 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObject-Centric Slot Diffusion
Paper and Code
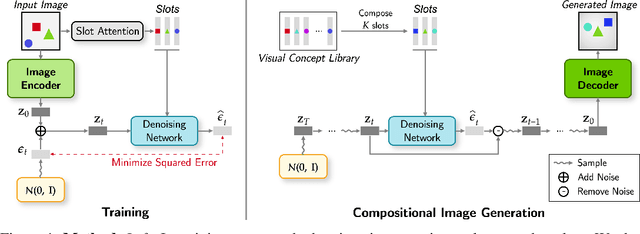



Despite remarkable recent advances, making object-centric learning work for complex natural scenes remains the main challenge. The recent success of adopting the transformer-based image generative model in object-centric learning suggests that having a highly expressive image generator is crucial for dealing with complex scenes. In this paper, inspired by this observation, we aim to answer the following question: can we benefit from the other pillar of modern deep generative models, i.e., the diffusion models, for object-centric learning and what are the pros and cons of such a model? To this end, we propose a new object-centric learning model, Latent Slot Diffusion (LSD). LSD can be seen from two perspectives. From the perspective of object-centric learning, it replaces the conventional slot decoders with a latent diffusion model conditioned on the object slots. Conversely, from the perspective of diffusion models, it is the first unsupervised compositional conditional diffusion model which, unlike traditional diffusion models, does not require supervised annotation such as a text description to learn to compose. In experiments on various object-centric tasks, including the FFHQ dataset for the first time in this line of research, we demonstrate that LSD significantly outperforms the state-of-the-art transformer-based decoder, particularly when the scene is more complex. We also show a superior quality in unsupervised compositional generation.