 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDreamweaver: Learning Compositional World Representations from Pixels
Jan 24, 2025



Humans have an innate ability to decompose their perceptions of the world into objects and their attributes, such as colors, shapes, and movement patterns. This cognitive process enables us to imagine novel futures by recombining familiar concepts. However, replicating this ability in artificial intelligence systems has proven challenging, particularly when it comes to modeling videos into compositional concepts and generating unseen, recomposed futures without relying on auxiliary data, such as text, masks, or bounding boxes. In this paper, we propose Dreamweaver, a neural architecture designed to discover hierarchical and compositional representations from raw videos and generate compositional future simulations. Our approach leverages a novel Recurrent Block-Slot Unit (RBSU) to decompose videos into their constituent objects and attributes. In addition, Dreamweaver uses a multi-future-frame prediction objective to capture disentangled representations for dynamic concepts more effectively as well as static concepts. In experiments, we demonstrate our model outperforms current state-of-the-art baselines for world modeling when evaluated under the DCI framework across multiple datasets. Furthermore, we show how the modularized concept representations of our model enable compositional imagination, allowing the generation of novel videos by recombining attributes from different objects.
Slot State Space Models
Jun 18, 2024Recent State Space Models (SSMs) such as S4, S5, and Mamba have shown remarkable computational benefits in long-range temporal dependency modeling. However, in many sequence modeling problems, the underlying process is inherently modular and it is of interest to have inductive biases that mimic this modular structure. In this paper, we introduce SlotSSMs, a novel framework for incorporating independent mechanisms into SSMs to preserve or encourage separation of information. Unlike conventional SSMs that maintain a monolithic state vector, SlotSSMs maintains the state as a collection of multiple vectors called slots. Crucially, the state transitions are performed independently per slot with sparse interactions across slots implemented via the bottleneck of self-attention. In experiments, we evaluate our model in object-centric video understanding, 3D visual reasoning, and video prediction tasks, which involve modeling multiple objects and their long-range temporal dependencies. We find that our proposed design offers substantial performance gains over existing sequence modeling methods.
Parallelized Spatiotemporal Binding
Feb 26, 2024While modern best practices advocate for scalable architectures that support long-range interactions, object-centric models are yet to fully embrace these architectures. In particular, existing object-centric models for handling sequential inputs, due to their reliance on RNN-based implementation, show poor stability and capacity and are slow to train on long sequences. We introduce Parallelizable Spatiotemporal Binder or PSB, the first temporally-parallelizable slot learning architecture for sequential inputs. Unlike conventional RNN-based approaches, PSB produces object-centric representations, known as slots, for all time-steps in parallel. This is achieved by refining the initial slots across all time-steps through a fixed number of layers equipped with causal attention. By capitalizing on the parallelism induced by our architecture, the proposed model exhibits a significant boost in efficiency. In experiments, we test PSB extensively as an encoder within an auto-encoding framework paired with a wide variety of decoder options. Compared to the state-of-the-art, our architecture demonstrates stable training on longer sequences, achieves parallelization that results in a 60% increase in training speed, and yields performance that is on par with or better on unsupervised 2D and 3D object-centric scene decomposition and understanding.
Imagine the Unseen World: A Benchmark for Systematic Generalization in Visual World Models
Nov 15, 2023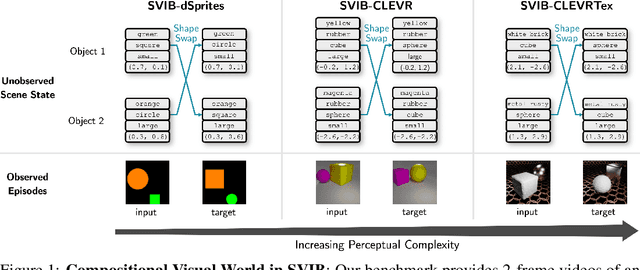
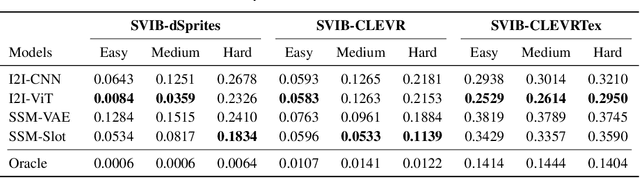

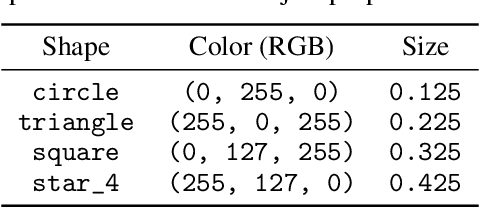
Systematic compositionality, or the ability to adapt to novel situations by creating a mental model of the world using reusable pieces of knowledge, remains a significant challenge in machine learning. While there has been considerable progress in the language domain, efforts towards systematic visual imagination, or envisioning the dynamical implications of a visual observation, are in their infancy. We introduce the Systematic Visual Imagination Benchmark (SVIB), the first benchmark designed to address this problem head-on. SVIB offers a novel framework for a minimal world modeling problem, where models are evaluated based on their ability to generate one-step image-to-image transformations under a latent world dynamics. The framework provides benefits such as the possibility to jointly optimize for systematic perception and imagination, a range of difficulty levels, and the ability to control the fraction of possible factor combinations used during training. We provide a comprehensive evaluation of various baseline models on SVIB, offering insight into the current state-of-the-art in systematic visual imagination. We hope that this benchmark will help advance visual systematic compositionality.
Object-Centric Slot Diffusion
Mar 20, 2023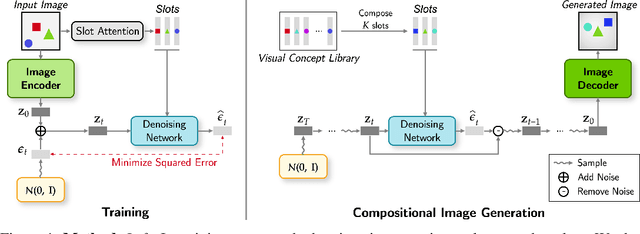



Despite remarkable recent advances, making object-centric learning work for complex natural scenes remains the main challenge. The recent success of adopting the transformer-based image generative model in object-centric learning suggests that having a highly expressive image generator is crucial for dealing with complex scenes. In this paper, inspired by this observation, we aim to answer the following question: can we benefit from the other pillar of modern deep generative models, i.e., the diffusion models, for object-centric learning and what are the pros and cons of such a model? To this end, we propose a new object-centric learning model, Latent Slot Diffusion (LSD). LSD can be seen from two perspectives. From the perspective of object-centric learning, it replaces the conventional slot decoders with a latent diffusion model conditioned on the object slots. Conversely, from the perspective of diffusion models, it is the first unsupervised compositional conditional diffusion model which, unlike traditional diffusion models, does not require supervised annotation such as a text description to learn to compose. In experiments on various object-centric tasks, including the FFHQ dataset for the first time in this line of research, we demonstrate that LSD significantly outperforms the state-of-the-art transformer-based decoder, particularly when the scene is more complex. We also show a superior quality in unsupervised compositional generation.
Neural Block-Slot Representations
Nov 02, 2022



In this paper, we propose a novel object-centric representation, called Block-Slot Representation. Unlike the conventional slot representation, the Block-Slot Representation provides concept-level disentanglement within a slot. A block-slot is constructed by composing a set of modular concept representations, called blocks, generated from a learned memory of abstract concept prototypes. We call this block-slot construction process Block-Slot Attention. Block-Slot Attention facilitates the emergence of abstract concept blocks within a slot such as color, position, and texture, without any supervision. This brings the benefits of disentanglement into slots and the representation becomes more interpretable. Similar to Slot Attention, this mechanism can be used as a drop-in module in any arbitrary neural architecture. In experiments, we show that our model disentangles object properties significantly better than the previous methods, including complex textured scenes. We also demonstrate the ability to compose novel scenes by composing slots at the block-level.
Simple Unsupervised Object-Centric Learning for Complex and Naturalistic Videos
May 27, 2022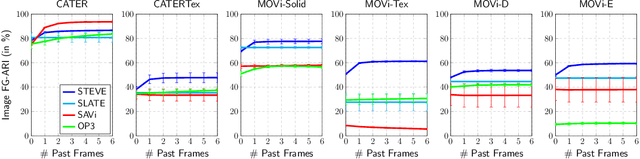
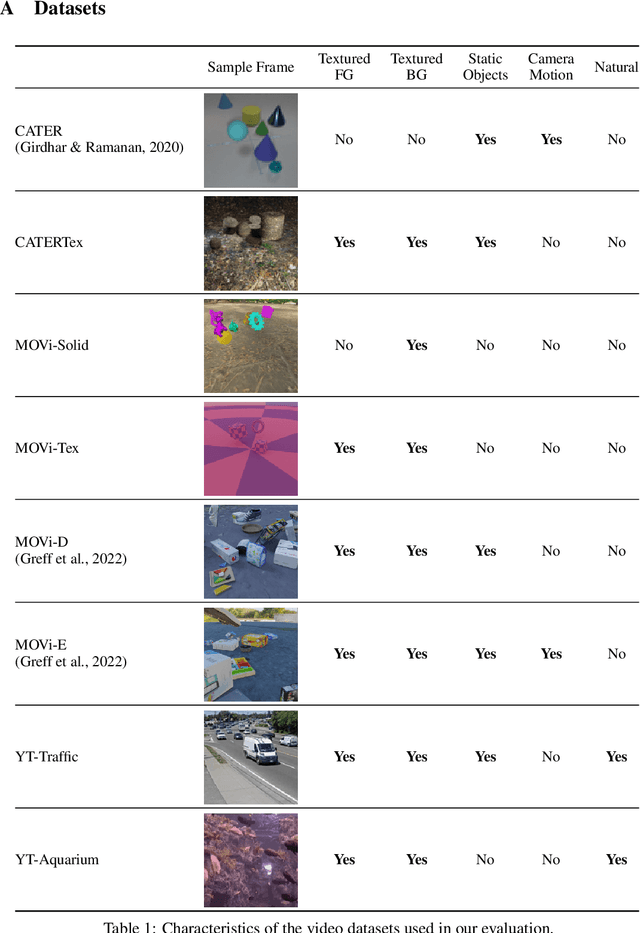
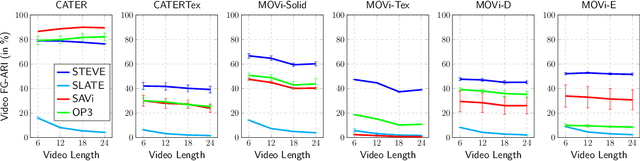
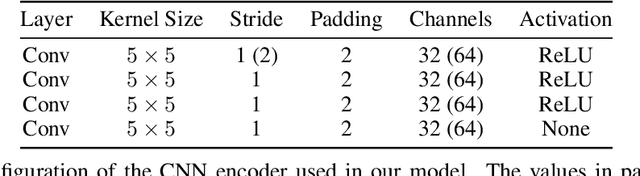
Unsupervised object-centric learning aims to represent the modular, compositional, and causal structure of a scene as a set of object representations and thereby promises to resolve many critical limitations of traditional single-vector representations such as poor systematic generalization. Although there have been many remarkable advances in recent years, one of the most critical problems in this direction has been that previous methods work only with simple and synthetic scenes but not with complex and naturalistic images or videos. In this paper, we propose STEVE, an unsupervised model for object-centric learning in videos. Our proposed model makes a significant advancement by demonstrating its effectiveness on various complex and naturalistic videos unprecedented in this line of research. Interestingly, this is achieved by neither adding complexity to the model architecture nor introducing a new objective or weak supervision. Rather, it is achieved by a surprisingly simple architecture that uses a transformer-based image decoder conditioned on slots and the learning objective is simply to reconstruct the observation. Our experiment results on various complex and naturalistic videos show significant improvements compared to the previous state-of-the-art.
Illiterate DALL-E Learns to Compose
Oct 27, 2021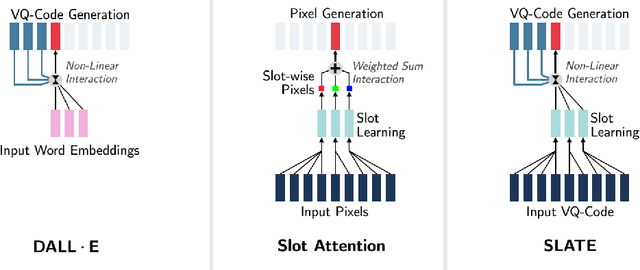
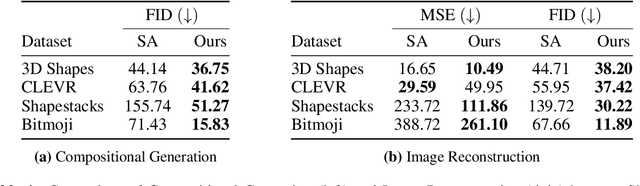
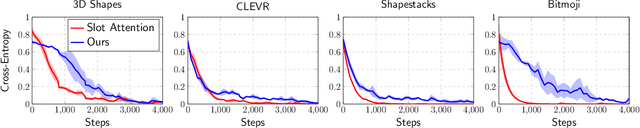

Although DALL-E has shown an impressive ability of composition-based systematic generalization in image generation, it requires the dataset of text-image pairs and the compositionality is provided by the text. In contrast, object-centric representation models like the Slot Attention model learn composable representations without the text prompt. However, unlike DALL-E its ability to systematically generalize for zero-shot generation is significantly limited. In this paper, we propose a simple but novel slot-based autoencoding architecture, called SLATE, for combining the best of both worlds: learning object-centric representations that allows systematic generalization in zero-shot image generation without text. As such, this model can also be seen as an illiterate DALL-E model. Unlike the pixel-mixture decoders of existing object-centric representation models, we propose to use the Image GPT decoder conditioned on the slots for capturing complex interactions among the slots and pixels. In experiments, we show that this simple and easy-to-implement architecture not requiring a text prompt achieves significant improvement in in-distribution and out-of-distribution (zero-shot) image generation and qualitatively comparable or better slot-attention structure than the models based on mixture decoders.
Structured World Belief for Reinforcement Learning in POMDP
Jul 19, 2021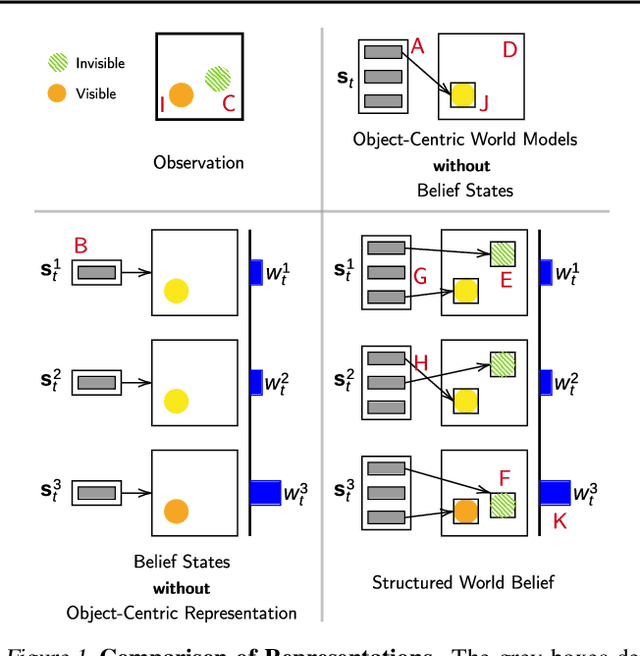
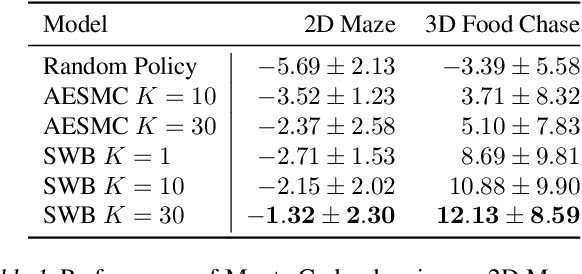
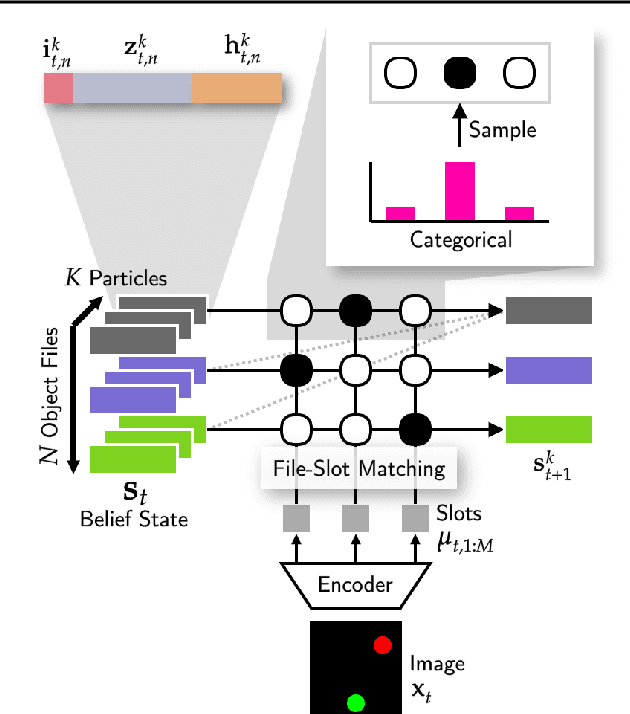

Object-centric world models provide structured representation of the scene and can be an important backbone in reinforcement learning and planning. However, existing approaches suffer in partially-observable environments due to the lack of belief states. In this paper, we propose Structured World Belief, a model for learning and inference of object-centric belief states. Inferred by Sequential Monte Carlo (SMC), our belief states provide multiple object-centric scene hypotheses. To synergize the benefits of SMC particles with object representations, we also propose a new object-centric dynamics model that considers the inductive bias of object permanence. This enables tracking of object states even when they are invisible for a long time. To further facilitate object tracking in this regime, we allow our model to attend flexibly to any spatial location in the image which was restricted in previous models. In experiments, we show that object-centric belief provides a more accurate and robust performance for filtering and generation. Furthermore, we show the efficacy of structured world belief in improving the performance of reinforcement learning, planning and supervised reasoning.
Robustifying Sequential Neural Processes
Jun 29, 2020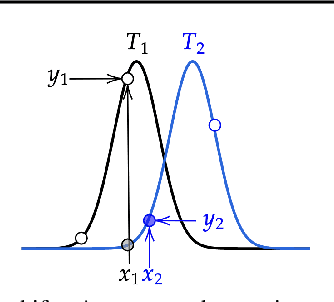

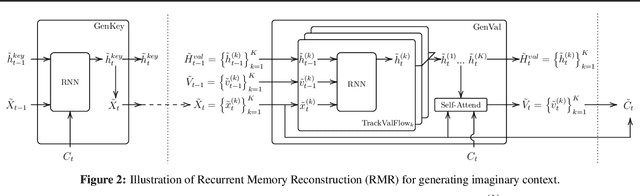

When tasks change over time, meta-transfer learning seeks to improve the efficiency of learning a new task via both meta-learning and transfer-learning. While the standard attention has been effective in a variety of settings, we question its effectiveness in improving meta-transfer learning since the tasks being learned are dynamic and the amount of context can be substantially smaller. In this paper, using a recently proposed meta-transfer learning model, Sequential Neural Processes (SNP), we first empirically show that it suffers from a similar underfitting problem observed in the functions inferred by Neural Processes. However, we further demonstrate that unlike the meta-learning setting, the standard attention mechanisms are not effective in meta-transfer setting. To resolve, we propose a new attention mechanism, Recurrent Memory Reconstruction (RMR), and demonstrate that providing an imaginary context that is recurrently updated and reconstructed with interaction is crucial in achieving effective attention for meta-transfer learning. Furthermore, incorporating RMR into SNP, we propose Attentive Sequential Neural Processes-RMR (ASNP-RMR) and demonstrate in various tasks that ASNP-RMR significantly outperforms the baselines.