 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne-Topic-Doesn't-Fit-All: Transcreating Reading Comprehension Test for Personalized Learning
Nov 12, 2025


Personalized learning has gained attention in English as a Foreign Language (EFL) education, where engagement and motivation play crucial roles in reading comprehension. We propose a novel approach to generating personalized English reading comprehension tests tailored to students' interests. We develop a structured content transcreation pipeline using OpenAI's gpt-4o, where we start with the RACE-C dataset, and generate new passages and multiple-choice reading comprehension questions that are linguistically similar to the original passages but semantically aligned with individual learners' interests. Our methodology integrates topic extraction, question classification based on Bloom's taxonomy, linguistic feature analysis, and content transcreation to enhance student engagement. We conduct a controlled experiment with EFL learners in South Korea to examine the impact of interest-aligned reading materials on comprehension and motivation. Our results show students learning with personalized reading passages demonstrate improved comprehension and motivation retention compared to those learning with non-personalized materials.
LLM-Driven Learning Analytics Dashboard for Teachers in EFL Writing Education
Oct 19, 2024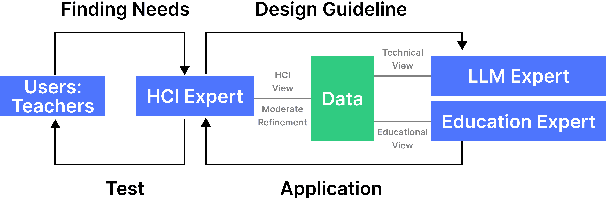
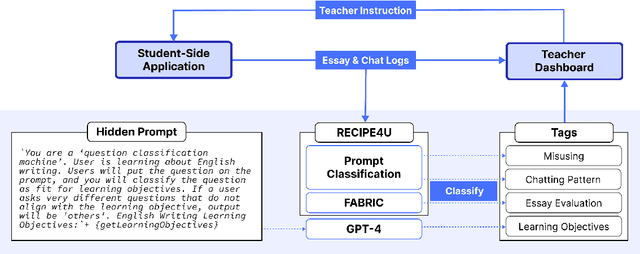
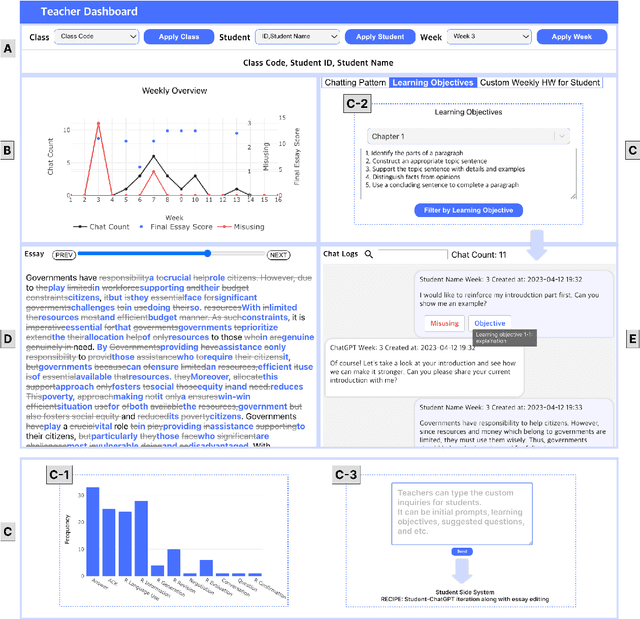
This paper presents the development of a dashboard designed specifically for teachers in English as a Foreign Language (EFL) writing education. Leveraging LLMs, the dashboard facilitates the analysis of student interactions with an essay writing system, which integrates ChatGPT for real-time feedback. The dashboard aids teachers in monitoring student behavior, identifying noneducational interaction with ChatGPT, and aligning instructional strategies with learning objectives. By combining insights from NLP and Human-Computer Interaction (HCI), this study demonstrates how a human-centered approach can enhance the effectiveness of teacher dashboards, particularly in ChatGPT-integrated learning.
RECIPE4U: Student-ChatGPT Interaction Dataset in EFL Writing Education
Mar 13, 2024
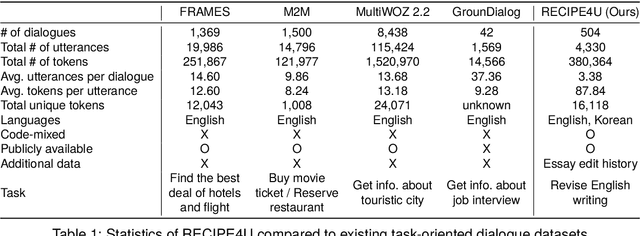
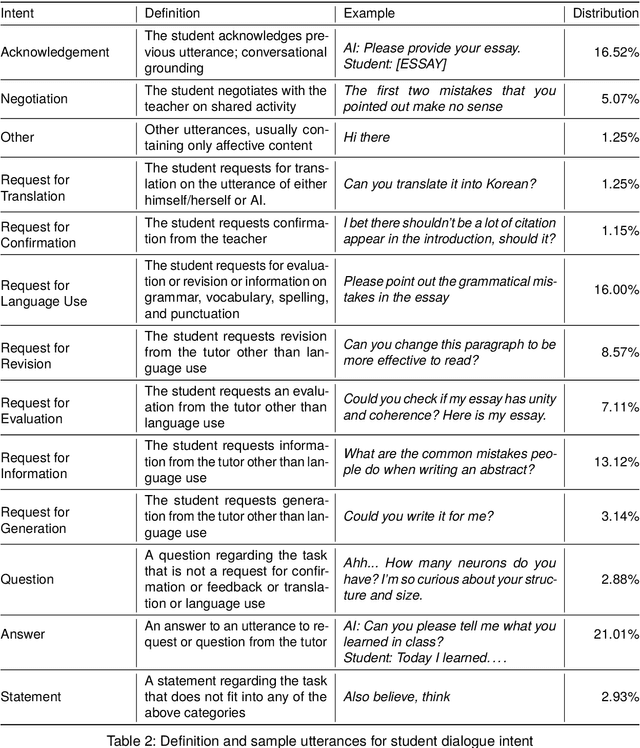
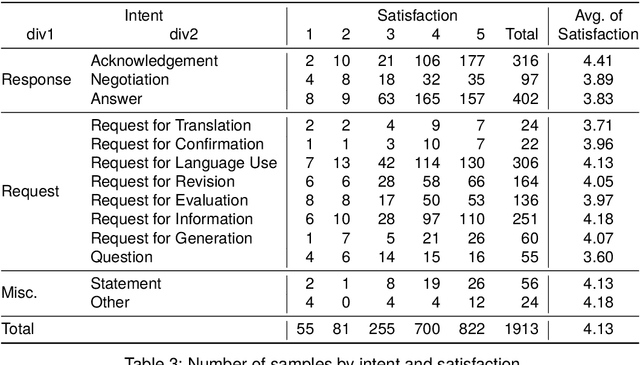
The integration of generative AI in education is expanding, yet empirical analyses of large-scale and real-world interactions between students and AI systems still remain limited. Addressing this gap, we present RECIPE4U (RECIPE for University), a dataset sourced from a semester-long experiment with 212 college students in English as Foreign Language (EFL) writing courses. During the study, students engaged in dialogues with ChatGPT to revise their essays. RECIPE4U includes comprehensive records of these interactions, including conversation logs, students' intent, students' self-rated satisfaction, and students' essay edit histories. In particular, we annotate the students' utterances in RECIPE4U with 13 intention labels based on our coding schemes. We establish baseline results for two subtasks in task-oriented dialogue systems within educational contexts: intent detection and satisfaction estimation. As a foundational step, we explore student-ChatGPT interaction patterns through RECIPE4U and analyze them by focusing on students' dialogue, essay data statistics, and students' essay edits. We further illustrate potential applications of RECIPE4U dataset for enhancing the incorporation of LLMs in educational frameworks. RECIPE4U is publicly available at https://zeunie.github.io/RECIPE4U/.
DREsS: Dataset for Rubric-based Essay Scoring on EFL Writing
Feb 21, 2024


Automated essay scoring (AES) is a useful tool in English as a Foreign Language (EFL) writing education, offering real-time essay scores for students and instructors. However, previous AES models were trained on essays and scores irrelevant to the practical scenarios of EFL writing education and usually provided a single holistic score due to the lack of appropriate datasets. In this paper, we release DREsS, a large-scale, standard dataset for rubric-based automated essay scoring. DREsS comprises three sub-datasets: DREsS_New, DREsS_Std., and DREsS_CASE. We collect DREsS_New, a real-classroom dataset with 1.7K essays authored by EFL undergraduate students and scored by English education experts. We also standardize existing rubric-based essay scoring datasets as DREsS_Std. We suggest CASE, a corruption-based augmentation strategy for essays, which generates 20K synthetic samples of DREsS_CASE and improves the baseline results by 45.44%. DREsS will enable further research to provide a more accurate and practical AES system for EFL writing education.
FABRIC: Automated Scoring and Feedback Generation for Essays
Oct 08, 2023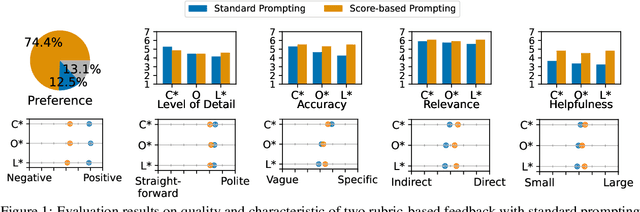
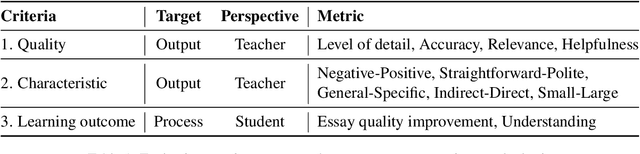
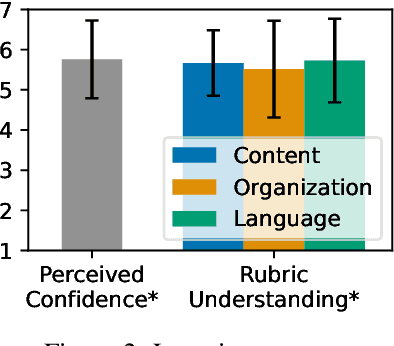
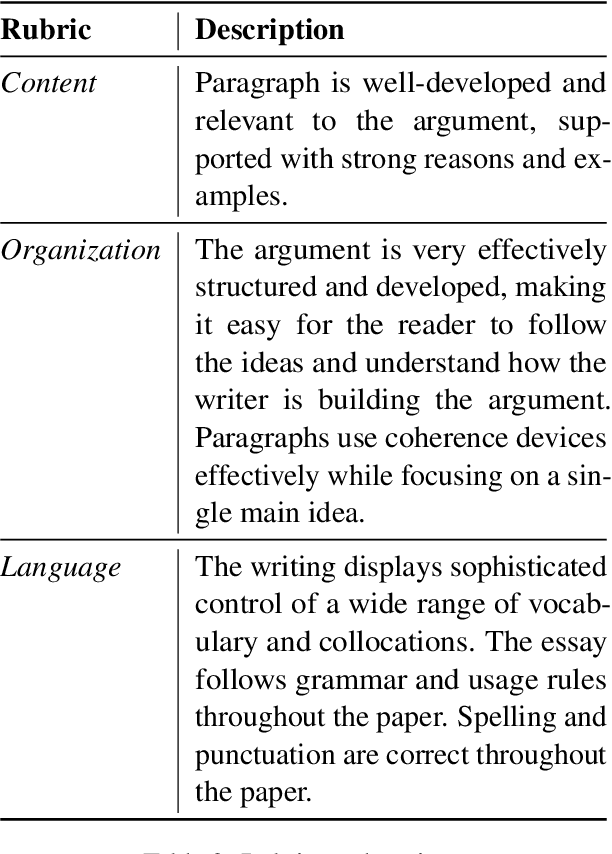
Automated essay scoring (AES) provides a useful tool for students and instructors in writing classes by generating essay scores in real-time. However, previous AES models do not provide more specific rubric-based scores nor feedback on how to improve the essays, which can be even more important than the overall scores for learning. We present FABRIC, a pipeline to help students and instructors in English writing classes by automatically generating 1) the overall scores, 2) specific rubric-based scores, and 3) detailed feedback on how to improve the essays. Under the guidance of English education experts, we chose the rubrics for the specific scores as content, organization, and language. The first component of the FABRIC pipeline is DREsS, a real-world Dataset for Rubric-based Essay Scoring (DREsS). The second component is CASE, a Corruption-based Augmentation Strategy for Essays, with which we can improve the accuracy of the baseline model by 45.44%. The third component is EssayCoT, the Essay Chain-of-Thought prompting strategy which uses scores predicted from the AES model to generate better feedback. We evaluate the effectiveness of the new dataset DREsS and the augmentation strategy CASE quantitatively and show significant improvements over the models trained with existing datasets. We evaluate the feedback generated by EssayCoT with English education experts to show significant improvements in the helpfulness of the feedback across all rubrics. Lastly, we evaluate the FABRIC pipeline with students in a college English writing class who rated the generated scores and feedback with an average of 6 on the Likert scale from 1 to 7.
ChEDDAR: Student-ChatGPT Dialogue in EFL Writing Education
Sep 23, 2023


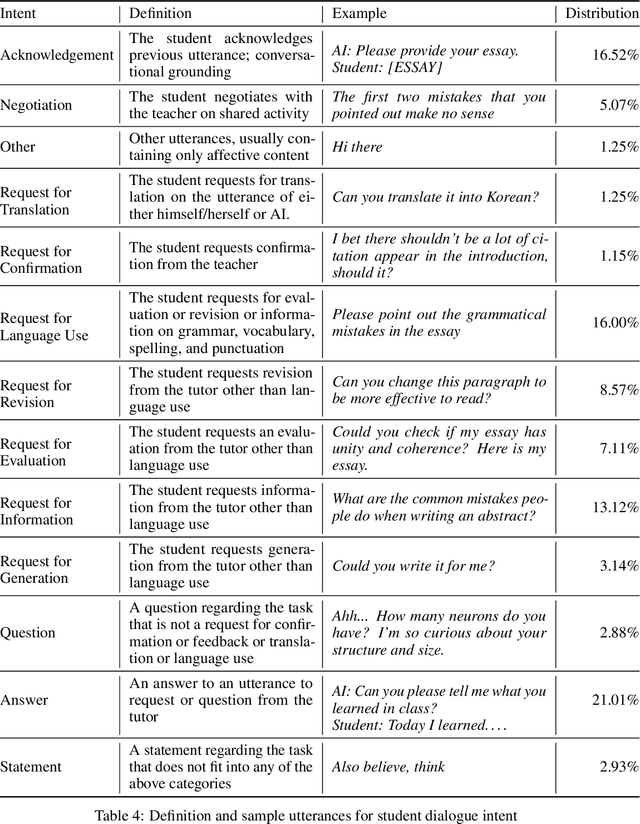
The integration of generative AI in education is expanding, yet empirical analyses of large-scale, real-world interactions between students and AI systems still remain limited. In this study, we present ChEDDAR, ChatGPT & EFL Learner's Dialogue Dataset As Revising an essay, which is collected from a semester-long longitudinal experiment involving 212 college students enrolled in English as Foreign Langauge (EFL) writing courses. The students were asked to revise their essays through dialogues with ChatGPT. ChEDDAR includes a conversation log, utterance-level essay edit history, self-rated satisfaction, and students' intent, in addition to session-level pre-and-post surveys documenting their objectives and overall experiences. We analyze students' usage patterns and perceptions regarding generative AI with respect to their intent and satisfaction. As a foundational step, we establish baseline results for two pivotal tasks in task-oriented dialogue systems within educational contexts: intent detection and satisfaction estimation. We finally suggest further research to refine the integration of generative AI into education settings, outlining potential scenarios utilizing ChEDDAR. ChEDDAR is publicly available at https://github.com/zeunie/ChEDDAR.
Rethinking Annotation: Can Language Learners Contribute?
Oct 13, 2022
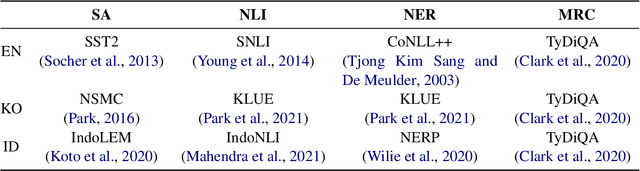
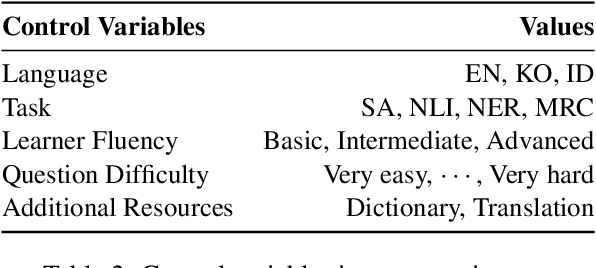
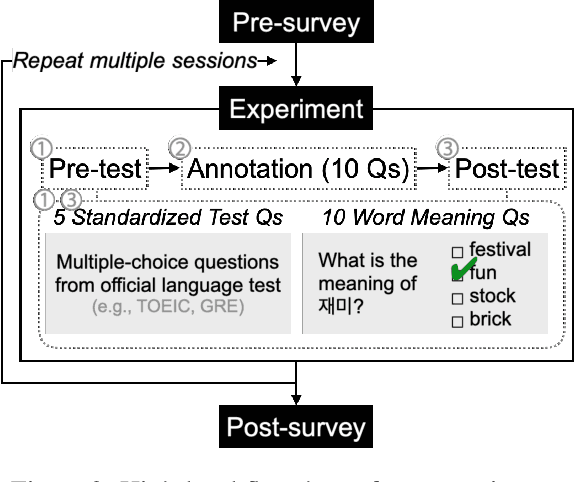
Researchers have traditionally recruited native speakers to provide annotations for the widely used benchmark datasets. But there are languages for which recruiting native speakers is difficult, and it would help to get learners of those languages to annotate the data. In this paper, we investigate whether language learners can contribute annotations to the benchmark datasets. In a carefully controlled annotation experiment, we recruit 36 language learners, provide two types of additional resources (dictionaries and machine-translated sentences), and perform mini-tests to measure their language proficiency. We target three languages, English, Korean, and Indonesian, and four NLP tasks, sentiment analysis, natural language inference, named entity recognition, and machine reading comprehension. We find that language learners, especially those with intermediate or advanced language proficiency, are able to provide fairly accurate labels with the help of additional resources. Moreover, we show that data annotation improves learners' language proficiency in terms of vocabulary and grammar. The implication of our findings is that broadening the annotation task to include language learners can open up the opportunity to build benchmark datasets for languages for which it is difficult to recruit native speakers.