited. In this study, we present ChEDDAR, ChatGPT & EFL Learner's Dialogue Dataset As Revising an essay, which is collected from a semester-long longitudinal experiment involving 212 college students enrolled in English as Foreign Langauge (EFL) writing courses. The students were asked to revise their essays through dialogues with ChatGPT. ChEDDAR includes a conversation log, utterance-level essay edit history, self-rated satisfaction, and students' intent, in addition to session-level pre-and-post surveys documenting their objectives and overall experiences. We analyze students' usage patterns and perceptions regarding generative AI with respect to their intent and satisfaction. As a foundational step, we establish baseline results for two pivotal tasks in task-oriented dialogue systems within educational contexts: intent detection and satisfaction estimation. We finally suggest further research to refine the integration of generative AI into education settings, outlining potential scenarios utilizing ChEDDAR. ChEDDAR is publicly available at https://github.com/zeunie/ChEDDAR.
Insight-centric Visualization Recommendation
Mar 21, 2021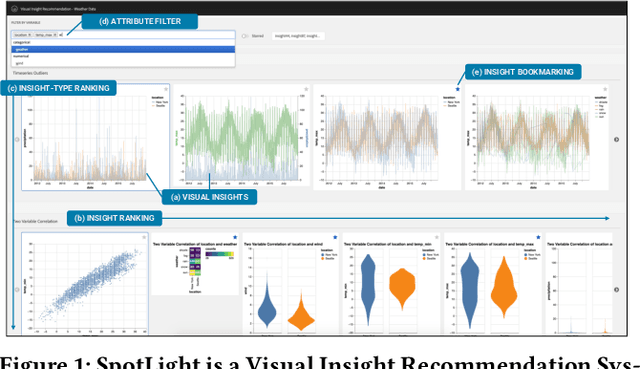
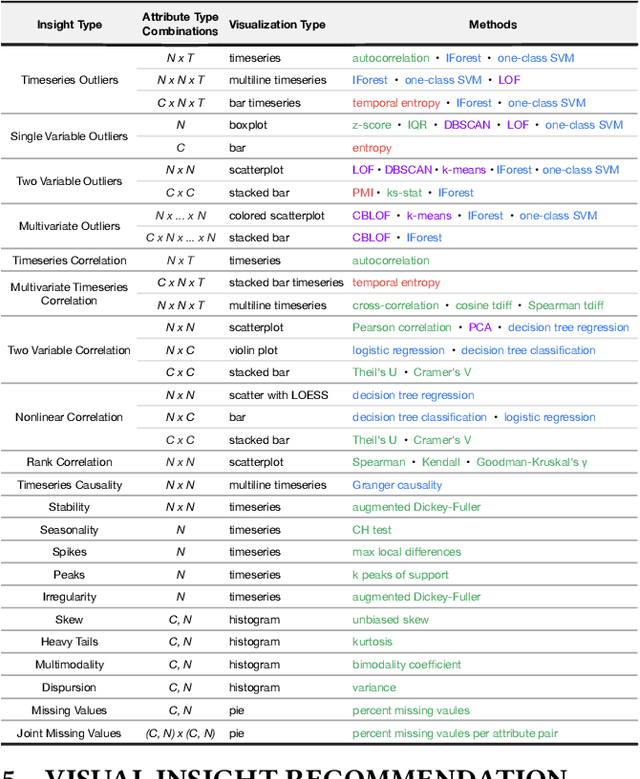
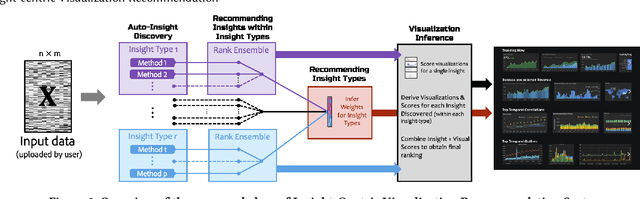
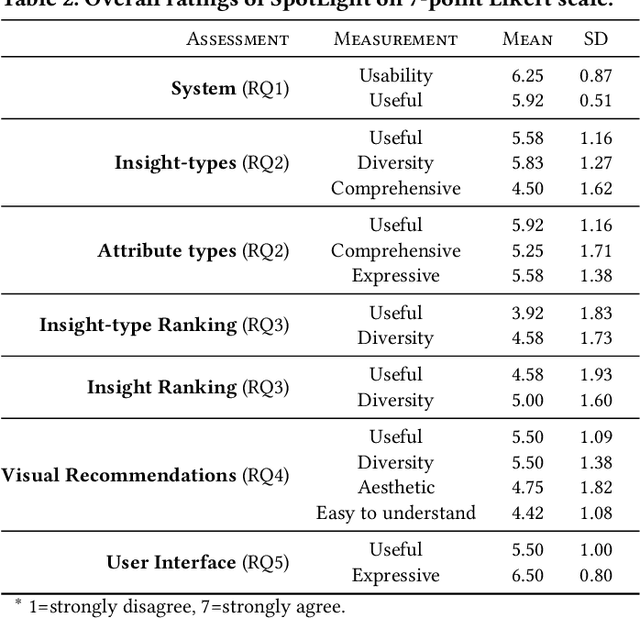
Visualization recommendation systems simplify exploratory data analysis (EDA) and make understanding data more accessible to users of all skill levels by automatically generating visualizations for users to explore. However, most existing visualization recommendation systems focus on ranking all visualizations into a single list or set of groups based on particular attributes or encodings. This global ranking makes it difficult and time-consuming for users to find the most interesting or relevant insights. To address these limitations, we introduce a novel class of visualization recommendation systems that automatically rank and recommend both groups of related insights as well as the most important insights within each group. Our proposed approach combines results from many different learning-based methods to discover insights automatically. A key advantage is that this approach generalizes to a wide variety of attribute types such as categorical, numerical, and temporal, as well as complex non-trivial combinations of these different attribute types. To evaluate the effectiveness of our approach, we implemented a new insight-centric visualization recommendation system, SpotLight, which generates and ranks annotated visualizations to explain each insight. We conducted a user study with 12 participants and two datasets which showed that users are able to quickly understand and find relevant insights in unfamiliar data.
Personalized Visualization Recommendation
Feb 12, 2021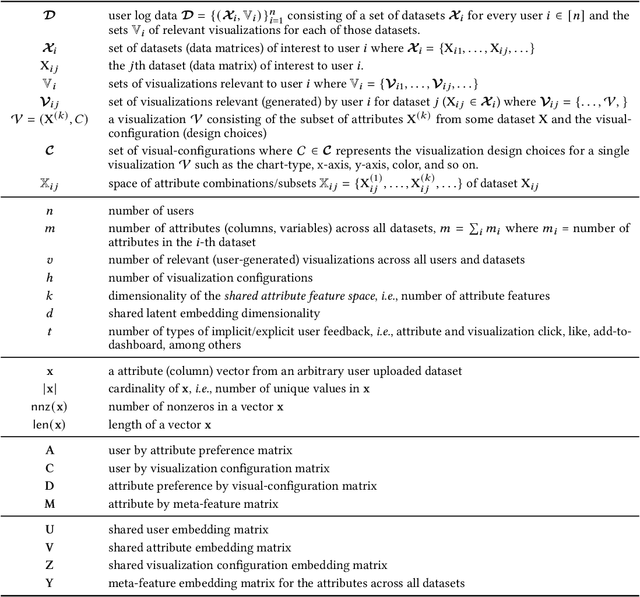
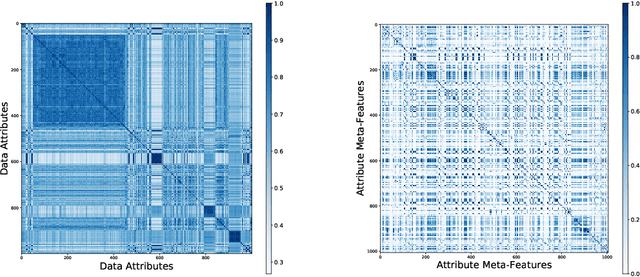

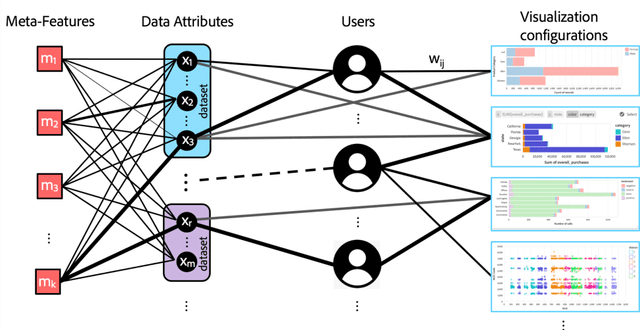
Visualization recommendation work has focused solely on scoring visualizations based on the underlying dataset and not the actual user and their past visualization feedback. These systems recommend the same visualizations for every user, despite that the underlying user interests, intent, and visualization preferences are likely to be fundamentally different, yet vitally important. In this work, we formally introduce the problem of personalized visualization recommendation and present a generic learning framework for solving it. In particular, we focus on recommending visualizations personalized for each individual user based on their past visualization interactions (e.g., viewed, clicked, manually created) along with the data from those visualizations. More importantly, the framework can learn from visualizations relevant to other users, even if the visualizations are generated from completely different datasets. Experiments demonstrate the effectiveness of the approach as it leads to higher quality visualization recommendations tailored to the specific user intent and preferences. To support research on this new problem, we release our user-centric visualization corpus consisting of 17.4k users exploring 94k datasets with 2.3 million attributes and 32k user-generated visualizations.
ML-based Visualization Recommendation: Learning to Recommend Visualizations from Data
Sep 25, 2020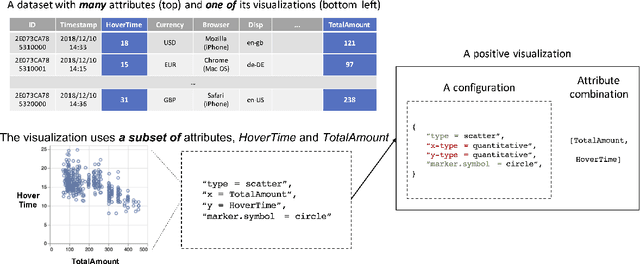

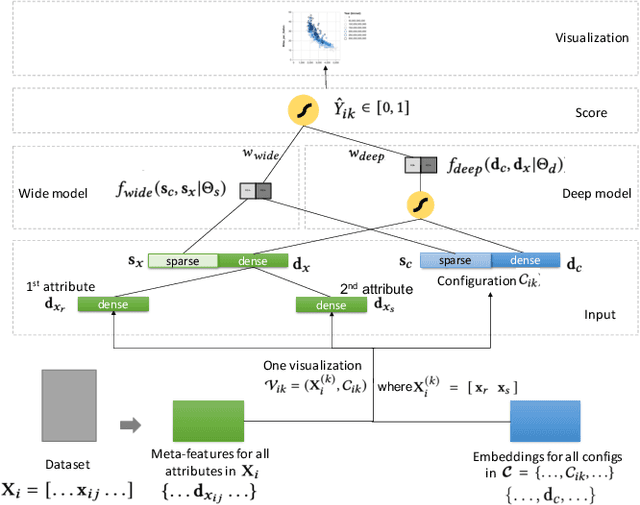
Visualization recommendation seeks to generate, score, and recommend to users useful visualizations automatically, and are fundamentally important for exploring and gaining insights into a new or existing dataset quickly. In this work, we propose the first end-to-end ML-based visualization recommendation system that takes as input a large corpus of datasets and visualizations, learns a model based on this data. Then, given a new unseen dataset from an arbitrary user, the model automatically generates visualizations for that new dataset, derive scores for the visualizations, and output a list of recommended visualizations to the user ordered by effectiveness. We also describe an evaluation framework to quantitatively evaluate visualization recommendation models learned from a large corpus of visualizations and datasets. Through quantitative experiments, a user study, and qualitative analysis, we show that our end-to-end ML-based system recommends more effective and useful visualizations compared to existing state-of-the-art rule-based systems. Finally, we observed a strong preference by the human experts in our user study towards the visualizations recommended by our ML-based system as opposed to the rule-based system (5.92 from a 7-point Likert scale compared to only 3.45).