 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImagine the Unseen World: A Benchmark for Systematic Generalization in Visual World Models
Nov 15, 2023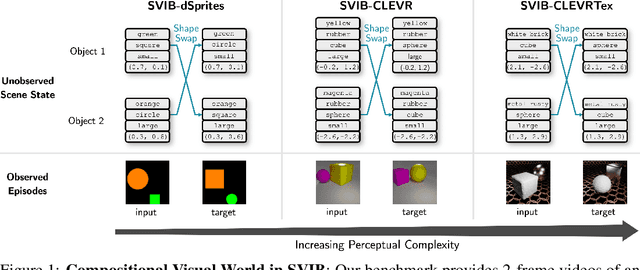
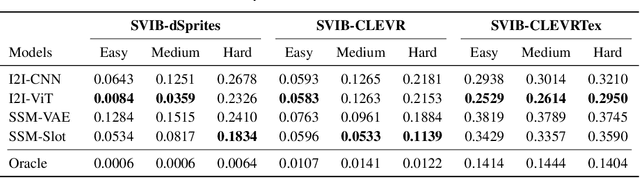

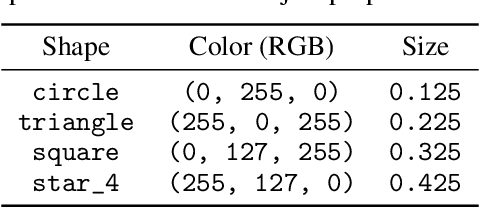
Systematic compositionality, or the ability to adapt to novel situations by creating a mental model of the world using reusable pieces of knowledge, remains a significant challenge in machine learning. While there has been considerable progress in the language domain, efforts towards systematic visual imagination, or envisioning the dynamical implications of a visual observation, are in their infancy. We introduce the Systematic Visual Imagination Benchmark (SVIB), the first benchmark designed to address this problem head-on. SVIB offers a novel framework for a minimal world modeling problem, where models are evaluated based on their ability to generate one-step image-to-image transformations under a latent world dynamics. The framework provides benefits such as the possibility to jointly optimize for systematic perception and imagination, a range of difficulty levels, and the ability to control the fraction of possible factor combinations used during training. We provide a comprehensive evaluation of various baseline models on SVIB, offering insight into the current state-of-the-art in systematic visual imagination. We hope that this benchmark will help advance visual systematic compositionality.
Neural Block-Slot Representations
Nov 02, 2022



In this paper, we propose a novel object-centric representation, called Block-Slot Representation. Unlike the conventional slot representation, the Block-Slot Representation provides concept-level disentanglement within a slot. A block-slot is constructed by composing a set of modular concept representations, called blocks, generated from a learned memory of abstract concept prototypes. We call this block-slot construction process Block-Slot Attention. Block-Slot Attention facilitates the emergence of abstract concept blocks within a slot such as color, position, and texture, without any supervision. This brings the benefits of disentanglement into slots and the representation becomes more interpretable. Similar to Slot Attention, this mechanism can be used as a drop-in module in any arbitrary neural architecture. In experiments, we show that our model disentangles object properties significantly better than the previous methods, including complex textured scenes. We also demonstrate the ability to compose novel scenes by composing slots at the block-level.