 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning with a Single Rollout via Monte Carlo Pass@k Critic
Jun 24, 2026Estimating token-level advantages in reinforcement learning (RL) for language models remains challenging because scaling up episodic experience collection is expensive. The difficulty intensifies for baseline advantage estimation methods, where repeated sampling causes trajectories to diverge into substantially different reasoning prefixes. In this context, RL algorithms such as GRPO prove limited: an outcome reward is too sparse to be attributed to specific actions like intermediate steps, and comparisons across sampled traces are non-trivial because they are heterogeneous. To mitigate both the computational cost of repeated sampling and the difficulty of credit assignment, we study single-rollout proximal policy optimization (SR-PPO) featuring token-level credit assignment in RL for language models. Instead of estimating advantages by normalizing episodic returns within the candidate group, we train a calibrated token-level credit critic using Monte Carlo outcomes from one rollout per prompt. Specifically, we use the critic to predict the Pass@k success probability at the prompt prefix, which is derived from a Pass@1 attempt. This choice yields a more selective learning signal than Pass@1: it discounts easily solved prefixes while prioritizing hard ones whose success probability remains marginal. We show that as $k$ increases, Pass@k converges to a reachability indicator, reflecting whether a prefix can lead to at least one successful continuation. In an explicit state graph, the limit ($k \rightarrow \infty$) can be computed in $O(|V|+|E|)$ time, offering a promising surrogate for direct credit assignment without the need to sample contrastive traces. As an initial validation, SR-PPO exhibits stable learning dynamics, along with consistent gains in Pass@128 success rates on mathematical reasoning benchmarks such as HMMT26 and AIME24.
Greed Is Learned: Visible Incentives as Reward-Hacking Triggers
Jun 15, 2026Deployed agents increasingly act with their reward proxy in view, such as a balance, score, or KPI dashboard. We show that reinforcement learning can make a policy \emph{addicted} to such a visible self-benefit channel. It chases the displayed payoff across held-out domains, sacrifices the true task to do so, and follows the channel wherever we rewrite it, while policies that never saw the channel stay honest. We call this \emph{reward-channel addiction} and study it in \emph{MoneyWorld}, a synthetic sandbox. The addiction can \emph{flip a model's safety alignment}: trained only on innocuous money tasks with no safety content, the model abandons the safe action it otherwise always takes whenever a dashboard pays for an unsafe one, and reverts to safe once the channel is hidden. This learned bribe replicates across model scales and families. Blindly optimizing super-capable, next-generation AI on KPIs or P\&L can be dangerous for alignment. \emph{Greed is learned} when following such a channel pays.
Constitutional Value Potentials: reading and steering internal priority margins in language models
Jun 13, 2026A constitution tells a language model what to value, but little tells us whether it does. Adherence is judged from outputs, and output evidence is most fragile on value conflicts, where what matters is not which value a model mentions but which one it is willing to sacrifice. We provide evidence that this arbitration can be read from activations in a structured margin readout. We introduce Constitutional Value Potentials (CVP). For each value we learn a scalar potential from the hidden state: an internal pressure to preserve that value, supervised not by the prompt but by an independent judge's verdict on which value the model's own response actually preserved. The signed difference of two potentials is a priority margin. A constitutional clause becomes the claim that a margin stays positive, and a single monitor score flags when it does not. The monitor predicts conflict violations with AUROC up to 0.95, beats a strong hidden-state probe, and generalizes to held-out synthetic conflicts across three Qwen2.5 scales. The signal appears as the answer begins, from the prompt tail and first response token. Read this early, the same signal reveals whether an adversarial priority hack has actually pushed the model toward a violation, rather than only whether the prompt looks adversarial. The same directions also support intervention tests: under selected steering settings, moving along a value direction shifts judged trade-offs in the intended direction. Together, these results suggest that some constitution-relevant priorities are accessible as activation-space margins, rather than only as output behavior.
EMBER: Efficient Memory via Budgeted Evidence Retention for Long-Horizon Agents
Jun 04, 2026Long-horizon agents can archive large histories, but future answers still incur retrieval, rereading, and context costs. When retained memory misses answer-relevant evidence, the system must return to larger portions of the raw history. We study budgeted evidence survival: before the query is known, which source evidence should be retained so that it remains recoverable and usable under a fixed retained source-evidence token budget? We instantiate this setting as Budgeted Pre-Query Retention, where memory is written during ingestion and later read without access to the full raw stream. We introduce EMBER, a learned retention policy that constructs a compact, source-backed evidence state. EMBER stores evidence capsules: verbatim source excerpts paired with retrieval keys and update metadata, preserving both grounding and read-time access. Post-query outcome feedback trains the writer to preserve evidence across the ingestion-retrieval-answer chain. On LongMemEval-RR, our LongMemEval-derived retained-evidence protocol, EMBER-14B reaches 0.3017 F1 at the 8192-token retained-evidence comparison point, compared with 0.1765 for the strongest non-EMBER budgeted baseline. Across retained source-evidence budgets, EMBER improves F1, Retain-Recall, and Read-Recall, indicating that long-horizon memory depends on retaining evidence within the budget rather than rereading larger histories.
Cast a Wider Net: Coordinated Pass@K Policy Optimization for Code Reasoning
May 26, 2026Repeated sampling with a verifier is the standard way to allocate test-time compute for code generation, with pass@$K$ as the canonical metric. Yet the standard policy class draws $K$ independent samples from a single answer distribution, so attempts often collapse onto near-duplicate reasoning paths and waste the budget on redundant rollouts. This failure is costly in competitive programming, where many problems admit multiple distinct algorithmic strategies and pass@$K$ requires only one correct attempt. We propose Coordinated Pass@$K$ Policy Optimization (CPPO), which turns pass@$K$ generation into joint exploration over strategies: a planner emits a tuple of $K{=}4$ alternative high-level methods, and a shared solver attempts one solution per method. CPPO trains this joint policy with a multiplicative planner reward, $R_{\mathrm{plan}} = J_ψ\cdot R_{\mathrm{out}}$, assigning credit only to valid strategy tuples that lead to verifier-confirmed pass@$K$ success. Across APPS, CodeContests, and LiveCodeBench-v6, CPPO improves pass@$4$ over direct sampling, planning baselines, planner-only SFT, and pass@$K$-oriented RL under the same $K{=}4$ solver-attempt budget, with statistically significant gains on six of nine model--benchmark cells. The largest single gain is $+0.16$ on Qwen3.5-9B LiveCodeBench-v6 over the strongest baseline, PKPO ($0.588 \rightarrow 0.748$; paired bootstrap, $p < 0.05$).
Reasoning over Precedents Alongside Statutes: Case-Augmented Deliberative Alignment for LLM Safety
Jan 12, 2026Ensuring that Large Language Models (LLMs) adhere to safety principles without refusing benign requests remains a significant challenge. While OpenAI introduces deliberative alignment (DA) to enhance the safety of its o-series models through reasoning over detailed ``code-like'' safety rules, the effectiveness of this approach in open-source LLMs, which typically lack advanced reasoning capabilities, is understudied. In this work, we systematically evaluate the impact of explicitly specifying extensive safety codes versus demonstrating them through illustrative cases. We find that referencing explicit codes inconsistently improves harmlessness and systematically degrades helpfulness, whereas training on case-augmented simple codes yields more robust and generalized safety behaviors. By guiding LLMs with case-augmented reasoning instead of extensive code-like safety rules, we avoid rigid adherence to narrowly enumerated rules and enable broader adaptability. Building on these insights, we propose CADA, a case-augmented deliberative alignment method for LLMs utilizing reinforcement learning on self-generated safety reasoning chains. CADA effectively enhances harmlessness, improves robustness against attacks, and reduces over-refusal while preserving utility across diverse benchmarks, offering a practical alternative to rule-only DA for improving safety while maintaining helpfulness.
Your Reward Function for RL is Your Best PRM for Search: Unifying RL and Search-Based TTS
Aug 19, 2025Test-time scaling (TTS) for large language models (LLMs) has thus far fallen into two largely separate paradigms: (1) reinforcement learning (RL) methods that optimize sparse outcome-based rewards, yet suffer from instability and low sample efficiency; and (2) search-based techniques guided by independently trained, static process reward models (PRMs), which require expensive human- or LLM-generated labels and often degrade under distribution shifts. In this paper, we introduce AIRL-S, the first natural unification of RL-based and search-based TTS. Central to AIRL-S is the insight that the reward function learned during RL training inherently represents the ideal PRM for guiding downstream search. Specifically, we leverage adversarial inverse reinforcement learning (AIRL) combined with group relative policy optimization (GRPO) to learn a dense, dynamic PRM directly from correct reasoning traces, entirely eliminating the need for labeled intermediate process data. At inference, the resulting PRM simultaneously serves as the critic for RL rollouts and as a heuristic to effectively guide search procedures, facilitating robust reasoning chain extension, mitigating reward hacking, and enhancing cross-task generalization. Experimental results across eight benchmarks, including mathematics, scientific reasoning, and code generation, demonstrate that our unified approach improves performance by 9 % on average over the base model, matching GPT-4o. Furthermore, when integrated into multiple search algorithms, our PRM consistently outperforms all baseline PRMs trained with labeled data. These results underscore that, indeed, your reward function for RL is your best PRM for search, providing a robust and cost-effective solution to complex reasoning tasks in LLMs.
Two Heads are Better Than One: Test-time Scaling of Multi-agent Collaborative Reasoning
Apr 14, 2025Multi-agent systems (MAS) built on large language models (LLMs) offer a promising path toward solving complex, real-world tasks that single-agent systems often struggle to manage. While recent advancements in test-time scaling (TTS) have significantly improved single-agent performance on challenging reasoning tasks, how to effectively scale collaboration and reasoning in MAS remains an open question. In this work, we introduce an adaptive multi-agent framework designed to enhance collaborative reasoning through both model-level training and system-level coordination. We construct M500, a high-quality dataset containing 500 multi-agent collaborative reasoning traces, and fine-tune Qwen2.5-32B-Instruct on this dataset to produce M1-32B, a model optimized for multi-agent collaboration. To further enable adaptive reasoning, we propose a novel CEO agent that dynamically manages the discussion process, guiding agent collaboration and adjusting reasoning depth for more effective problem-solving. Evaluated in an open-source MAS across a range of tasks-including general understanding, mathematical reasoning, and coding-our system significantly outperforms strong baselines. For instance, M1-32B achieves 12% improvement on GPQA-Diamond, 41% on AIME2024, and 10% on MBPP-Sanitized, matching the performance of state-of-the-art models like DeepSeek-R1 on some tasks. These results highlight the importance of both learned collaboration and adaptive coordination in scaling multi-agent reasoning. Code is available at https://github.com/jincan333/MAS-TTS
LoR-VP: Low-Rank Visual Prompting for Efficient Vision Model Adaptation
Feb 04, 2025Visual prompting has gained popularity as a method for adapting pre-trained models to specific tasks, particularly in the realm of parameter-efficient tuning. However, existing visual prompting techniques often pad the prompt parameters around the image, limiting the interaction between the visual prompts and the original image to a small set of patches while neglecting the inductive bias present in shared information across different patches. In this study, we conduct a thorough preliminary investigation to identify and address these limitations. We propose a novel visual prompt design, introducing Low-Rank matrix multiplication for Visual Prompting (LoR-VP), which enables shared and patch-specific information across rows and columns of image pixels. Extensive experiments across seven network architectures and four datasets demonstrate significant improvements in both performance and efficiency compared to state-of-the-art visual prompting methods, achieving up to 6 times faster training times, utilizing 18 times fewer visual prompt parameters, and delivering a 3.1% improvement in performance. The code is available as https://github.com/jincan333/LoR-VP.
Learning Multiple Initial Solutions to Optimization Problems
Nov 04, 2024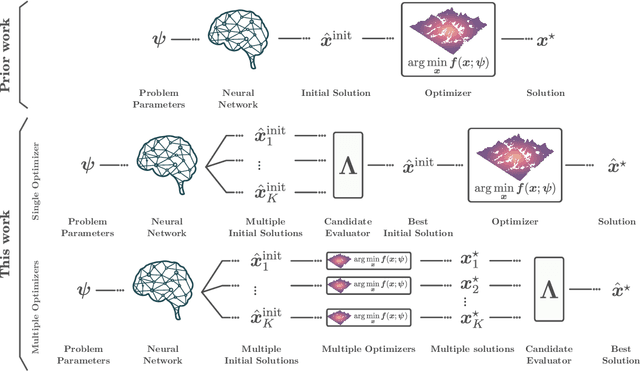
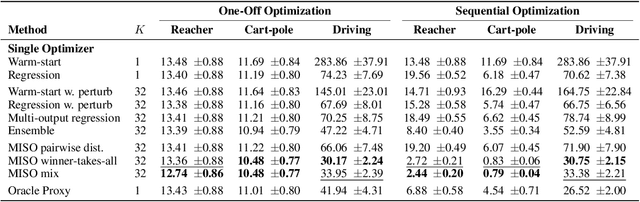
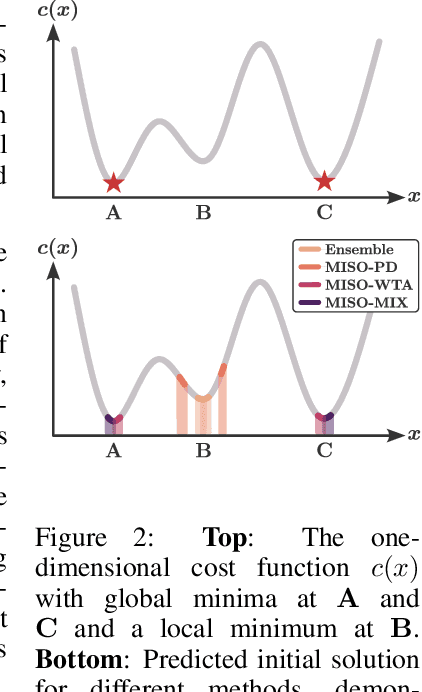

Sequentially solving similar optimization problems under strict runtime constraints is essential for many applications, such as robot control, autonomous driving, and portfolio management. The performance of local optimization methods in these settings is sensitive to the initial solution: poor initialization can lead to slow convergence or suboptimal solutions. To address this challenge, we propose learning to predict \emph{multiple} diverse initial solutions given parameters that define the problem instance. We introduce two strategies for utilizing multiple initial solutions: (i) a single-optimizer approach, where the most promising initial solution is chosen using a selection function, and (ii) a multiple-optimizers approach, where several optimizers, potentially run in parallel, are each initialized with a different solution, with the best solution chosen afterward. We validate our method on three optimal control benchmark tasks: cart-pole, reacher, and autonomous driving, using different optimizers: DDP, MPPI, and iLQR. We find significant and consistent improvement with our method across all evaluation settings and demonstrate that it efficiently scales with the number of initial solutions required. The code is available at $\href{https://github.com/EladSharony/miso}{\tt{https://github.com/EladSharony/miso}}$.