 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Cultural Bias in LLMs via Multi-Agent Cultural Debate
Jan 17, 2026Large language models (LLMs) exhibit systematic Western-centric bias, yet whether prompting in non-Western languages (e.g., Chinese) can mitigate this remains understudied. Answering this question requires rigorous evaluation and effective mitigation, but existing approaches fall short on both fronts: evaluation methods force outputs into predefined cultural categories without a neutral option, while mitigation relies on expensive multi-cultural corpora or agent frameworks that use functional roles (e.g., Planner--Critique) lacking explicit cultural representation. To address these gaps, we introduce CEBiasBench, a Chinese--English bilingual benchmark, and Multi-Agent Vote (MAV), which enables explicit ``no bias'' judgments. Using this framework, we find that Chinese prompting merely shifts bias toward East Asian perspectives rather than eliminating it. To mitigate such persistent bias, we propose Multi-Agent Cultural Debate (MACD), a training-free framework that assigns agents distinct cultural personas and orchestrates deliberation via a "Seeking Common Ground while Reserving Differences" strategy. Experiments demonstrate that MACD achieves 57.6% average No Bias Rate evaluated by LLM-as-judge and 86.0% evaluated by MAV (vs. 47.6% and 69.0% baseline using GPT-4o as backbone) on CEBiasBench and generalizes to the Arabic CAMeL benchmark, confirming that explicit cultural representation in agent frameworks is essential for cross-cultural fairness.
ChemMLLM: Chemical Multimodal Large Language Model
May 22, 2025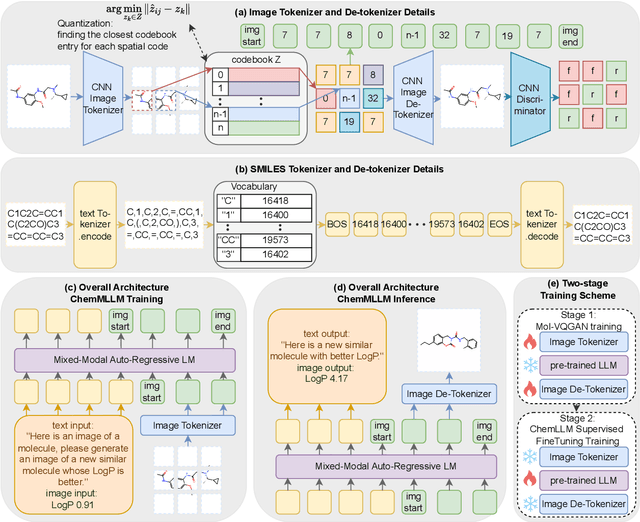
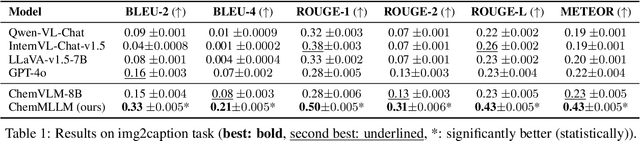


Multimodal large language models (MLLMs) have made impressive progress in many applications in recent years. However, chemical MLLMs that can handle cross-modal understanding and generation remain underexplored. To fill this gap, in this paper, we propose ChemMLLM, a unified chemical multimodal large language model for molecule understanding and generation. Also, we design five multimodal tasks across text, molecular SMILES strings, and image, and curate the datasets. We benchmark ChemMLLM against a range of general leading MLLMs and Chemical LLMs on these tasks. Experimental results show that ChemMLLM achieves superior performance across all evaluated tasks. For example, in molecule image optimization task, ChemMLLM outperforms the best baseline (GPT-4o) by 118.9\% (4.27 vs 1.95 property improvement). The code is publicly available at https://github.com/bbsbz/ChemMLLM.git.
ChemVLM: Exploring the Power of Multimodal Large Language Models in Chemistry Area
Aug 16, 2024



Large Language Models (LLMs) have achieved remarkable success and have been applied across various scientific fields, including chemistry. However, many chemical tasks require the processing of visual information, which cannot be successfully handled by existing chemical LLMs. This brings a growing need for models capable of integrating multimodal information in the chemical domain. In this paper, we introduce \textbf{ChemVLM}, an open-source chemical multimodal large language model specifically designed for chemical applications. ChemVLM is trained on a carefully curated bilingual multimodal dataset that enhances its ability to understand both textual and visual chemical information, including molecular structures, reactions, and chemistry examination questions. We develop three datasets for comprehensive evaluation, tailored to Chemical Optical Character Recognition (OCR), Multimodal Chemical Reasoning (MMCR), and Multimodal Molecule Understanding tasks. We benchmark ChemVLM against a range of open-source and proprietary multimodal large language models on various tasks. Experimental results demonstrate that ChemVLM achieves competitive performance across all evaluated tasks. Our model can be found at https://huggingface.co/AI4Chem/ChemVLM-26B.
Seeing and Understanding: Bridging Vision with Chemical Knowledge Via ChemVLM
Aug 14, 2024In this technical report, we propose ChemVLM, the first open-source multimodal large language model dedicated to the fields of chemistry, designed to address the incompatibility between chemical image understanding and text analysis. Built upon the VIT-MLP-LLM architecture, we leverage ChemLLM-20B as the foundational large model, endowing our model with robust capabilities in understanding and utilizing chemical text knowledge. Additionally, we employ InternVIT-6B as a powerful image encoder. We have curated high-quality data from the chemical domain, including molecules, reaction formulas, and chemistry examination data, and compiled these into a bilingual multimodal question-answering dataset. We test the performance of our model on multiple open-source benchmarks and three custom evaluation sets. Experimental results demonstrate that our model achieves excellent performance, securing state-of-the-art results in five out of six involved tasks. Our model can be found at https://huggingface.co/AI4Chem/ChemVLM-26B.
Unveiling the Lexical Sensitivity of LLMs: Combinatorial Optimization for Prompt Enhancement
May 31, 2024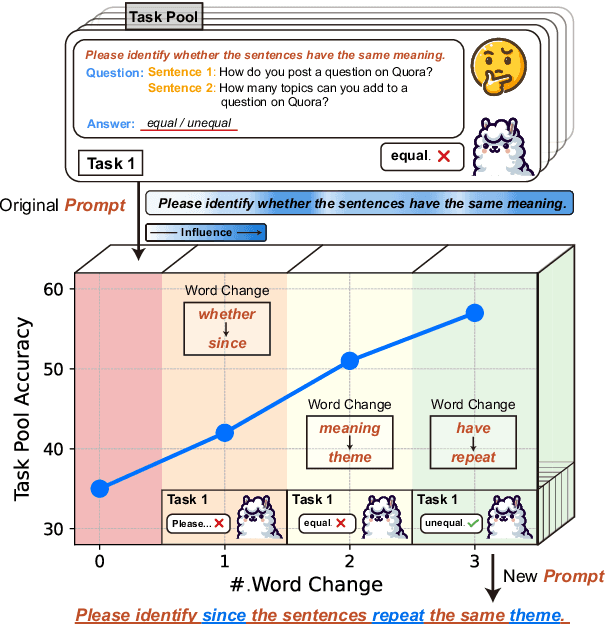
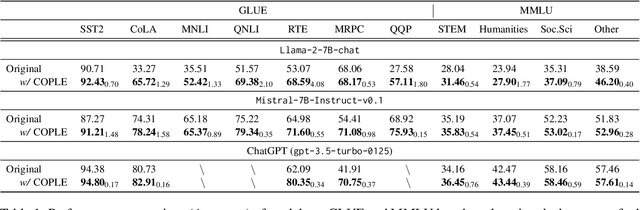
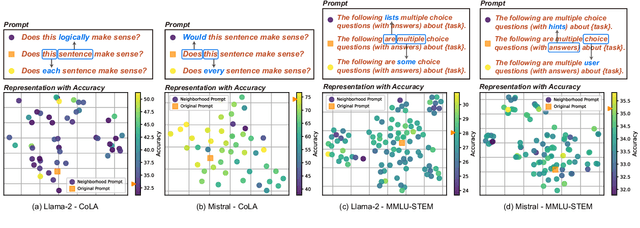

Large language models (LLMs) demonstrate exceptional instruct-following ability to complete various downstream tasks. Although this impressive ability makes LLMs flexible task solvers, their performance in solving tasks also heavily relies on instructions. In this paper, we reveal that LLMs are over-sensitive to lexical variations in task instructions, even when the variations are imperceptible to humans. By providing models with neighborhood instructions, which are closely situated in the latent representation space and differ by only one semantically similar word, the performance on downstream tasks can be vastly different. Following this property, we propose a black-box Combinatorial Optimization framework for Prompt Lexical Enhancement (COPLE). COPLE performs iterative lexical optimization according to the feedback from a batch of proxy tasks, using a search strategy related to word influence. Experiments show that even widely-used human-crafted prompts for current benchmarks suffer from the lexical sensitivity of models, and COPLE recovers the declined model ability in both instruct-following and solving downstream tasks.
ChemLLM: A Chemical Large Language Model
Feb 10, 2024



Large language models (LLMs) have made impressive progress in chemistry applications, including molecular property prediction, molecular generation, experimental protocol design, etc. However, the community lacks a dialogue-based model specifically designed for chemistry. The challenge arises from the fact that most chemical data and scientific knowledge are primarily stored in structured databases, and the direct use of these structured data compromises the model's ability to maintain coherent dialogue. To tackle this issue, we develop a novel template-based instruction construction method that transforms structured knowledge into plain dialogue, making it suitable for language model training. By leveraging this approach, we develop ChemLLM, the first large language model dedicated to chemistry, capable of performing various tasks across chemical disciplines with smooth dialogue interaction. ChemLLM beats GPT-3.5 on all three principal tasks in chemistry, i.e., name conversion, molecular caption, and reaction prediction, and surpasses GPT-4 on two of them. Remarkably, ChemLLM also shows exceptional adaptability to related mathematical and physical tasks despite being trained mainly on chemical-centric corpora. Furthermore, ChemLLM demonstrates proficiency in specialized NLP tasks within chemistry, such as literature translation and cheminformatic programming. ChemLLM opens up a new avenue for exploration within chemical studies, while our method of integrating structured chemical knowledge into dialogue systems sets a new frontier for developing LLMs across various scientific fields. Codes, Datasets, and Model weights are publicly accessible at hf.co/AI4Chem/ChemLLM-7B-Chat.