 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-Driven Learning Analytics Dashboard for Teachers in EFL Writing Education
Oct 19, 2024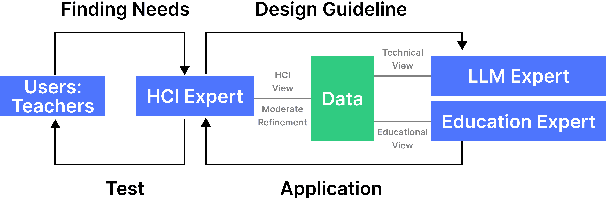
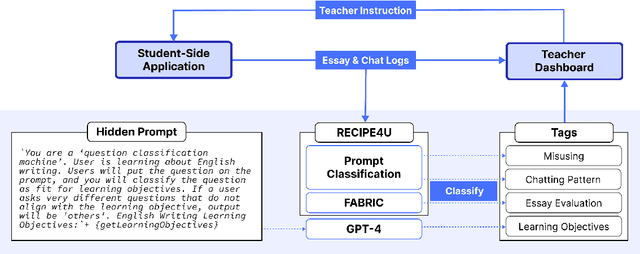
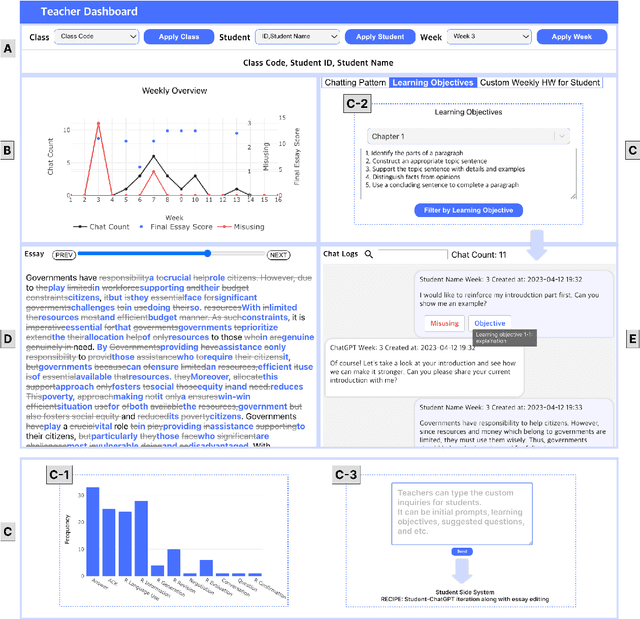
This paper presents the development of a dashboard designed specifically for teachers in English as a Foreign Language (EFL) writing education. Leveraging LLMs, the dashboard facilitates the analysis of student interactions with an essay writing system, which integrates ChatGPT for real-time feedback. The dashboard aids teachers in monitoring student behavior, identifying noneducational interaction with ChatGPT, and aligning instructional strategies with learning objectives. By combining insights from NLP and Human-Computer Interaction (HCI), this study demonstrates how a human-centered approach can enhance the effectiveness of teacher dashboards, particularly in ChatGPT-integrated learning.
RECIPE4U: Student-ChatGPT Interaction Dataset in EFL Writing Education
Mar 13, 2024
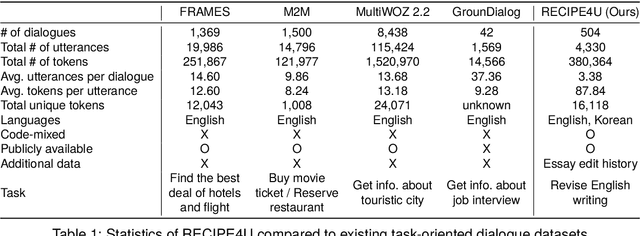
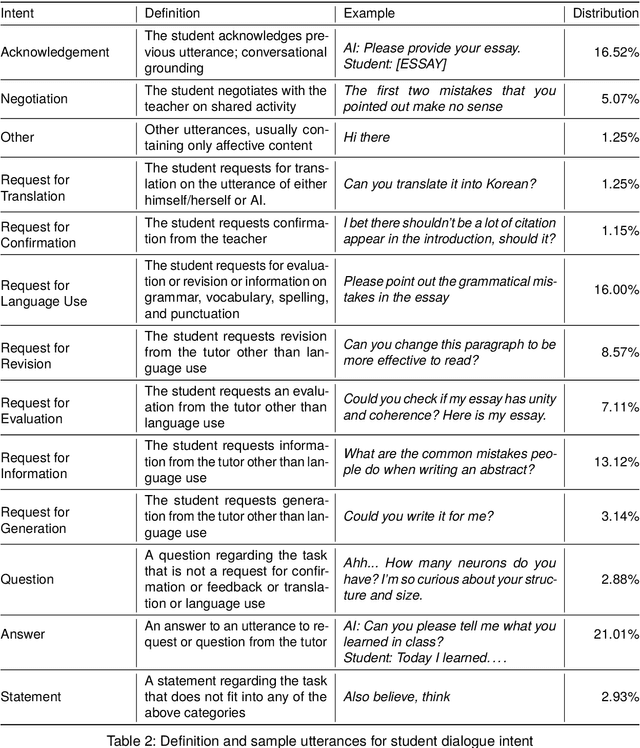
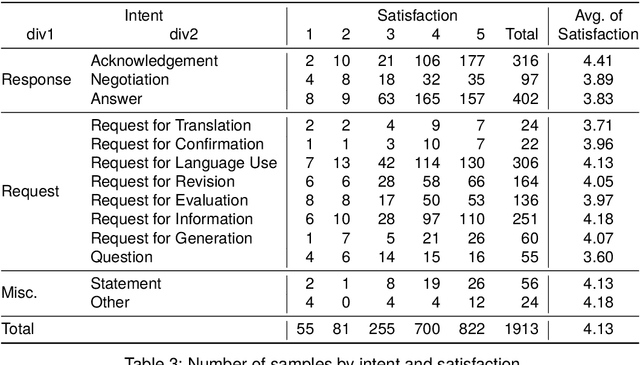
The integration of generative AI in education is expanding, yet empirical analyses of large-scale and real-world interactions between students and AI systems still remain limited. Addressing this gap, we present RECIPE4U (RECIPE for University), a dataset sourced from a semester-long experiment with 212 college students in English as Foreign Language (EFL) writing courses. During the study, students engaged in dialogues with ChatGPT to revise their essays. RECIPE4U includes comprehensive records of these interactions, including conversation logs, students' intent, students' self-rated satisfaction, and students' essay edit histories. In particular, we annotate the students' utterances in RECIPE4U with 13 intention labels based on our coding schemes. We establish baseline results for two subtasks in task-oriented dialogue systems within educational contexts: intent detection and satisfaction estimation. As a foundational step, we explore student-ChatGPT interaction patterns through RECIPE4U and analyze them by focusing on students' dialogue, essay data statistics, and students' essay edits. We further illustrate potential applications of RECIPE4U dataset for enhancing the incorporation of LLMs in educational frameworks. RECIPE4U is publicly available at https://zeunie.github.io/RECIPE4U/.
FABRIC: Automated Scoring and Feedback Generation for Essays
Oct 08, 2023
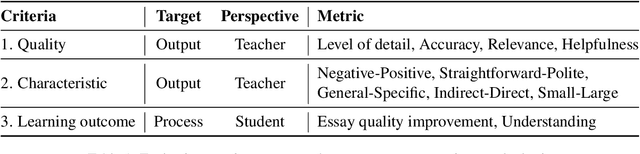
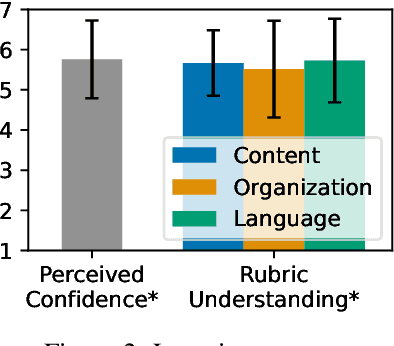
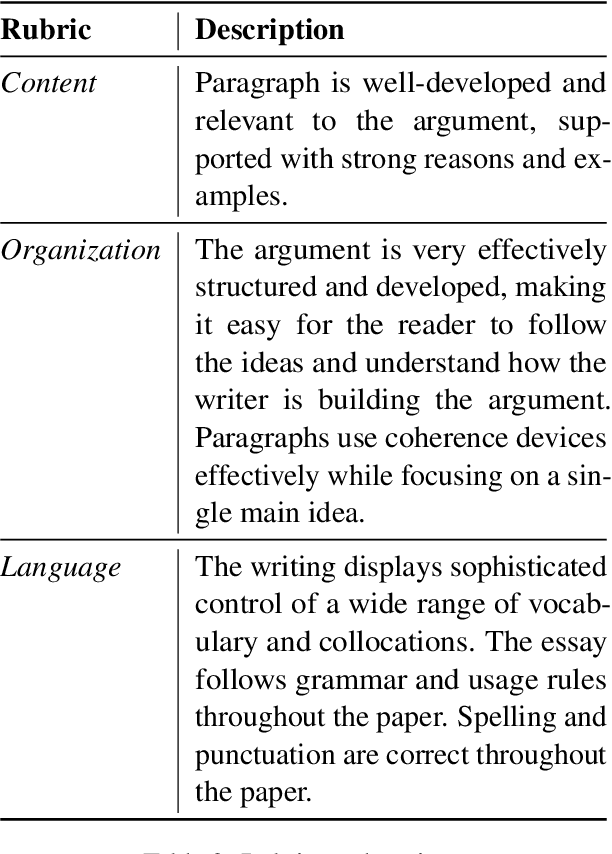
Automated essay scoring (AES) provides a useful tool for students and instructors in writing classes by generating essay scores in real-time. However, previous AES models do not provide more specific rubric-based scores nor feedback on how to improve the essays, which can be even more important than the overall scores for learning. We present FABRIC, a pipeline to help students and instructors in English writing classes by automatically generating 1) the overall scores, 2) specific rubric-based scores, and 3) detailed feedback on how to improve the essays. Under the guidance of English education experts, we chose the rubrics for the specific scores as content, organization, and language. The first component of the FABRIC pipeline is DREsS, a real-world Dataset for Rubric-based Essay Scoring (DREsS). The second component is CASE, a Corruption-based Augmentation Strategy for Essays, with which we can improve the accuracy of the baseline model by 45.44%. The third component is EssayCoT, the Essay Chain-of-Thought prompting strategy which uses scores predicted from the AES model to generate better feedback. We evaluate the effectiveness of the new dataset DREsS and the augmentation strategy CASE quantitatively and show significant improvements over the models trained with existing datasets. We evaluate the feedback generated by EssayCoT with English education experts to show significant improvements in the helpfulness of the feedback across all rubrics. Lastly, we evaluate the FABRIC pipeline with students in a college English writing class who rated the generated scores and feedback with an average of 6 on the Likert scale from 1 to 7.
ChEDDAR: Student-ChatGPT Dialogue in EFL Writing Education
Sep 23, 2023


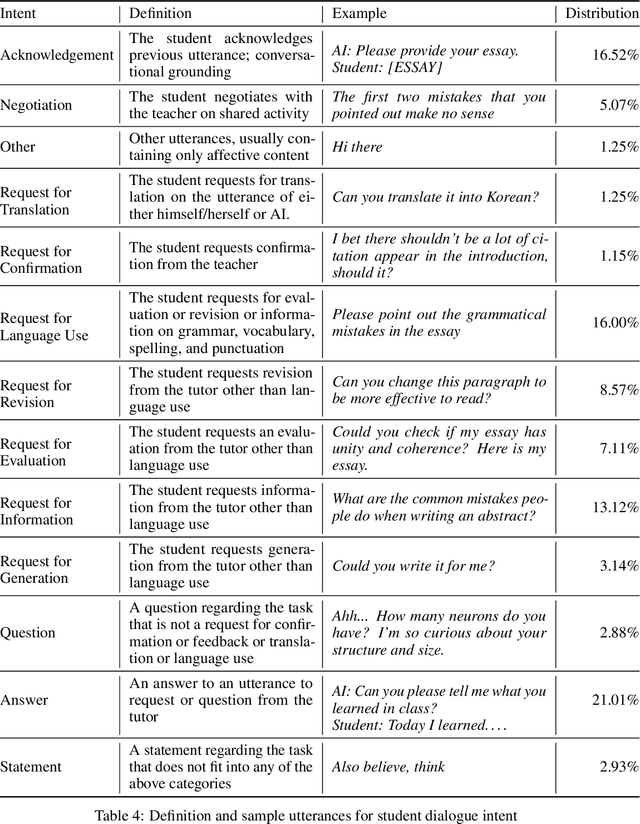
The integration of generative AI in education is expanding, yet empirical analyses of large-scale, real-world interactions between students and AI systems still remain limited. In this study, we present ChEDDAR, ChatGPT & EFL Learner's Dialogue Dataset As Revising an essay, which is collected from a semester-long longitudinal experiment involving 212 college students enrolled in English as Foreign Langauge (EFL) writing courses. The students were asked to revise their essays through dialogues with ChatGPT. ChEDDAR includes a conversation log, utterance-level essay edit history, self-rated satisfaction, and students' intent, in addition to session-level pre-and-post surveys documenting their objectives and overall experiences. We analyze students' usage patterns and perceptions regarding generative AI with respect to their intent and satisfaction. As a foundational step, we establish baseline results for two pivotal tasks in task-oriented dialogue systems within educational contexts: intent detection and satisfaction estimation. We finally suggest further research to refine the integration of generative AI into education settings, outlining potential scenarios utilizing ChEDDAR. ChEDDAR is publicly available at https://github.com/zeunie/ChEDDAR.
A feasibility study of a hyperparameter tuning approach to automated inverse planning in radiotherapy
May 14, 2021
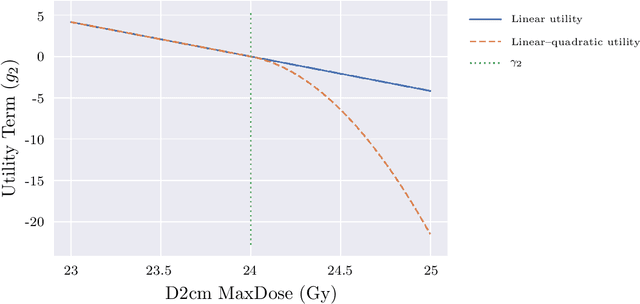
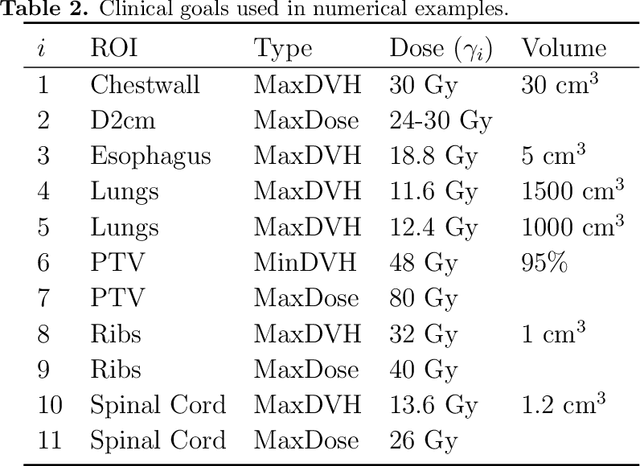
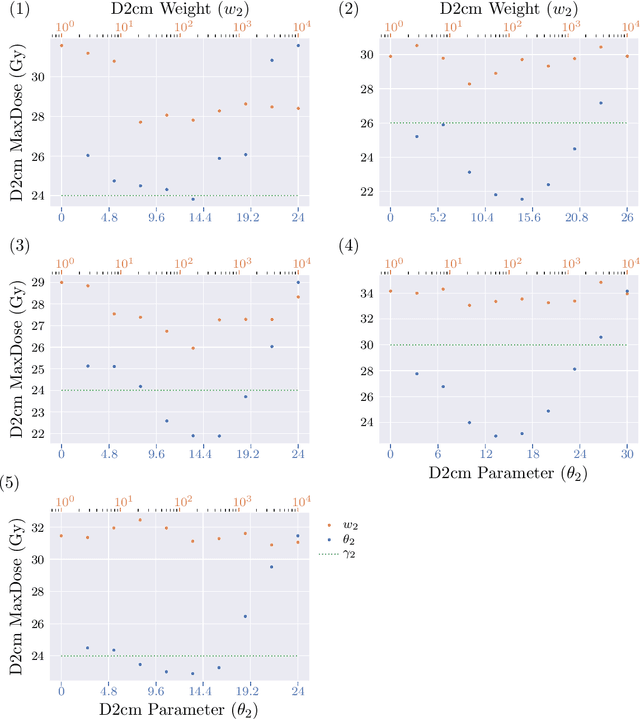
Radiotherapy inverse planning requires treatment planners to modify multiple parameters in the objective function to produce clinically acceptable plans. Due to manual steps in this process, plan quality can vary widely depending on planning time available and planner's skills. The purpose of this study is to automate the inverse planning process to reduce active planning time while maintaining plan quality. We propose a hyperparameter tuning approach for automated inverse planning, where a treatment plan utility is maximized with respect to the limit dose parameters and weights of each organ-at-risk (OAR) objective. Using 6 patient cases, we investigated the impact of the choice of dose parameters, random and Bayesian search methods, and utility function form on planning time and plan quality. For given parameters, the plan was optimized in RayStation, using the scripting interface to obtain the dose distributions deliverable. We normalized all plans to have the same target coverage and compared the OAR dose metrics in the automatically generated plans with those in the manually generated clinical plans. Using 100 samples was found to produce satisfactory plan quality, and the average planning time was 2.3 hours. The OAR doses in the automatically generated plans were lower than the clinical plans by up to 76.8%. When the OAR doses were larger than the clinical plans, they were still between 0.57% above and 98.9% below the limit doses, indicating they are clinically acceptable. For a challenging case, a dimensionality reduction strategy produced a 92.9% higher utility using only 38.5% of the time needed to optimize over the original problem. This study demonstrates our hyperparameter tuning framework for automated inverse planning can significantly reduce the treatment planner's planning time with plan quality that is similar to or better than manually generated plans.