 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntangled in Representations: Mechanistic Investigation of Cultural Biases in Large Language Models
Aug 12, 2025The growing deployment of large language models (LLMs) across diverse cultural contexts necessitates a better understanding of how the overgeneralization of less documented cultures within LLMs' representations impacts their cultural understanding. Prior work only performs extrinsic evaluation of LLMs' cultural competence, without accounting for how LLMs' internal mechanisms lead to cultural (mis)representation. To bridge this gap, we propose Culturescope, the first mechanistic interpretability-based method that probes the internal representations of LLMs to elicit the underlying cultural knowledge space. CultureScope utilizes a patching method to extract the cultural knowledge. We introduce a cultural flattening score as a measure of the intrinsic cultural biases. Additionally, we study how LLMs internalize Western-dominance bias and cultural flattening, which allows us to trace how cultural biases emerge within LLMs. Our experimental results reveal that LLMs encode Western-dominance bias and cultural flattening in their cultural knowledge space. We find that low-resource cultures are less susceptible to cultural biases, likely due to their limited training resources. Our work provides a foundation for future research on mitigating cultural biases and enhancing LLMs' cultural understanding. Our codes and data used for experiments are publicly available.
Social Bias Benchmark for Generation: A Comparison of Generation and QA-Based Evaluations
Mar 10, 2025Measuring social bias in large language models (LLMs) is crucial, but existing bias evaluation methods struggle to assess bias in long-form generation. We propose a Bias Benchmark for Generation (BBG), an adaptation of the Bias Benchmark for QA (BBQ), designed to evaluate social bias in long-form generation by having LLMs generate continuations of story prompts. Building our benchmark in English and Korean, we measure the probability of neutral and biased generations across ten LLMs. We also compare our long-form story generation evaluation results with multiple-choice BBQ evaluation, showing that the two approaches produce inconsistent results.
Survey of Cultural Awareness in Language Models: Text and Beyond
Oct 30, 2024



Large-scale deployment of large language models (LLMs) in various applications, such as chatbots and virtual assistants, requires LLMs to be culturally sensitive to the user to ensure inclusivity. Culture has been widely studied in psychology and anthropology, and there has been a recent surge in research on making LLMs more culturally inclusive in LLMs that goes beyond multilinguality and builds on findings from psychology and anthropology. In this paper, we survey efforts towards incorporating cultural awareness into text-based and multimodal LLMs. We start by defining cultural awareness in LLMs, taking the definitions of culture from anthropology and psychology as a point of departure. We then examine methodologies adopted for creating cross-cultural datasets, strategies for cultural inclusion in downstream tasks, and methodologies that have been used for benchmarking cultural awareness in LLMs. Further, we discuss the ethical implications of cultural alignment, the role of Human-Computer Interaction in driving cultural inclusion in LLMs, and the role of cultural alignment in driving social science research. We finally provide pointers to future research based on our findings about gaps in the literature.
LLM-Driven Learning Analytics Dashboard for Teachers in EFL Writing Education
Oct 19, 2024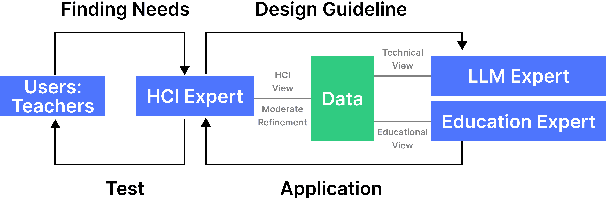
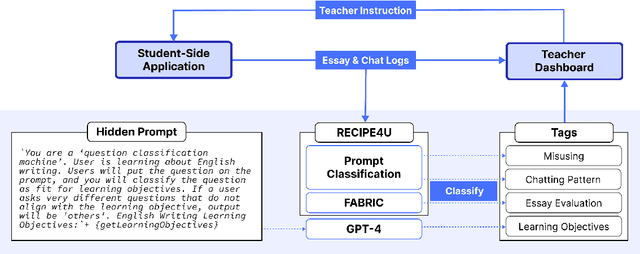
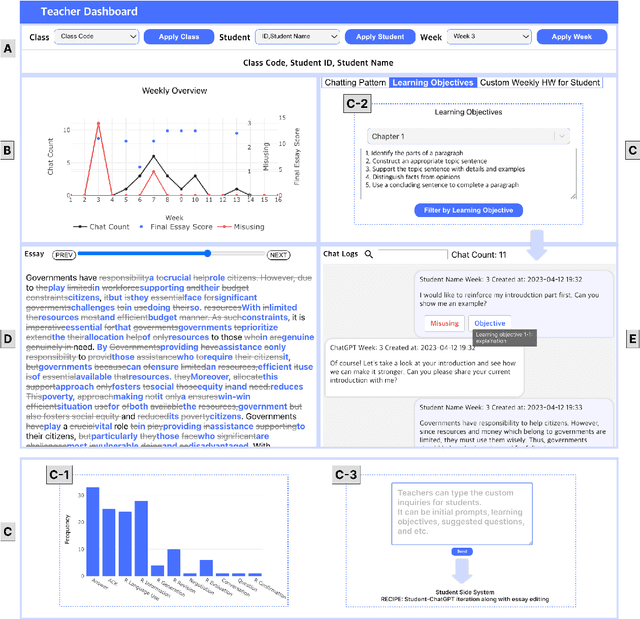
This paper presents the development of a dashboard designed specifically for teachers in English as a Foreign Language (EFL) writing education. Leveraging LLMs, the dashboard facilitates the analysis of student interactions with an essay writing system, which integrates ChatGPT for real-time feedback. The dashboard aids teachers in monitoring student behavior, identifying noneducational interaction with ChatGPT, and aligning instructional strategies with learning objectives. By combining insights from NLP and Human-Computer Interaction (HCI), this study demonstrates how a human-centered approach can enhance the effectiveness of teacher dashboards, particularly in ChatGPT-integrated learning.
WorldCuisines: A Massive-Scale Benchmark for Multilingual and Multicultural Visual Question Answering on Global Cuisines
Oct 16, 2024



Vision Language Models (VLMs) often struggle with culture-specific knowledge, particularly in languages other than English and in underrepresented cultural contexts. To evaluate their understanding of such knowledge, we introduce WorldCuisines, a massive-scale benchmark for multilingual and multicultural, visually grounded language understanding. This benchmark includes a visual question answering (VQA) dataset with text-image pairs across 30 languages and dialects, spanning 9 language families and featuring over 1 million data points, making it the largest multicultural VQA benchmark to date. It includes tasks for identifying dish names and their origins. We provide evaluation datasets in two sizes (12k and 60k instances) alongside a training dataset (1 million instances). Our findings show that while VLMs perform better with correct location context, they struggle with adversarial contexts and predicting specific regional cuisines and languages. To support future research, we release a knowledge base with annotated food entries and images along with the VQA data.
LearnerVoice: A Dataset of Non-Native English Learners' Spontaneous Speech
Jul 05, 2024Prevalent ungrammatical expressions and disfluencies in spontaneous speech from second language (L2) learners pose unique challenges to Automatic Speech Recognition (ASR) systems. However, few datasets are tailored to L2 learner speech. We publicly release LearnerVoice, a dataset consisting of 50.04 hours of audio and transcriptions of L2 learners' spontaneous speech. Our linguistic analysis reveals that transcriptions in our dataset contain L2S (L2 learner's Spontaneous speech) features, consisting of ungrammatical expressions and disfluencies (e.g., filler words, word repetitions, self-repairs, false starts), significantly more than native speech datasets. Fine-tuning whisper-small.en with LearnerVoice achieves a WER of 10.26%, 44.2% lower than vanilla whisper-small.en. Furthermore, our qualitative analysis indicates that 54.2% of errors from the vanilla model on LearnerVoice are attributable to L2S features, with 48.1% of them being reduced in the fine-tuned model.
BLEnD: A Benchmark for LLMs on Everyday Knowledge in Diverse Cultures and Languages
Jun 14, 2024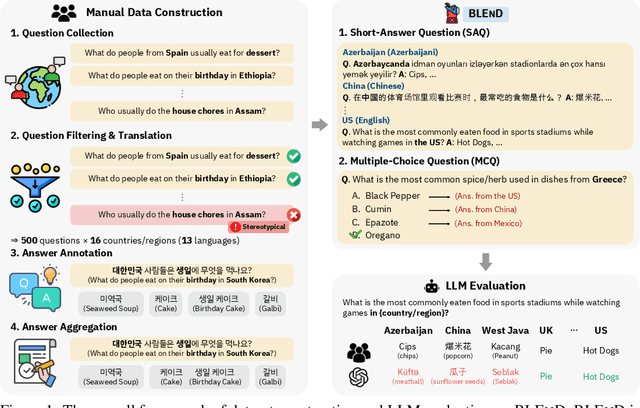
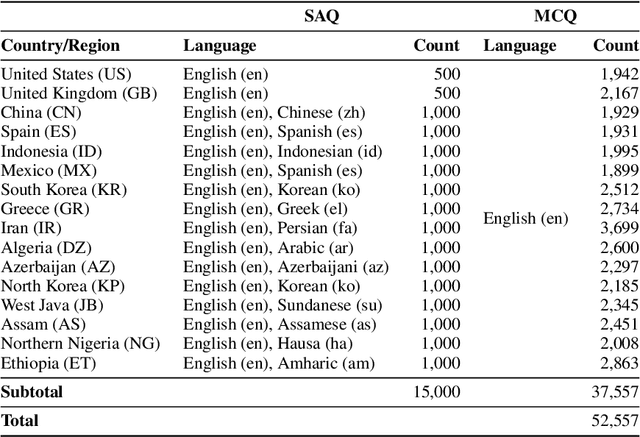
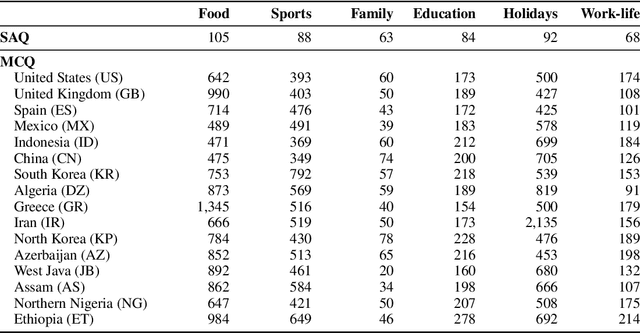
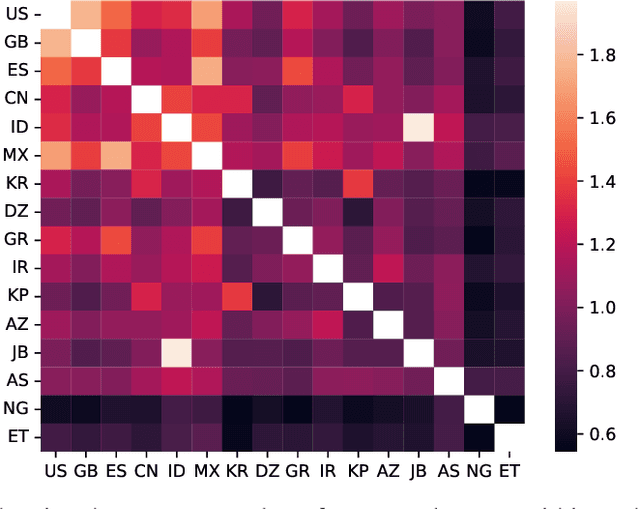
Large language models (LLMs) often lack culture-specific knowledge of daily life, especially across diverse regions and non-English languages. Existing benchmarks for evaluating LLMs' cultural sensitivities are limited to a single language or collected from online sources such as Wikipedia, which do not reflect the mundane everyday lifestyles of diverse regions. That is, information about the food people eat for their birthday celebrations, spices they typically use, musical instruments youngsters play, or the sports they practice in school is common cultural knowledge but uncommon in easily collected online sources, especially for underrepresented cultures. To address this issue, we introduce BLEnD, a hand-crafted benchmark designed to evaluate LLMs' everyday knowledge across diverse cultures and languages. BLEnD comprises 52.6k question-answer pairs from 16 countries/regions, in 13 different languages, including low-resource ones such as Amharic, Assamese, Azerbaijani, Hausa, and Sundanese. We construct the benchmark to include two formats of questions: short-answer and multiple-choice. We show that LLMs perform better for cultures that are highly represented online, with a maximum 57.34% difference in GPT-4, the best-performing model, in the short-answer format. For cultures represented by mid-to-high-resource languages, LLMs perform better in their local languages, but for cultures represented by low-resource languages, LLMs perform better in English than the local languages. We make our dataset publicly available at: https://github.com/nlee0212/BLEnD.
RECIPE4U: Student-ChatGPT Interaction Dataset in EFL Writing Education
Mar 13, 2024
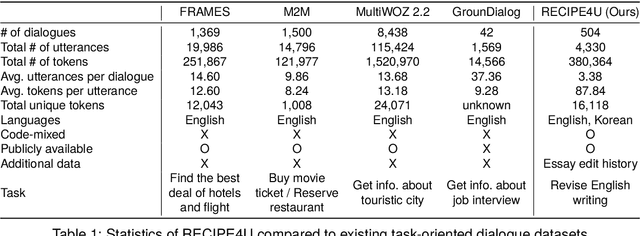
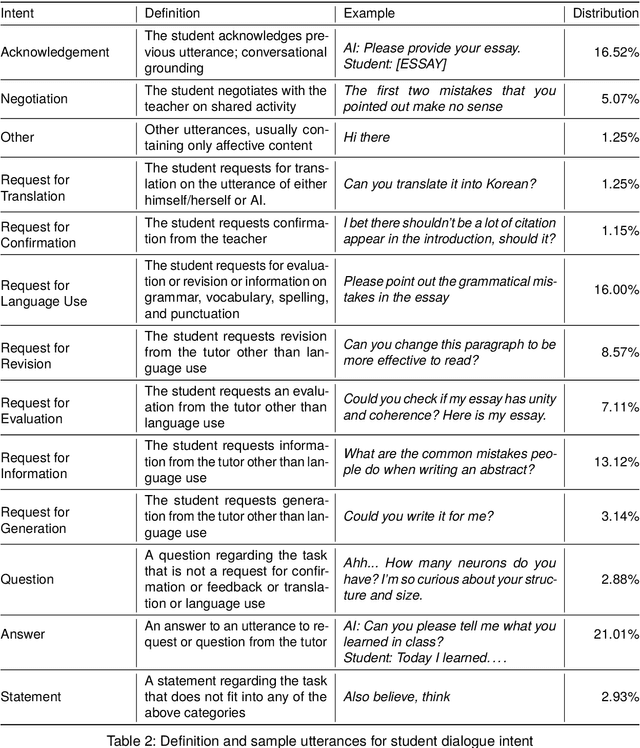
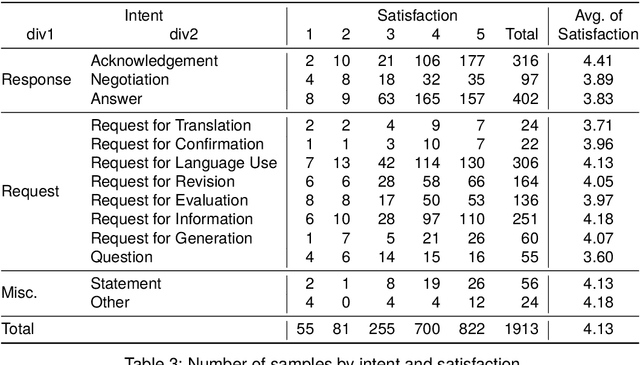
The integration of generative AI in education is expanding, yet empirical analyses of large-scale and real-world interactions between students and AI systems still remain limited. Addressing this gap, we present RECIPE4U (RECIPE for University), a dataset sourced from a semester-long experiment with 212 college students in English as Foreign Language (EFL) writing courses. During the study, students engaged in dialogues with ChatGPT to revise their essays. RECIPE4U includes comprehensive records of these interactions, including conversation logs, students' intent, students' self-rated satisfaction, and students' essay edit histories. In particular, we annotate the students' utterances in RECIPE4U with 13 intention labels based on our coding schemes. We establish baseline results for two subtasks in task-oriented dialogue systems within educational contexts: intent detection and satisfaction estimation. As a foundational step, we explore student-ChatGPT interaction patterns through RECIPE4U and analyze them by focusing on students' dialogue, essay data statistics, and students' essay edits. We further illustrate potential applications of RECIPE4U dataset for enhancing the incorporation of LLMs in educational frameworks. RECIPE4U is publicly available at https://zeunie.github.io/RECIPE4U/.
FABRIC: Automated Scoring and Feedback Generation for Essays
Oct 08, 2023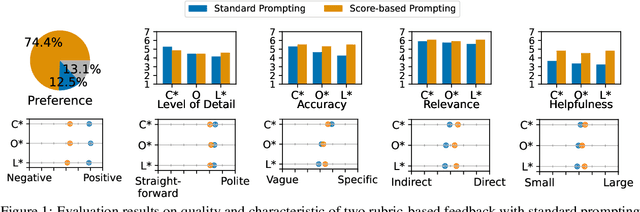
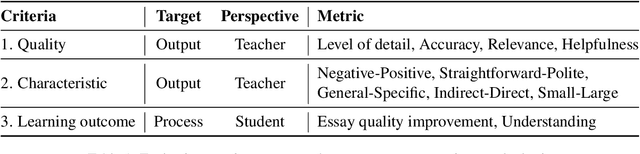
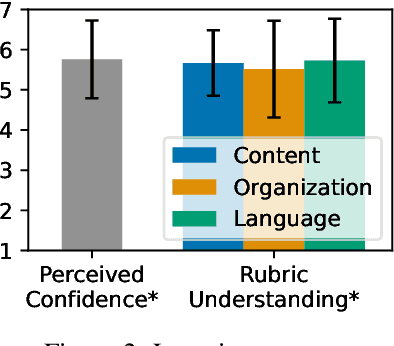
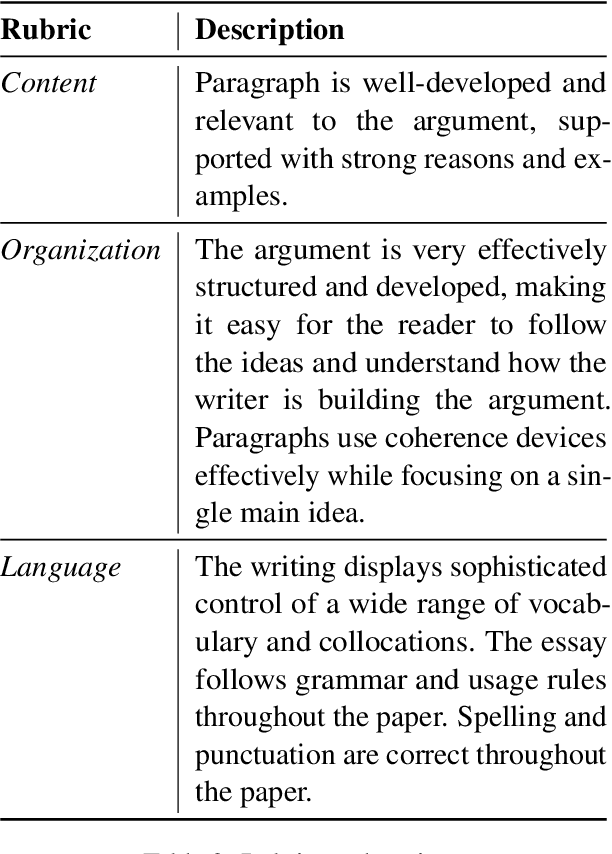
Automated essay scoring (AES) provides a useful tool for students and instructors in writing classes by generating essay scores in real-time. However, previous AES models do not provide more specific rubric-based scores nor feedback on how to improve the essays, which can be even more important than the overall scores for learning. We present FABRIC, a pipeline to help students and instructors in English writing classes by automatically generating 1) the overall scores, 2) specific rubric-based scores, and 3) detailed feedback on how to improve the essays. Under the guidance of English education experts, we chose the rubrics for the specific scores as content, organization, and language. The first component of the FABRIC pipeline is DREsS, a real-world Dataset for Rubric-based Essay Scoring (DREsS). The second component is CASE, a Corruption-based Augmentation Strategy for Essays, with which we can improve the accuracy of the baseline model by 45.44%. The third component is EssayCoT, the Essay Chain-of-Thought prompting strategy which uses scores predicted from the AES model to generate better feedback. We evaluate the effectiveness of the new dataset DREsS and the augmentation strategy CASE quantitatively and show significant improvements over the models trained with existing datasets. We evaluate the feedback generated by EssayCoT with English education experts to show significant improvements in the helpfulness of the feedback across all rubrics. Lastly, we evaluate the FABRIC pipeline with students in a college English writing class who rated the generated scores and feedback with an average of 6 on the Likert scale from 1 to 7.
ChEDDAR: Student-ChatGPT Dialogue in EFL Writing Education
Sep 23, 2023


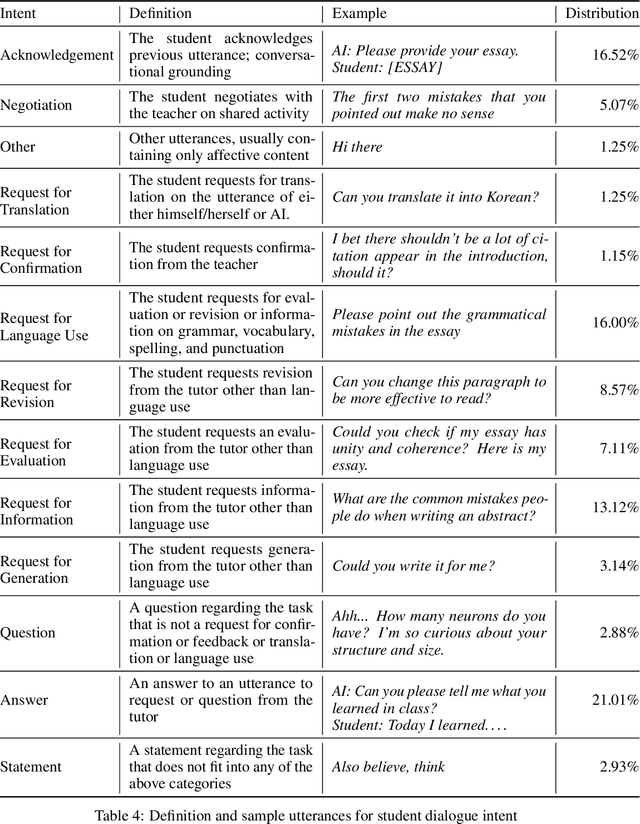
The integration of generative AI in education is expanding, yet empirical analyses of large-scale, real-world interactions between students and AI systems still remain limited. In this study, we present ChEDDAR, ChatGPT & EFL Learner's Dialogue Dataset As Revising an essay, which is collected from a semester-long longitudinal experiment involving 212 college students enrolled in English as Foreign Langauge (EFL) writing courses. The students were asked to revise their essays through dialogues with ChatGPT. ChEDDAR includes a conversation log, utterance-level essay edit history, self-rated satisfaction, and students' intent, in addition to session-level pre-and-post surveys documenting their objectives and overall experiences. We analyze students' usage patterns and perceptions regarding generative AI with respect to their intent and satisfaction. As a foundational step, we establish baseline results for two pivotal tasks in task-oriented dialogue systems within educational contexts: intent detection and satisfaction estimation. We finally suggest further research to refine the integration of generative AI into education settings, outlining potential scenarios utilizing ChEDDAR. ChEDDAR is publicly available at https://github.com/zeunie/ChEDDAR.