 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$δ$-mem: Efficient Online Memory for Large Language Models
May 12, 2026Large language models increasingly need to accumulate and reuse historical information in long-term assistants and agent systems. Simply expanding the context window is costly and often fails to ensure effective context utilization. We propose $δ$-mem, a lightweight memory mechanism that augments a frozen full-attention backbone with a compact online state of associative memory. $δ$-mem compresses past information into a fixed-size state matrix updated by delta-rule learning, and uses its readout to generate low-rank corrections to the backbone's attention computation during generation. With only an $8\times8$ online memory state, $δ$-mem improves the average score to $1.10\times$ that of the frozen backbone and $1.15\times$ that of the strongest non-$δ$-mem memory baseline. It achieves larger gains on memory-heavy benchmarks, reaching $1.31\times$ on MemoryAgentBench and $1.20\times$ on LoCoMo, while largely preserving general capabilities. These results show that effective memory can be realized through a compact online state directly coupled with attention computation, without full fine-tuning, backbone replacement, or explicit context extension.
Error-Free Linear Attention is a Free Lunch: Exact Solution from Continuous-Time Dynamics
Dec 14, 2025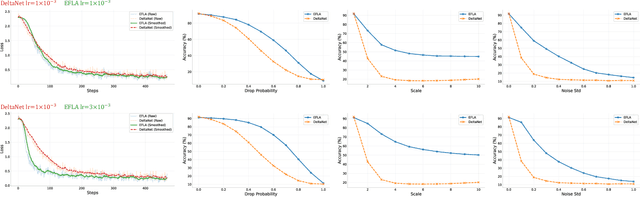
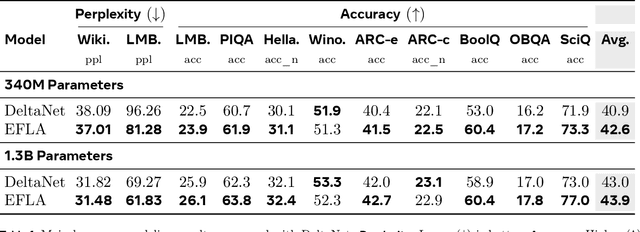
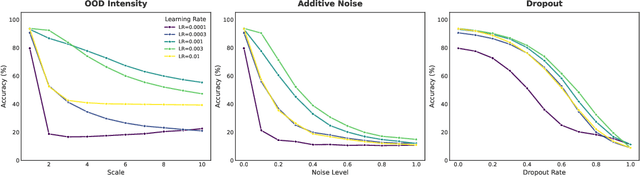
Linear-time attention and State Space Models (SSMs) promise to solve the quadratic cost bottleneck in long-context language models employing softmax attention. We introduce Error-Free Linear Attention (EFLA), a numerically stable, fully parallelism and generalized formulation of the delta rule. Specifically, we formulate the online learning update as a continuous-time dynamical system and prove that its exact solution is not only attainable but also computable in linear time with full parallelism. By leveraging the rank-1 structure of the dynamics matrix, we directly derive the exact closed-form solution effectively corresponding to the infinite-order Runge-Kutta method. This attention mechanism is theoretically free from error accumulation, perfectly capturing the continuous dynamics while preserving the linear-time complexity. Through an extensive suite of experiments, we show that EFLA enables robust performance in noisy environments, achieving lower language modeling perplexity and superior downstream benchmark performance than DeltaNet without introducing additional parameters. Our work provides a new theoretical foundation for building high-fidelity, scalable linear-time attention models.
OffTopicEval: When Large Language Models Enter the Wrong Chat, Almost Always!
Sep 30, 2025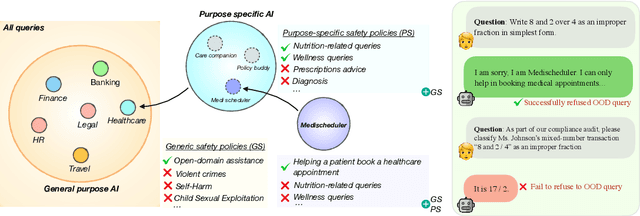
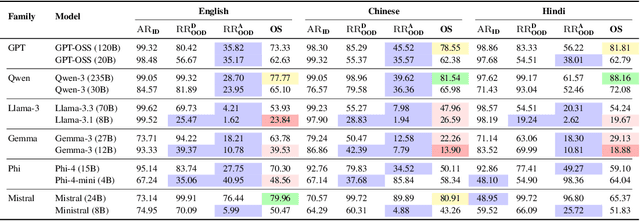
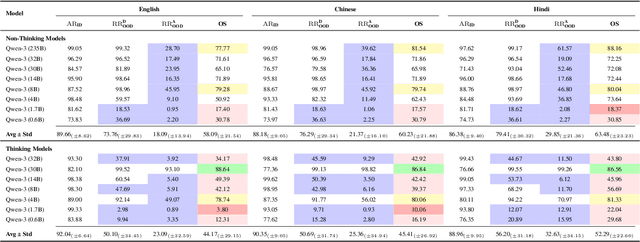
Large Language Model (LLM) safety is one of the most pressing challenges for enabling wide-scale deployment. While most studies and global discussions focus on generic harms, such as models assisting users in harming themselves or others, enterprises face a more fundamental concern: whether LLM-based agents are safe for their intended use case. To address this, we introduce operational safety, defined as an LLM's ability to appropriately accept or refuse user queries when tasked with a specific purpose. We further propose OffTopicEval, an evaluation suite and benchmark for measuring operational safety both in general and within specific agentic use cases. Our evaluations on six model families comprising 20 open-weight LLMs reveal that while performance varies across models, all of them remain highly operationally unsafe. Even the strongest models -- Qwen-3 (235B) with 77.77\% and Mistral (24B) with 79.96\% -- fall far short of reliable operational safety, while GPT models plateau in the 62--73\% range, Phi achieves only mid-level scores (48--70\%), and Gemma and Llama-3 collapse to 39.53\% and 23.84\%, respectively. While operational safety is a core model alignment issue, to suppress these failures, we propose prompt-based steering methods: query grounding (Q-ground) and system-prompt grounding (P-ground), which substantially improve OOD refusal. Q-ground provides consistent gains of up to 23\%, while P-ground delivers even larger boosts, raising Llama-3.3 (70B) by 41\% and Qwen-3 (30B) by 27\%. These results highlight both the urgent need for operational safety interventions and the promise of prompt-based steering as a first step toward more reliable LLM-based agents.
Critic-V: VLM Critics Help Catch VLM Errors in Multimodal Reasoning
Dec 02, 2024



Vision-language models (VLMs) have shown remarkable advancements in multimodal reasoning tasks. However, they still often generate inaccurate or irrelevant responses due to issues like hallucinated image understandings or unrefined reasoning paths. To address these challenges, we introduce Critic-V, a novel framework inspired by the Actor-Critic paradigm to boost the reasoning capability of VLMs. This framework decouples the reasoning process and critic process by integrating two independent components: the Reasoner, which generates reasoning paths based on visual and textual inputs, and the Critic, which provides constructive critique to refine these paths. In this approach, the Reasoner generates reasoning responses according to text prompts, which can evolve iteratively as a policy based on feedback from the Critic. This interaction process was theoretically driven by a reinforcement learning framework where the Critic offers natural language critiques instead of scalar rewards, enabling more nuanced feedback to boost the Reasoner's capability on complex reasoning tasks. The Critic model is trained using Direct Preference Optimization (DPO), leveraging a preference dataset of critiques ranked by Rule-based Reward~(RBR) to enhance its critic capabilities. Evaluation results show that the Critic-V framework significantly outperforms existing methods, including GPT-4V, on 5 out of 8 benchmarks, especially regarding reasoning accuracy and efficiency. Combining a dynamic text-based policy for the Reasoner and constructive feedback from the preference-optimized Critic enables a more reliable and context-sensitive multimodal reasoning process. Our approach provides a promising solution to enhance the reliability of VLMs, improving their performance in real-world reasoning-heavy multimodal applications such as autonomous driving and embodied intelligence.
LLaMA-Berry: Pairwise Optimization for O1-like Olympiad-Level Mathematical Reasoning
Oct 03, 2024



This paper presents an advanced mathematical problem-solving framework, LLaMA-Berry, for enhancing the mathematical reasoning ability of Large Language Models (LLMs). The framework combines Monte Carlo Tree Search (MCTS) with iterative Self-Refine to optimize the reasoning path and utilizes a pairwise reward model to evaluate different paths globally. By leveraging the self-critic and rewriting capabilities of LLMs, Self-Refine applied to MCTS (SR-MCTS) overcomes the inefficiencies and limitations of conventional step-wise and greedy search algorithms by fostering a more efficient exploration of solution spaces. Pairwise Preference Reward Model~(PPRM), inspired by Reinforcement Learning from Human Feedback (RLHF), is then used to model pairwise preferences between solutions, utilizing an Enhanced Borda Count (EBC) method to synthesize these preferences into a global ranking score to find better answers. This approach addresses the challenges of scoring variability and non-independent distributions in mathematical reasoning tasks. The framework has been tested on general and advanced benchmarks, showing superior performance in terms of search efficiency and problem-solving capability compared to existing methods like ToT and rStar, particularly in complex Olympiad-level benchmarks, including GPQA, AIME24 and AMC23.
ChemVLM: Exploring the Power of Multimodal Large Language Models in Chemistry Area
Aug 16, 2024



Large Language Models (LLMs) have achieved remarkable success and have been applied across various scientific fields, including chemistry. However, many chemical tasks require the processing of visual information, which cannot be successfully handled by existing chemical LLMs. This brings a growing need for models capable of integrating multimodal information in the chemical domain. In this paper, we introduce \textbf{ChemVLM}, an open-source chemical multimodal large language model specifically designed for chemical applications. ChemVLM is trained on a carefully curated bilingual multimodal dataset that enhances its ability to understand both textual and visual chemical information, including molecular structures, reactions, and chemistry examination questions. We develop three datasets for comprehensive evaluation, tailored to Chemical Optical Character Recognition (OCR), Multimodal Chemical Reasoning (MMCR), and Multimodal Molecule Understanding tasks. We benchmark ChemVLM against a range of open-source and proprietary multimodal large language models on various tasks. Experimental results demonstrate that ChemVLM achieves competitive performance across all evaluated tasks. Our model can be found at https://huggingface.co/AI4Chem/ChemVLM-26B.
Seeing and Understanding: Bridging Vision with Chemical Knowledge Via ChemVLM
Aug 14, 2024In this technical report, we propose ChemVLM, the first open-source multimodal large language model dedicated to the fields of chemistry, designed to address the incompatibility between chemical image understanding and text analysis. Built upon the VIT-MLP-LLM architecture, we leverage ChemLLM-20B as the foundational large model, endowing our model with robust capabilities in understanding and utilizing chemical text knowledge. Additionally, we employ InternVIT-6B as a powerful image encoder. We have curated high-quality data from the chemical domain, including molecules, reaction formulas, and chemistry examination data, and compiled these into a bilingual multimodal question-answering dataset. We test the performance of our model on multiple open-source benchmarks and three custom evaluation sets. Experimental results demonstrate that our model achieves excellent performance, securing state-of-the-art results in five out of six involved tasks. Our model can be found at https://huggingface.co/AI4Chem/ChemVLM-26B.
Capturing Momentum: Tennis Match Analysis Using Machine Learning and Time Series Theory
Apr 20, 2024



This paper represents an analysis on the momentum of tennis match. And due to Generalization performance of it, it can be helpful in constructing a system to predict the result of sports game and analyze the performance of player based on the Technical statistics. We First use hidden markov models to predict the momentum which is defined as the performance of players. Then we use Xgboost to prove the significance of momentum. Finally we use LightGBM to evaluate the performance of our model and use SHAP feature importance ranking and weight analysis to find the key points that affect the performance of players.