 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"When to Hand Off, When to Work Together": Expanding Human-Agent Co-Creative Collaboration through Concurrent Interaction
Mar 02, 2026Human collaborators coordinate dynamically through process visibility and workspace awareness, yet AI agents typically either provide only final outputs or expose read-only execution processes (e.g., planning, reasoning) without interpreting concurrent user actions on shared artifacts. Building on mixed-initiative interaction principles, we explore whether agents can achieve collaborative context awareness -- interpreting concurrent user actions on shared artifacts and adapting in real-time. Study 1 (N=10 professional designers) revealed that process visibility enabled reasoning about agent actions but exposed conflicts when agents could not distinguish feedback from independent work. We developed CLEO, which interprets collaborative intent and adapts in real-time. Study 2 (N=10, two-day with stimulated recall interviews) analyzed 214 turns, identifying five action patterns, six triggers, and four enabling factors explaining when designers choose delegation (70.1%), direction (28.5%), or concurrent work (31.8%). We present a decision model with six interaction loops, design implications, and an annotated dataset.
LLM-Driven Learning Analytics Dashboard for Teachers in EFL Writing Education
Oct 19, 2024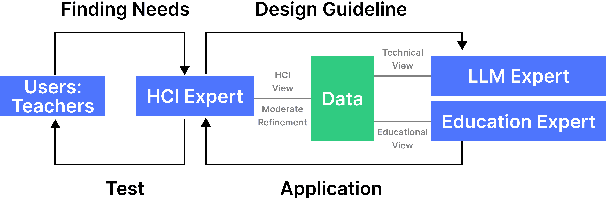
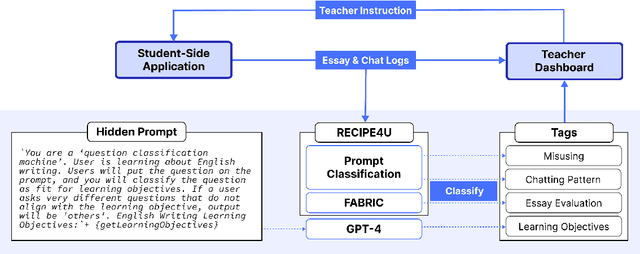
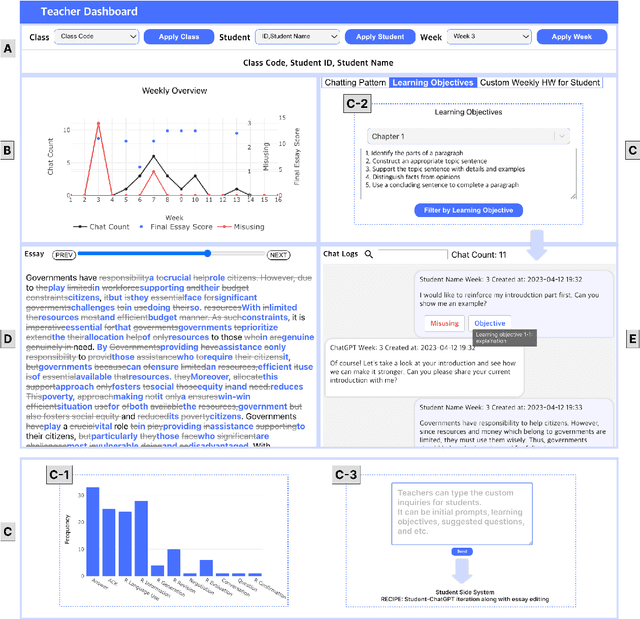
This paper presents the development of a dashboard designed specifically for teachers in English as a Foreign Language (EFL) writing education. Leveraging LLMs, the dashboard facilitates the analysis of student interactions with an essay writing system, which integrates ChatGPT for real-time feedback. The dashboard aids teachers in monitoring student behavior, identifying noneducational interaction with ChatGPT, and aligning instructional strategies with learning objectives. By combining insights from NLP and Human-Computer Interaction (HCI), this study demonstrates how a human-centered approach can enhance the effectiveness of teacher dashboards, particularly in ChatGPT-integrated learning.
Beyond Prompts: Learning from Human Communication for Enhanced AI Intent Alignment
May 09, 2024AI intent alignment, ensuring that AI produces outcomes as intended by users, is a critical challenge in human-AI interaction. The emergence of generative AI, including LLMs, has intensified the significance of this problem, as interactions increasingly involve users specifying desired results for AI systems. In order to support better AI intent alignment, we aim to explore human strategies for intent specification in human-human communication. By studying and comparing human-human and human-LLM communication, we identify key strategies that can be applied to the design of AI systems that are more effective at understanding and aligning with user intent. This study aims to advance toward a human-centered AI system by bringing together human communication strategies for the design of AI systems.
FABRIC: Automated Scoring and Feedback Generation for Essays
Oct 08, 2023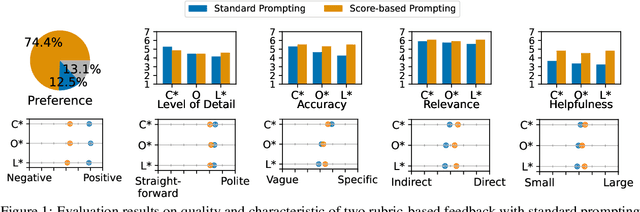
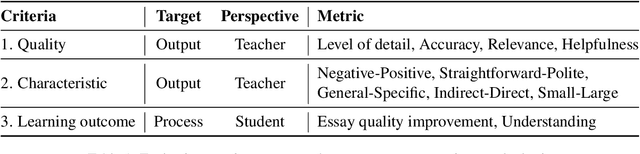
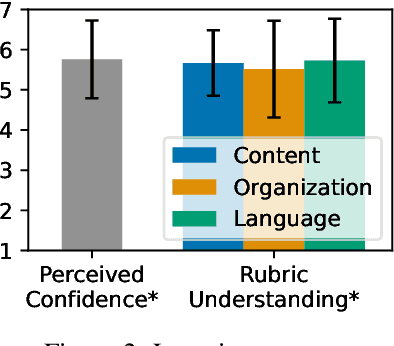
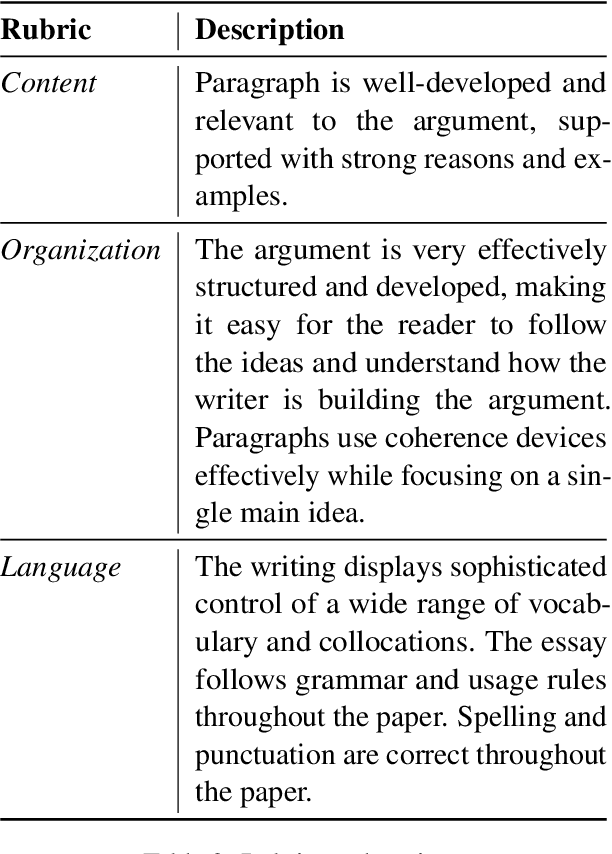
Automated essay scoring (AES) provides a useful tool for students and instructors in writing classes by generating essay scores in real-time. However, previous AES models do not provide more specific rubric-based scores nor feedback on how to improve the essays, which can be even more important than the overall scores for learning. We present FABRIC, a pipeline to help students and instructors in English writing classes by automatically generating 1) the overall scores, 2) specific rubric-based scores, and 3) detailed feedback on how to improve the essays. Under the guidance of English education experts, we chose the rubrics for the specific scores as content, organization, and language. The first component of the FABRIC pipeline is DREsS, a real-world Dataset for Rubric-based Essay Scoring (DREsS). The second component is CASE, a Corruption-based Augmentation Strategy for Essays, with which we can improve the accuracy of the baseline model by 45.44%. The third component is EssayCoT, the Essay Chain-of-Thought prompting strategy which uses scores predicted from the AES model to generate better feedback. We evaluate the effectiveness of the new dataset DREsS and the augmentation strategy CASE quantitatively and show significant improvements over the models trained with existing datasets. We evaluate the feedback generated by EssayCoT with English education experts to show significant improvements in the helpfulness of the feedback across all rubrics. Lastly, we evaluate the FABRIC pipeline with students in a college English writing class who rated the generated scores and feedback with an average of 6 on the Likert scale from 1 to 7.