 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLAP: Contrastive Latent Action Pretraining for Learning Vision-Language-Action Models from Human Videos
Jan 07, 2026Generalist Vision-Language-Action models are currently hindered by the scarcity of robotic data compared to the abundance of human video demonstrations. Existing Latent Action Models attempt to leverage video data but often suffer from visual entanglement, capturing noise rather than manipulation skills. To address this, we propose Contrastive Latent Action Pretraining (CLAP), a framework that aligns the visual latent space from videos with a proprioceptive latent space from robot trajectories. By employing contrastive learning, CLAP maps video transitions onto a quantized, physically executable codebook. Building on this representation, we introduce a dual-formulation VLA framework offering both CLAP-NTP, an autoregressive model excelling at instruction following and object generalization, and CLAP-RF, a Rectified Flow-based policy designed for high-frequency, precise manipulation. Furthermore, we propose a Knowledge Matching (KM) regularization strategy to mitigate catastrophic forgetting during fine-tuning. Extensive experiments demonstrate that CLAP significantly outperforms strong baselines, enabling the effective transfer of skills from human videos to robotic execution. Project page: https://lin-shan.com/CLAP/.
What Affects the Effective Depth of Large Language Models?
Dec 16, 2025



The scaling of large language models (LLMs) emphasizes increasing depth, yet performance gains diminish with added layers. Prior work introduces the concept of "effective depth", arguing that deeper models fail to fully utilize their layers for meaningful computation. Building on this, we systematically study how effective depth varies with model scale, training type, and task difficulty. First, we analyze the model behavior of Qwen-2.5 family (1.5B-32B) and find that while the number of effective layers grows with model size, the effective depth ratio remains stable. Besides, comparisons between base and corresponding long-CoT models show no increase in effective depth, suggesting that improved reasoning stems from longer context rather than deeper per-token computation. Furthermore, evaluations across tasks of varying difficulty indicate that models do not dynamically use more layers for harder problems. Our results suggest that current LLMs underuse available depth across scales, training paradigms and tasks of varying difficulties, pointing out research opportunities on increasing the layer utilization rate of LLMs, model pruning, and early exiting. Our code is released at https://github.com/AheadOFpotato/what_affects_effective_depth.
SPG: Sandwiched Policy Gradient for Masked Diffusion Language Models
Oct 10, 2025Diffusion large language models (dLLMs) are emerging as an efficient alternative to autoregressive models due to their ability to decode multiple tokens in parallel. However, aligning dLLMs with human preferences or task-specific rewards via reinforcement learning (RL) is challenging because their intractable log-likelihood precludes the direct application of standard policy gradient methods. While prior work uses surrogates like the evidence lower bound (ELBO), these one-sided approximations can introduce significant policy gradient bias. To address this, we propose the Sandwiched Policy Gradient (SPG) that leverages both an upper and a lower bound of the true log-likelihood. Experiments show that SPG significantly outperforms baselines based on ELBO or one-step estimation. Specifically, SPG improves the accuracy over state-of-the-art RL methods for dLLMs by 3.6% in GSM8K, 2.6% in MATH500, 18.4% in Countdown and 27.0% in Sudoku.
Thought calibration: Efficient and confident test-time scaling
May 23, 2025Reasoning large language models achieve impressive test-time scaling by thinking for longer, but this performance gain comes at significant compute cost. Directly limiting test-time budget hurts overall performance, but not all problems are equally difficult. We propose thought calibration to decide dynamically when thinking can be terminated. To calibrate our decision rule, we view a language model's growing body of thoughts as a nested sequence of reasoning trees, where the goal is to identify the point at which novel reasoning plateaus. We realize this framework through lightweight probes that operate on top of the language model's hidden representations, which are informative of both the reasoning structure and overall consistency of response. Based on three reasoning language models and four datasets, thought calibration preserves model performance with up to a 60% reduction in thinking tokens on in-distribution data, and up to 20% in out-of-distribution data.
FiTv2: Scalable and Improved Flexible Vision Transformer for Diffusion Model
Oct 17, 2024



\textit{Nature is infinitely resolution-free}. In the context of this reality, existing diffusion models, such as Diffusion Transformers, often face challenges when processing image resolutions outside of their trained domain. To address this limitation, we conceptualize images as sequences of tokens with dynamic sizes, rather than traditional methods that perceive images as fixed-resolution grids. This perspective enables a flexible training strategy that seamlessly accommodates various aspect ratios during both training and inference, thus promoting resolution generalization and eliminating biases introduced by image cropping. On this basis, we present the \textbf{Flexible Vision Transformer} (FiT), a transformer architecture specifically designed for generating images with \textit{unrestricted resolutions and aspect ratios}. We further upgrade the FiT to FiTv2 with several innovative designs, includingthe Query-Key vector normalization, the AdaLN-LoRA module, a rectified flow scheduler, and a Logit-Normal sampler. Enhanced by a meticulously adjusted network structure, FiTv2 exhibits $2\times$ convergence speed of FiT. When incorporating advanced training-free extrapolation techniques, FiTv2 demonstrates remarkable adaptability in both resolution extrapolation and diverse resolution generation. Additionally, our exploration of the scalability of the FiTv2 model reveals that larger models exhibit better computational efficiency. Furthermore, we introduce an efficient post-training strategy to adapt a pre-trained model for the high-resolution generation. Comprehensive experiments demonstrate the exceptional performance of FiTv2 across a broad range of resolutions. We have released all the codes and models at \url{https://github.com/whlzy/FiT} to promote the exploration of diffusion transformer models for arbitrary-resolution image generation.
Towards Stable, Globally Expressive Graph Representations with Laplacian Eigenvectors
Oct 13, 2024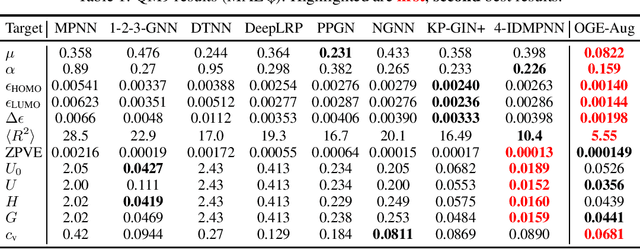
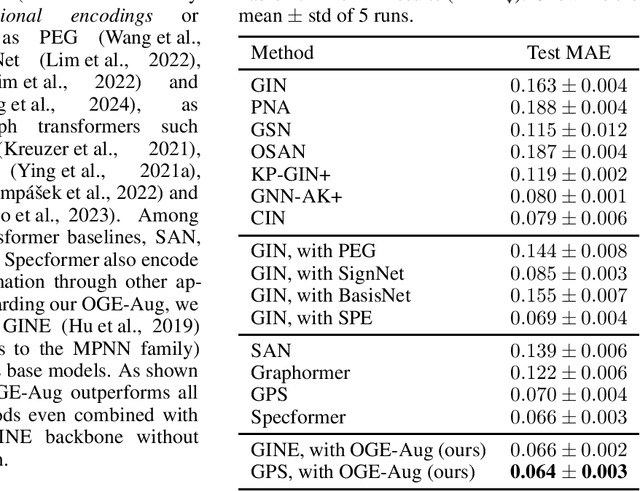

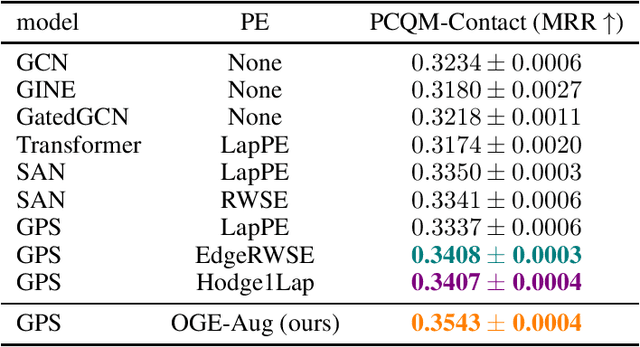
Graph neural networks (GNNs) have achieved remarkable success in a variety of machine learning tasks over graph data. Existing GNNs usually rely on message passing, i.e., computing node representations by gathering information from the neighborhood, to build their underlying computational graphs. They are known fairly limited in expressive power, and often fail to capture global characteristics of graphs. To overcome the issue, a popular solution is to use Laplacian eigenvectors as additional node features, as they contain global positional information of nodes, and can serve as extra node identifiers aiding GNNs to separate structurally similar nodes. For such an approach, properly handling the orthogonal group symmetry among eigenvectors with equal eigenvalue is crucial for its stability and generalizability. However, using a naive orthogonal group invariant encoder for each separate eigenspace may not keep the full expressivity in the Laplacian eigenvectors. Moreover, computing such invariants inevitably entails a hard split of Laplacian eigenvalues according to their numerical identity, which suffers from great instability when the graph structure is perturbed. In this paper, we propose a novel method exploiting Laplacian eigenvectors to generate stable and globally expressive graph representations. The main difference from previous works is that (i) our method utilizes learnable orthogonal group invariant representations for each Laplacian eigenspace, based upon powerful orthogonal group equivariant neural network layers already well studied in the literature, and that (ii) our method deals with numerically close eigenvalues in a smooth fashion, ensuring its better robustness against perturbations. Experiments on various graph learning benchmarks witness the competitive performance of our method, especially its great potential to learn global properties of graphs.
Geometric Representation Condition Improves Equivariant Molecule Generation
Oct 04, 2024



Recent advancements in molecular generative models have demonstrated substantial potential in accelerating scientific discovery, particularly in drug design. However, these models often face challenges in generating high-quality molecules, especially in conditional scenarios where specific molecular properties must be satisfied. In this work, we introduce GeoRCG, a general framework to enhance the performance of molecular generative models by integrating geometric representation conditions. We decompose the molecule generation process into two stages: first, generating an informative geometric representation; second, generating a molecule conditioned on the representation. Compared to directly generating a molecule, the relatively easy-to-generate representation in the first-stage guides the second-stage generation to reach a high-quality molecule in a more goal-oriented and much faster way. Leveraging EDM as the base generator, we observe significant quality improvements in unconditional molecule generation on the widely-used QM9 and GEOM-DRUG datasets. More notably, in the challenging conditional molecular generation task, our framework achieves an average 31\% performance improvement over state-of-the-art approaches, highlighting the superiority of conditioning on semantically rich geometric representations over conditioning on individual property values as in previous approaches. Furthermore, we show that, with such representation guidance, the number of diffusion steps can be reduced to as small as 100 while maintaining superior generation quality than that achieved with 1,000 steps, thereby significantly accelerating the generation process.
ChemVLM: Exploring the Power of Multimodal Large Language Models in Chemistry Area
Aug 16, 2024



Large Language Models (LLMs) have achieved remarkable success and have been applied across various scientific fields, including chemistry. However, many chemical tasks require the processing of visual information, which cannot be successfully handled by existing chemical LLMs. This brings a growing need for models capable of integrating multimodal information in the chemical domain. In this paper, we introduce \textbf{ChemVLM}, an open-source chemical multimodal large language model specifically designed for chemical applications. ChemVLM is trained on a carefully curated bilingual multimodal dataset that enhances its ability to understand both textual and visual chemical information, including molecular structures, reactions, and chemistry examination questions. We develop three datasets for comprehensive evaluation, tailored to Chemical Optical Character Recognition (OCR), Multimodal Chemical Reasoning (MMCR), and Multimodal Molecule Understanding tasks. We benchmark ChemVLM against a range of open-source and proprietary multimodal large language models on various tasks. Experimental results demonstrate that ChemVLM achieves competitive performance across all evaluated tasks. Our model can be found at https://huggingface.co/AI4Chem/ChemVLM-26B.
Seeing and Understanding: Bridging Vision with Chemical Knowledge Via ChemVLM
Aug 14, 2024In this technical report, we propose ChemVLM, the first open-source multimodal large language model dedicated to the fields of chemistry, designed to address the incompatibility between chemical image understanding and text analysis. Built upon the VIT-MLP-LLM architecture, we leverage ChemLLM-20B as the foundational large model, endowing our model with robust capabilities in understanding and utilizing chemical text knowledge. Additionally, we employ InternVIT-6B as a powerful image encoder. We have curated high-quality data from the chemical domain, including molecules, reaction formulas, and chemistry examination data, and compiled these into a bilingual multimodal question-answering dataset. We test the performance of our model on multiple open-source benchmarks and three custom evaluation sets. Experimental results demonstrate that our model achieves excellent performance, securing state-of-the-art results in five out of six involved tasks. Our model can be found at https://huggingface.co/AI4Chem/ChemVLM-26B.
On the Theoretical Expressive Power and the Design Space of Higher-Order Graph Transformers
Apr 04, 2024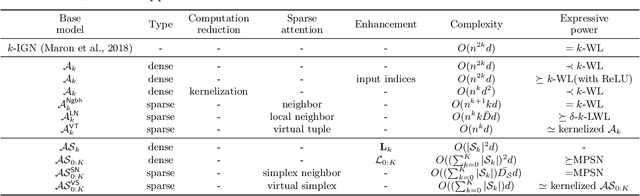
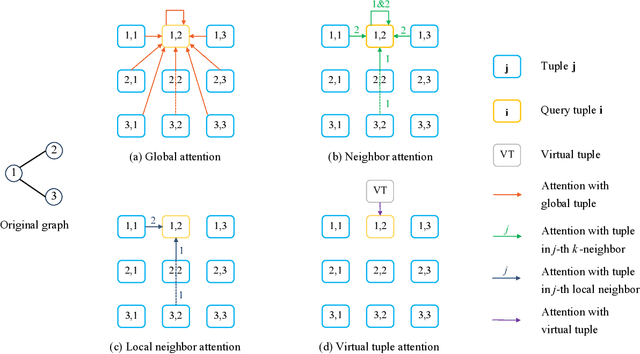


Graph transformers have recently received significant attention in graph learning, partly due to their ability to capture more global interaction via self-attention. Nevertheless, while higher-order graph neural networks have been reasonably well studied, the exploration of extending graph transformers to higher-order variants is just starting. Both theoretical understanding and empirical results are limited. In this paper, we provide a systematic study of the theoretical expressive power of order-$k$ graph transformers and sparse variants. We first show that, an order-$k$ graph transformer without additional structural information is less expressive than the $k$-Weisfeiler Lehman ($k$-WL) test despite its high computational cost. We then explore strategies to both sparsify and enhance the higher-order graph transformers, aiming to improve both their efficiency and expressiveness. Indeed, sparsification based on neighborhood information can enhance the expressive power, as it provides additional information about input graph structures. In particular, we show that a natural neighborhood-based sparse order-$k$ transformer model is not only computationally efficient, but also expressive -- as expressive as $k$-WL test. We further study several other sparse graph attention models that are computationally efficient and provide their expressiveness analysis. Finally, we provide experimental results to show the effectiveness of the different sparsification strategies.