 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreamMeCo: Long-Term Agent Memory Compression for Efficient Streaming Video Understanding
Apr 10, 2026Vision agent memory has shown remarkable effectiveness in streaming video understanding. However, storing such memory for videos incurs substantial memory overhead, leading to high costs in both storage and computation. To address this issue, we propose StreamMeCo, an efficient Stream Agent Memory Compression framework. Specifically, based on the connectivity of the memory graph, StreamMeCo introduces edge-free minmax sampling for the isolated nodes and an edge-aware weight pruning for connected nodes, evicting the redundant memory nodes while maintaining the accuracy. In addition, we introduce a time-decay memory retrieval mechanism to further eliminate the performance degradation caused by memory compression. Extensive experiments on three challenging benchmark datasets (M3-Bench-robot, M3-Bench-web and Video-MME-Long) demonstrate that under 70% memory graph compression, StreamMeCo achieves a 1.87* speedup in memory retrieval while delivering an average accuracy improvement of 1.0%. Our code is available at https://github.com/Celina-love-sweet/StreamMeCo.
AttnDiff: Attention-based Differential Fingerprinting for Large Language Models
Apr 07, 2026Protecting the intellectual property of open-weight large language models (LLMs) requires verifying whether a suspect model is derived from a victim model despite common laundering operations such as fine-tuning (including PPO/DPO), pruning/compression, and model merging. We propose \textsc{AttnDiff}, a data-efficient white-box framework that extracts fingerprints from models via intrinsic information-routing behavior. \textsc{AttnDiff} probes minimally edited prompt pairs that induce controlled semantic conflicts, captures differential attention patterns, summarizes them with compact spectral descriptors, and compares models using CKA. Across Llama-2/3 and Qwen2.5 (3B--14B) and additional open-source families, it yields high similarity for related derivatives while separating unrelated model families (e.g., $>0.98$ vs.\ $<0.22$ with $M=60$ probes). With 5--60 multi-domain probes, it supports practical provenance verification and accountability.
SlowBA: An efficiency backdoor attack towards VLM-based GUI agents
Mar 10, 2026Modern vision-language-model (VLM) based graphical user interface (GUI) agents are expected not only to execute actions accurately but also to respond to user instructions with low latency. While existing research on GUI-agent security mainly focuses on manipulating action correctness, the security risks related to response efficiency remain largely unexplored. In this paper, we introduce SlowBA, a novel backdoor attack that targets the responsiveness of VLM-based GUI agents. The key idea is to manipulate response latency by inducing excessively long reasoning chains under specific trigger patterns. To achieve this, we propose a two-stage reward-level backdoor injection (RBI) strategy that first aligns the long-response format and then learns trigger-aware activation through reinforcement learning. In addition, we design realistic pop-up windows as triggers that naturally appear in GUI environments, improving the stealthiness of the attack. Extensive experiments across multiple datasets and baselines demonstrate that SlowBA can significantly increase response length and latency while largely preserving task accuracy. The attack remains effective even with a small poisoning ratio and under several defense settings. These findings reveal a previously overlooked security vulnerability in GUI agents and highlight the need for defenses that consider both action correctness and response efficiency. Code can be found in https://github.com/tu-tuing/SlowBA.
PlanViz: Evaluating Planning-Oriented Image Generation and Editing for Computer-Use Tasks
Feb 06, 2026Unified multimodal models (UMMs) have shown impressive capabilities in generating natural images and supporting multimodal reasoning. However, their potential in supporting computer-use planning tasks, which are closely related to our lives, remain underexplored. Image generation and editing in computer-use tasks require capabilities like spatial reasoning and procedural understanding, and it is still unknown whether UMMs have these capabilities to finish these tasks or not. Therefore, we propose PlanViz, a new benchmark designed to evaluate image generation and editing for computer-use tasks. To achieve the goal of our evaluation, we focus on sub-tasks which frequently involve in daily life and require planning steps. Specifically, three new sub-tasks are designed: route planning, work diagramming, and web&UI displaying. We address challenges in data quality ensuring by curating human-annotated questions and reference images, and a quality control process. For challenges of comprehensive and exact evaluation, a task-adaptive score, PlanScore, is proposed. The score helps understanding the correctness, visual quality and efficiency of generated images. Through experiments, we highlight key limitations and opportunities for future research on this topic.
FaithAct: Faithfulness Planning and Acting in MLLMs
Nov 11, 2025Unfaithfulness remains a persistent challenge for large language models (LLMs), which often produce plausible yet ungrounded reasoning chains that diverge from perceptual evidence or final conclusions. We distinguish between behavioral faithfulness (alignment between reasoning and output) and perceptual faithfulness (alignment between reasoning and input), and introduce FaithEval for quantifying step-level and chain-level faithfulness by evaluating whether each claimed object is visually supported by the image. Building on these insights, we propose FaithAct, a faithfulness-first planning and acting framework that enforces evidential grounding at every reasoning step. Experiments across multiple reasoning benchmarks demonstrate that FaithAct improves perceptual faithfulness by up to 26% without degrading task accuracy compared to prompt-based and tool-augmented baselines. Our analysis shows that treating faithfulness as a guiding principle not only mitigates hallucination but also leads to more stable reasoning trajectories. This work thereby establishes a unified framework for both evaluating and enforcing faithfulness in multimodal reasoning.
AI for Service: Proactive Assistance with AI Glasses
Oct 16, 2025In an era where AI is evolving from a passive tool into an active and adaptive companion, we introduce AI for Service (AI4Service), a new paradigm that enables proactive and real-time assistance in daily life. Existing AI services remain largely reactive, responding only to explicit user commands. We argue that a truly intelligent and helpful assistant should be capable of anticipating user needs and taking actions proactively when appropriate. To realize this vision, we propose Alpha-Service, a unified framework that addresses two fundamental challenges: Know When to intervene by detecting service opportunities from egocentric video streams, and Know How to provide both generalized and personalized services. Inspired by the von Neumann computer architecture and based on AI glasses, Alpha-Service consists of five key components: an Input Unit for perception, a Central Processing Unit for task scheduling, an Arithmetic Logic Unit for tool utilization, a Memory Unit for long-term personalization, and an Output Unit for natural human interaction. As an initial exploration, we implement Alpha-Service through a multi-agent system deployed on AI glasses. Case studies, including a real-time Blackjack advisor, a museum tour guide, and a shopping fit assistant, demonstrate its ability to seamlessly perceive the environment, infer user intent, and provide timely and useful assistance without explicit prompts.
Mol-R1: Towards Explicit Long-CoT Reasoning in Molecule Discovery
Aug 11, 2025Large language models (LLMs), especially Explicit Long Chain-of-Thought (CoT) reasoning models like DeepSeek-R1 and QWQ, have demonstrated powerful reasoning capabilities, achieving impressive performance in commonsense reasoning and mathematical inference. Despite their effectiveness, Long-CoT reasoning models are often criticized for their limited ability and low efficiency in knowledge-intensive domains such as molecule discovery. Success in this field requires a precise understanding of domain knowledge, including molecular structures and chemical principles, which is challenging due to the inherent complexity of molecular data and the scarcity of high-quality expert annotations. To bridge this gap, we introduce Mol-R1, a novel framework designed to improve explainability and reasoning performance of R1-like Explicit Long-CoT reasoning LLMs in text-based molecule generation. Our approach begins with a high-quality reasoning dataset curated through Prior Regulation via In-context Distillation (PRID), a dedicated distillation strategy to effectively generate paired reasoning traces guided by prior regulations. Building upon this, we introduce MoIA, Molecular Iterative Adaptation, a sophisticated training strategy that iteratively combines Supervised Fine-tuning (SFT) with Reinforced Policy Optimization (RPO), tailored to boost the reasoning performance of R1-like reasoning models for molecule discovery. Finally, we examine the performance of Mol-R1 in the text-based molecule reasoning generation task, showing superior performance against existing baselines.
Design and Evaluation of Deep Learning-Based Dual-Spectrum Image Fusion Methods
Jun 09, 2025Visible images offer rich texture details, while infrared images emphasize salient targets. Fusing these complementary modalities enhances scene understanding, particularly for advanced vision tasks under challenging conditions. Recently, deep learning-based fusion methods have gained attention, but current evaluations primarily rely on general-purpose metrics without standardized benchmarks or downstream task performance. Additionally, the lack of well-developed dual-spectrum datasets and fair algorithm comparisons hinders progress. To address these gaps, we construct a high-quality dual-spectrum dataset captured in campus environments, comprising 1,369 well-aligned visible-infrared image pairs across four representative scenarios: daytime, nighttime, smoke occlusion, and underpasses. We also propose a comprehensive and fair evaluation framework that integrates fusion speed, general metrics, and object detection performance using the lang-segment-anything model to ensure fairness in downstream evaluation. Extensive experiments benchmark several state-of-the-art fusion algorithms under this framework. Results demonstrate that fusion models optimized for downstream tasks achieve superior performance in target detection, especially in low-light and occluded scenes. Notably, some algorithms that perform well on general metrics do not translate to strong downstream performance, highlighting limitations of current evaluation practices and validating the necessity of our proposed framework. The main contributions of this work are: (1)a campus-oriented dual-spectrum dataset with diverse and challenging scenes; (2) a task-aware, comprehensive evaluation framework; and (3) thorough comparative analysis of leading fusion methods across multiple datasets, offering insights for future development.
Biology Instructions: A Dataset and Benchmark for Multi-Omics Sequence Understanding Capability of Large Language Models
Dec 26, 2024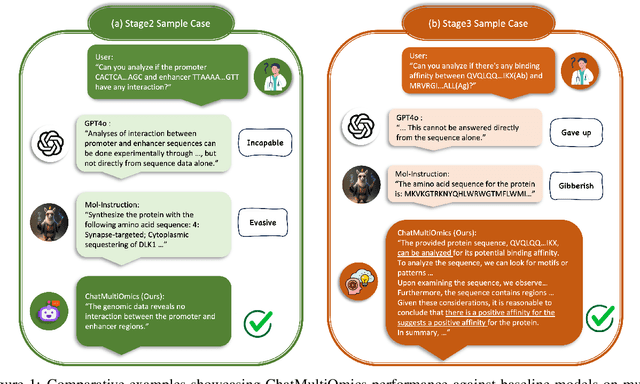
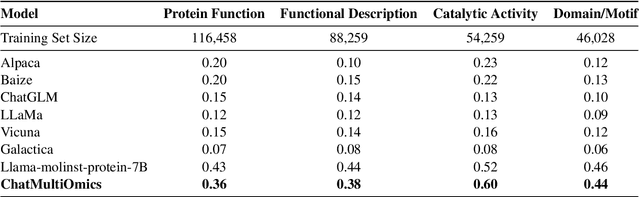
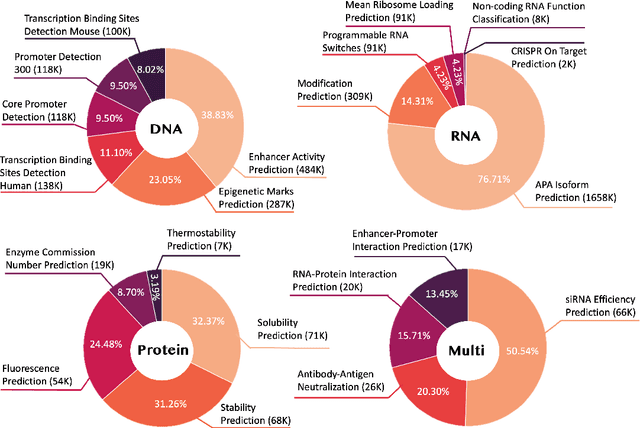
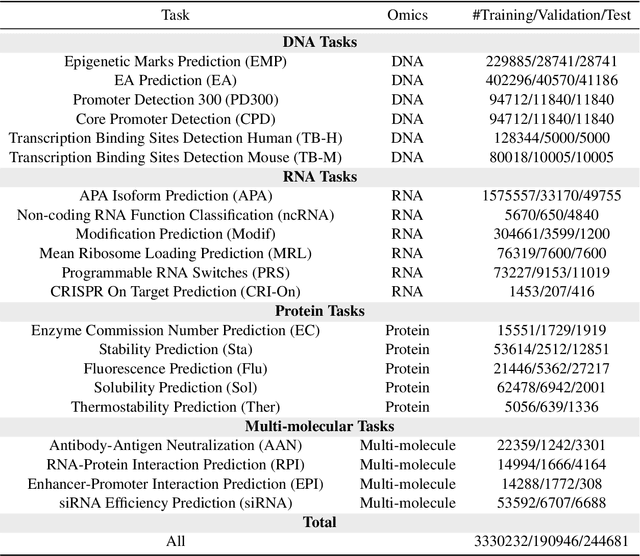
Large language models have already demonstrated their formidable capabilities in general domains, ushering in a revolutionary transformation. However, exploring and exploiting the extensive knowledge of these models to comprehend multi-omics biology remains underexplored. To fill this research gap, we first introduce Biology-Instructions, the first large-scale multi-omics biological sequences-related instruction-tuning dataset including DNA, RNA, proteins, and multi-molecules, designed to bridge the gap between large language models (LLMs) and complex biological sequences-related tasks. This dataset can enhance the versatility of LLMs by integrating diverse biological sequenced-based prediction tasks with advanced reasoning capabilities, while maintaining conversational fluency. Additionally, we reveal significant performance limitations in even state-of-the-art LLMs on biological sequence-related multi-omics tasks without specialized pre-training and instruction-tuning. We further develop a strong baseline called ChatMultiOmics with a novel three-stage training pipeline, demonstrating the powerful ability to understand biology by using Biology-Instructions. Biology-Instructions and ChatMultiOmics are publicly available and crucial resources for enabling more effective integration of LLMs with multi-omics sequence analysis.
TOMG-Bench: Evaluating LLMs on Text-based Open Molecule Generation
Dec 19, 2024



In this paper, we propose Text-based Open Molecule Generation Benchmark (TOMG-Bench), the first benchmark to evaluate the open-domain molecule generation capability of LLMs. TOMG-Bench encompasses a dataset of three major tasks: molecule editing (MolEdit), molecule optimization (MolOpt), and customized molecule generation (MolCustom). Each task further contains three subtasks, with each subtask comprising 5,000 test samples. Given the inherent complexity of open molecule generation, we have also developed an automated evaluation system that helps measure both the quality and the accuracy of the generated molecules. Our comprehensive benchmarking of 25 LLMs reveals the current limitations and potential areas for improvement in text-guided molecule discovery. Furthermore, with the assistance of OpenMolIns, a specialized instruction tuning dataset proposed for solving challenges raised by TOMG-Bench, Llama3.1-8B could outperform all the open-source general LLMs, even surpassing GPT-3.5-turbo by 46.5\% on TOMG-Bench. Our codes and datasets are available through https://github.com/phenixace/TOMG-Bench.