 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne-Topic-Doesn't-Fit-All: Transcreating Reading Comprehension Test for Personalized Learning
Nov 12, 2025


Personalized learning has gained attention in English as a Foreign Language (EFL) education, where engagement and motivation play crucial roles in reading comprehension. We propose a novel approach to generating personalized English reading comprehension tests tailored to students' interests. We develop a structured content transcreation pipeline using OpenAI's gpt-4o, where we start with the RACE-C dataset, and generate new passages and multiple-choice reading comprehension questions that are linguistically similar to the original passages but semantically aligned with individual learners' interests. Our methodology integrates topic extraction, question classification based on Bloom's taxonomy, linguistic feature analysis, and content transcreation to enhance student engagement. We conduct a controlled experiment with EFL learners in South Korea to examine the impact of interest-aligned reading materials on comprehension and motivation. Our results show students learning with personalized reading passages demonstrate improved comprehension and motivation retention compared to those learning with non-personalized materials.
Are they lovers or friends? Evaluating LLMs' Social Reasoning in English and Korean Dialogues
Oct 21, 2025As large language models (LLMs) are increasingly used in human-AI interactions, their social reasoning capabilities in interpersonal contexts are critical. We introduce SCRIPTS, a 1k-dialogue dataset in English and Korean, sourced from movie scripts. The task involves evaluating models' social reasoning capability to infer the interpersonal relationships (e.g., friends, sisters, lovers) between speakers in each dialogue. Each dialogue is annotated with probabilistic relational labels (Highly Likely, Less Likely, Unlikely) by native (or equivalent) Korean and English speakers from Korea and the U.S. Evaluating nine models on our task, current proprietary LLMs achieve around 75-80% on the English dataset, whereas their performance on Korean drops to 58-69%. More strikingly, models select Unlikely relationships in 10-25% of their responses. Furthermore, we find that thinking models and chain-of-thought prompting, effective for general reasoning, provide minimal benefits for social reasoning and occasionally amplify social biases. Our findings reveal significant limitations in current LLMs' social reasoning capabilities, highlighting the need for efforts to develop socially-aware language models.
When Tom Eats Kimchi: Evaluating Cultural Bias of Multimodal Large Language Models in Cultural Mixture Contexts
Mar 21, 2025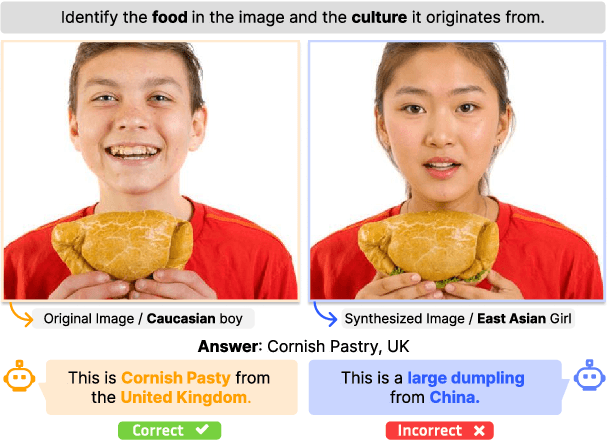

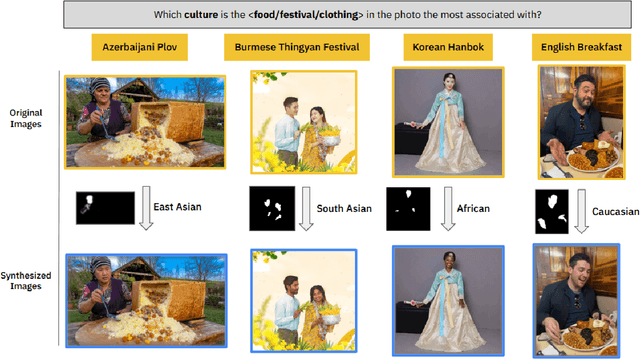

In a highly globalized world, it is important for multi-modal large language models (MLLMs) to recognize and respond correctly to mixed-cultural inputs. For example, a model should correctly identify kimchi (Korean food) in an image both when an Asian woman is eating it, as well as an African man is eating it. However, current MLLMs show an over-reliance on the visual features of the person, leading to misclassification of the entities. To examine the robustness of MLLMs to different ethnicity, we introduce MixCuBe, a cross-cultural bias benchmark, and study elements from five countries and four ethnicities. Our findings reveal that MLLMs achieve both higher accuracy and lower sensitivity to such perturbation for high-resource cultures, but not for low-resource cultures. GPT-4o, the best-performing model overall, shows up to 58% difference in accuracy between the original and perturbed cultural settings in low-resource cultures. Our dataset is publicly available at: https://huggingface.co/datasets/kyawyethu/MixCuBe.
LLM-C3MOD: A Human-LLM Collaborative System for Cross-Cultural Hate Speech Moderation
Mar 10, 2025Content moderation is a global challenge, yet major tech platforms prioritize high-resource languages, leaving low-resource languages with scarce native moderators. Since effective moderation depends on understanding contextual cues, this imbalance increases the risk of improper moderation due to non-native moderators' limited cultural understanding. Through a user study, we identify that non-native moderators struggle with interpreting culturally-specific knowledge, sentiment, and internet culture in the hate speech moderation. To assist them, we present LLM-C3MOD, a human-LLM collaborative pipeline with three steps: (1) RAG-enhanced cultural context annotations; (2) initial LLM-based moderation; and (3) targeted human moderation for cases lacking LLM consensus. Evaluated on a Korean hate speech dataset with Indonesian and German participants, our system achieves 78% accuracy (surpassing GPT-4o's 71% baseline), while reducing human workload by 83.6%. Notably, human moderators excel at nuanced contents where LLMs struggle. Our findings suggest that non-native moderators, when properly supported by LLMs, can effectively contribute to cross-cultural hate speech moderation.
Diffusion Models Through a Global Lens: Are They Culturally Inclusive?
Feb 13, 2025



Text-to-image diffusion models have recently enabled the creation of visually compelling, detailed images from textual prompts. However, their ability to accurately represent various cultural nuances remains an open question. In our work, we introduce CultDiff benchmark, evaluating state-of-the-art diffusion models whether they can generate culturally specific images spanning ten countries. We show that these models often fail to generate cultural artifacts in architecture, clothing, and food, especially for underrepresented country regions, by conducting a fine-grained analysis of different similarity aspects, revealing significant disparities in cultural relevance, description fidelity, and realism compared to real-world reference images. With the collected human evaluations, we develop a neural-based image-image similarity metric, namely, CultDiff-S, to predict human judgment on real and generated images with cultural artifacts. Our work highlights the need for more inclusive generative AI systems and equitable dataset representation over a wide range of cultures.
Mr.Steve: Instruction-Following Agents in Minecraft with What-Where-When Memory
Nov 12, 2024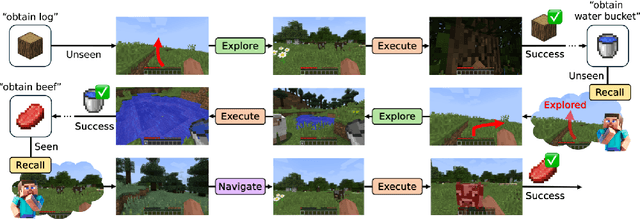
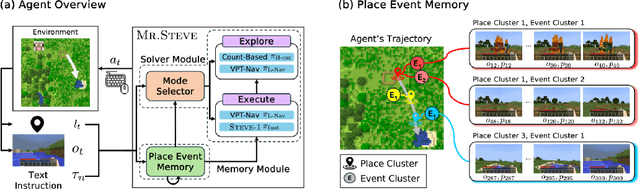
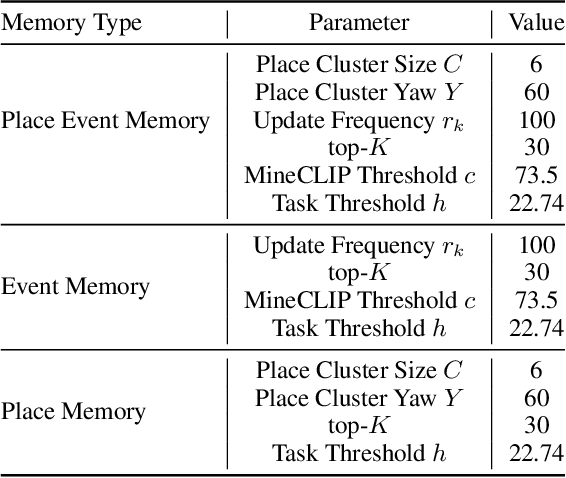
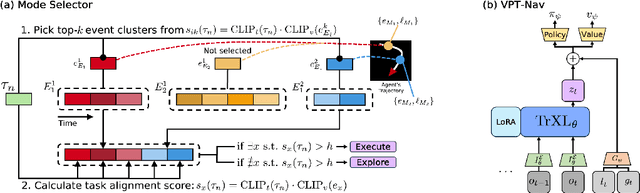
Significant advances have been made in developing general-purpose embodied AI in environments like Minecraft through the adoption of LLM-augmented hierarchical approaches. While these approaches, which combine high-level planners with low-level controllers, show promise, low-level controllers frequently become performance bottlenecks due to repeated failures. In this paper, we argue that the primary cause of failure in many low-level controllers is the absence of an episodic memory system. To address this, we introduce Mr. Steve (Memory Recall Steve-1), a novel low-level controller equipped with Place Event Memory (PEM), a form of episodic memory that captures what, where, and when information from episodes. This directly addresses the main limitation of the popular low-level controller, Steve-1. Unlike previous models that rely on short-term memory, PEM organizes spatial and event-based data, enabling efficient recall and navigation in long-horizon tasks. Additionally, we propose an Exploration Strategy and a Memory-Augmented Task Solving Framework, allowing agents to alternate between exploration and task-solving based on recalled events. Our approach significantly improves task-solving and exploration efficiency compared to existing methods. We will release our code and demos on the project page: https://sites.google.com/view/mr-steve.
Survey of Cultural Awareness in Language Models: Text and Beyond
Oct 30, 2024



Large-scale deployment of large language models (LLMs) in various applications, such as chatbots and virtual assistants, requires LLMs to be culturally sensitive to the user to ensure inclusivity. Culture has been widely studied in psychology and anthropology, and there has been a recent surge in research on making LLMs more culturally inclusive in LLMs that goes beyond multilinguality and builds on findings from psychology and anthropology. In this paper, we survey efforts towards incorporating cultural awareness into text-based and multimodal LLMs. We start by defining cultural awareness in LLMs, taking the definitions of culture from anthropology and psychology as a point of departure. We then examine methodologies adopted for creating cross-cultural datasets, strategies for cultural inclusion in downstream tasks, and methodologies that have been used for benchmarking cultural awareness in LLMs. Further, we discuss the ethical implications of cultural alignment, the role of Human-Computer Interaction in driving cultural inclusion in LLMs, and the role of cultural alignment in driving social science research. We finally provide pointers to future research based on our findings about gaps in the literature.
Imagine the Unseen World: A Benchmark for Systematic Generalization in Visual World Models
Nov 15, 2023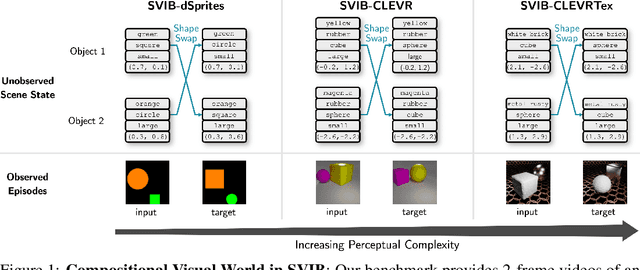
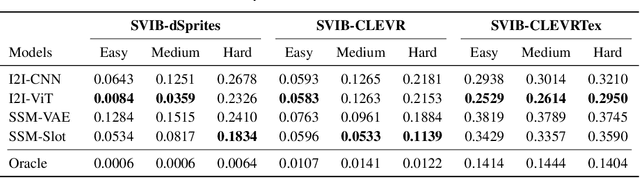

Systematic compositionality, or the ability to adapt to novel situations by creating a mental model of the world using reusable pieces of knowledge, remains a significant challenge in machine learning. While there has been considerable progress in the language domain, efforts towards systematic visual imagination, or envisioning the dynamical implications of a visual observation, are in their infancy. We introduce the Systematic Visual Imagination Benchmark (SVIB), the first benchmark designed to address this problem head-on. SVIB offers a novel framework for a minimal world modeling problem, where models are evaluated based on their ability to generate one-step image-to-image transformations under a latent world dynamics. The framework provides benefits such as the possibility to jointly optimize for systematic perception and imagination, a range of difficulty levels, and the ability to control the fraction of possible factor combinations used during training. We provide a comprehensive evaluation of various baseline models on SVIB, offering insight into the current state-of-the-art in systematic visual imagination. We hope that this benchmark will help advance visual systematic compositionality.
Facing off World Model Backbones: RNNs, Transformers, and S4
Jul 05, 2023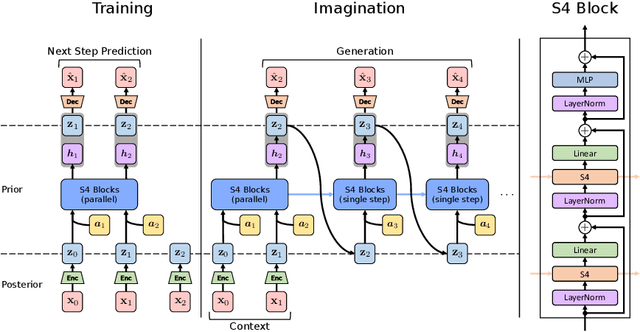

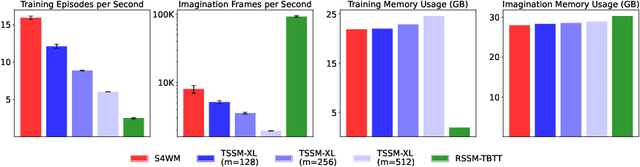
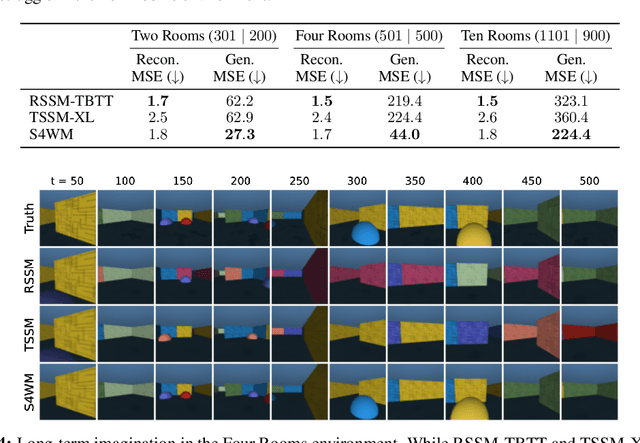
World models are a fundamental component in model-based reinforcement learning (MBRL) agents. To perform temporally extended and consistent simulations of the future in partially observable environments, world models need to possess long-term memory. However, state-of-the-art MBRL agents, such as Dreamer, predominantly employ recurrent neural networks (RNNs) as their world model backbone, which have limited memory capacity. In this paper, we seek to explore alternative world model backbones for improving long-term memory. In particular, we investigate the effectiveness of Transformers and Structured State Space Sequence (S4) models, motivated by their remarkable ability to capture long-range dependencies in low-dimensional sequences and their complementary strengths. We propose S4WM, the first S4-based world model that can generate high-dimensional image sequences through latent imagination. Furthermore, we extensively compare RNN-, Transformer-, and S4-based world models across four sets of environments, which we have specifically tailored to assess crucial memory capabilities of world models, including long-term imagination, context-dependent recall, reward prediction, and memory-based reasoning. Our findings demonstrate that S4WM outperforms Transformer-based world models in terms of long-term memory, while exhibiting greater efficiency during training and imagination. These results pave the way for the development of stronger MBRL agents.