 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolyReal: A Benchmark for Real-World Polymer Science Workflows
Apr 03, 2026Multimodal Large Language Models (MLLMs) excel in general domains but struggle with complex, real-world science. We posit that polymer science, an interdisciplinary field spanning chemistry, physics, biology, and engineering, is an ideal high-stakes testbed due to its diverse multimodal data. Yet, existing benchmarks related to polymer science largely overlook real-world workflows, limiting their practical utility and failing to systematically evaluate MLLMs across the full, practice-grounded lifecycle of experimentation. We introduce PolyReal, a novel multimodal benchmark grounded in real-world scientific practices to evaluate MLLMs on the full lifecycle of polymer experimentation. It covers five critical capabilities: (1) foundational knowledge application; (2) lab safety analysis; (3) experiment mechanism reasoning; (4) raw data extraction; and (5) performance & application exploration. Our evaluation of leading MLLMs on PolyReal reveals a capability imbalance. While models perform well on knowledge-intensive reasoning (e.g., Experiment Mechanism Reasoning), they drop sharply on practice-based tasks (e.g., Lab Safety Analysis and Raw Data Extraction). This exposes a severe gap between abstract scientific knowledge and its practical, context-dependent application, showing that these real-world tasks remain challenging for MLLMs. Thus, PolyReal helps address this evaluation gap and provides a practical benchmark for assessing AI systems in real-world scientific workflows.
From 50% to Mastery in 3 Days: A Low-Resource SOP for Localizing Graduate-Level AI Tutors via Shadow-RAG
Mar 21, 2026Deploying high-fidelity AI tutors in schools is often blocked by the Resource Curse -- the need for expensive cloud GPUs and massive data engineering. In this practitioner report, we present a replicable Standard Operating Procedure that breaks this barrier. Using a Vision-Language Model data cleaning strategy and a novel Shadow-RAG architecture, we localized a graduate-level Applied Mathematics tutor using only 3 person-days of non-expert labor and open-weights 32B models deployable on a single consumer-grade GPU. Our pilot study on a full graduate-level final exam reveals a striking emergence phenomenon: while both zero-shot baselines and standard retrieval stagnate around 50-60% accuracy across model generations, the Shadow Agent, which provides structured reasoning guidance, triggers a massive capability surge in newer 32B models, boosting performance from 74% (Naive RAG) to mastery level (90%). In contrast, older models see only modest gains (~10%). This suggests that such guidance is the key to unlocking the latent power of modern small language models. This work offers a cost-effective, scientifically grounded blueprint for ubiquitous AI education.
MOOSE-Star: Unlocking Tractable Training for Scientific Discovery by Breaking the Complexity Barrier
Mar 04, 2026While large language models (LLMs) show promise in scientific discovery, existing research focuses on inference or feedback-driven training, leaving the direct modeling of the generative reasoning process, $P(\text{hypothesis}|\text{background})$ ($P(h|b)$), unexplored. We demonstrate that directly training $P(h|b)$ is mathematically intractable due to the combinatorial complexity ($O(N^k)$) inherent in retrieving and composing inspirations from a vast knowledge base. To break this barrier, we introduce MOOSE-Star, a unified framework enabling tractable training and scalable inference. In the best case, MOOSE-Star reduces complexity from exponential to logarithmic ($O(\log N)$) by (1) training on decomposed subtasks derived from the probabilistic equation of discovery, (2) employing motivation-guided hierarchical search to enable logarithmic retrieval and prune irrelevant subspaces, and (3) utilizing bounded composition for robustness against retrieval noise. To facilitate this, we release TOMATO-Star, a dataset of 108,717 decomposed papers (38,400 GPU hours) for training. Furthermore, we show that while brute-force sampling hits a ''complexity wall,'' MOOSE-Star exhibits continuous test-time scaling.
A unified foundational framework for knowledge injection and evaluation of Large Language Models in Combustion Science
Feb 27, 2026To advance foundation Large Language Models (LLMs) for combustion science, this study presents the first end-to-end framework for developing domain-specialized models for the combustion community. The framework comprises an AI-ready multimodal knowledge base at the 3.5 billion-token scale, extracted from over 200,000 peer-reviewed articles, 8,000 theses and dissertations, and approximately 400,000 lines of combustion CFD code; a rigorous and largely automated evaluation benchmark (CombustionQA, 436 questions across eight subfields); and a three-stage knowledge-injection pathway that progresses from lightweight retrieval-augmented generation (RAG) to knowledge-graph-enhanced retrieval and continued pretraining. We first quantitatively validate Stage 1 (naive RAG) and find a hard ceiling: standard RAG accuracy peaks at 60%, far surpassing zero-shot performance (23%) yet well below the theoretical upper bound (87%). We further demonstrate that this stage's performance is severely constrained by context contamination. Consequently, building a domain foundation model requires structured knowledge graphs and continued pretraining (Stages 2 and 3).
Accelerating RLHF Training with Reward Variance Increase
May 29, 2025
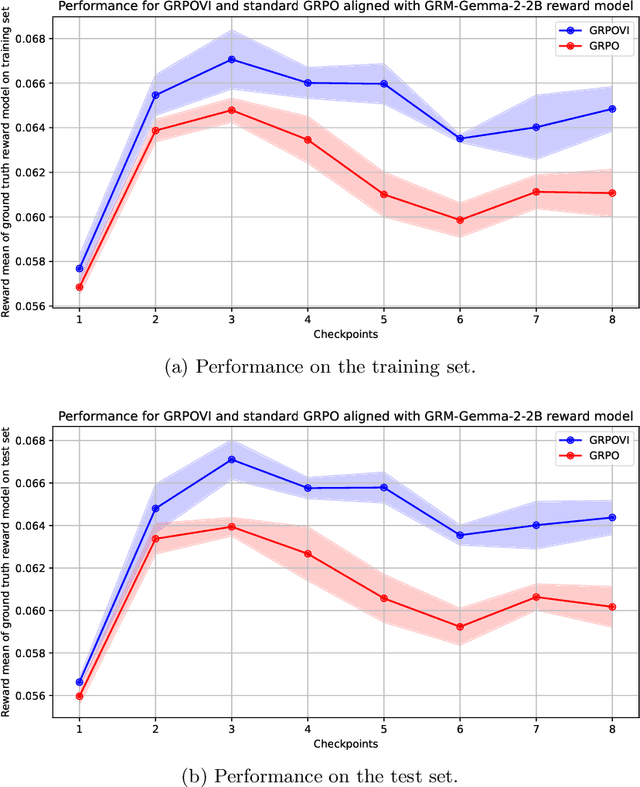

Reinforcement learning from human feedback (RLHF) is an essential technique for ensuring that large language models (LLMs) are aligned with human values and preferences during the post-training phase. As an effective RLHF approach, group relative policy optimization (GRPO) has demonstrated success in many LLM-based applications. However, efficient GRPO-based RLHF training remains a challenge. Recent studies reveal that a higher reward variance of the initial policy model leads to faster RLHF training. Inspired by this finding, we propose a practical reward adjustment model to accelerate RLHF training by provably increasing the reward variance and preserving the relative preferences and reward expectation. Our reward adjustment method inherently poses a nonconvex optimization problem, which is NP-hard to solve in general. To overcome the computational challenges, we design a novel $O(n \log n)$ algorithm to find a global solution of the nonconvex reward adjustment model by explicitly characterizing the extreme points of the feasible set. As an important application, we naturally integrate this reward adjustment model into the GRPO algorithm, leading to a more efficient GRPO with reward variance increase (GRPOVI) algorithm for RLHF training. As an interesting byproduct, we provide an indirect explanation for the empirical effectiveness of GRPO with rule-based reward for RLHF training, as demonstrated in DeepSeek-R1. Experiment results demonstrate that the GRPOVI algorithm can significantly improve the RLHF training efficiency compared to the original GRPO algorithm.
MOOSE-Chem2: Exploring LLM Limits in Fine-Grained Scientific Hypothesis Discovery via Hierarchical Search
May 25, 2025



Large language models (LLMs) have shown promise in automating scientific hypothesis generation, yet existing approaches primarily yield coarse-grained hypotheses lacking critical methodological and experimental details. We introduce and formally define the novel task of fine-grained scientific hypothesis discovery, which entails generating detailed, experimentally actionable hypotheses from coarse initial research directions. We frame this as a combinatorial optimization problem and investigate the upper limits of LLMs' capacity to solve it when maximally leveraged. Specifically, we explore four foundational questions: (1) how to best harness an LLM's internal heuristics to formulate the fine-grained hypothesis it itself would judge as the most promising among all the possible hypotheses it might generate, based on its own internal scoring-thus defining a latent reward landscape over the hypothesis space; (2) whether such LLM-judged better hypotheses exhibit stronger alignment with ground-truth hypotheses; (3) whether shaping the reward landscape using an ensemble of diverse LLMs of similar capacity yields better outcomes than defining it with repeated instances of the strongest LLM among them; and (4) whether an ensemble of identical LLMs provides a more reliable reward landscape than a single LLM. To address these questions, we propose a hierarchical search method that incrementally proposes and integrates details into the hypothesis, progressing from general concepts to specific experimental configurations. We show that this hierarchical process smooths the reward landscape and enables more effective optimization. Empirical evaluations on a new benchmark of expert-annotated fine-grained hypotheses from recent chemistry literature show that our method consistently outperforms strong baselines.
MOOSE-Chem3: Toward Experiment-Guided Hypothesis Ranking via Simulated Experimental Feedback
May 23, 2025



Hypothesis ranking is a crucial component of automated scientific discovery, particularly in natural sciences where wet-lab experiments are costly and throughput-limited. Existing approaches focus on pre-experiment ranking, relying solely on large language model's internal reasoning without incorporating empirical outcomes from experiments. We introduce the task of experiment-guided ranking, which aims to prioritize candidate hypotheses based on the results of previously tested ones. However, developing such strategies is challenging due to the impracticality of repeatedly conducting real experiments in natural science domains. To address this, we propose a simulator grounded in three domain-informed assumptions, modeling hypothesis performance as a function of similarity to a known ground truth hypothesis, perturbed by noise. We curate a dataset of 124 chemistry hypotheses with experimentally reported outcomes to validate the simulator. Building on this simulator, we develop a pseudo experiment-guided ranking method that clusters hypotheses by shared functional characteristics and prioritizes candidates based on insights derived from simulated experimental feedback. Experiments show that our method outperforms pre-experiment baselines and strong ablations.
ResearchBench: Benchmarking LLMs in Scientific Discovery via Inspiration-Based Task Decomposition
Mar 27, 2025



Large language models (LLMs) have demonstrated potential in assisting scientific research, yet their ability to discover high-quality research hypotheses remains unexamined due to the lack of a dedicated benchmark. To address this gap, we introduce the first large-scale benchmark for evaluating LLMs with a near-sufficient set of sub-tasks of scientific discovery: inspiration retrieval, hypothesis composition, and hypothesis ranking. We develop an automated framework that extracts critical components - research questions, background surveys, inspirations, and hypotheses - from scientific papers across 12 disciplines, with expert validation confirming its accuracy. To prevent data contamination, we focus exclusively on papers published in 2024, ensuring minimal overlap with LLM pretraining data. Our evaluation reveals that LLMs perform well in retrieving inspirations, an out-of-distribution task, suggesting their ability to surface novel knowledge associations. This positions LLMs as "research hypothesis mines", capable of facilitating automated scientific discovery by generating innovative hypotheses at scale with minimal human intervention.
LLM4SR: A Survey on Large Language Models for Scientific Research
Jan 08, 2025



In recent years, the rapid advancement of Large Language Models (LLMs) has transformed the landscape of scientific research, offering unprecedented support across various stages of the research cycle. This paper presents the first systematic survey dedicated to exploring how LLMs are revolutionizing the scientific research process. We analyze the unique roles LLMs play across four critical stages of research: hypothesis discovery, experiment planning and implementation, scientific writing, and peer reviewing. Our review comprehensively showcases the task-specific methodologies and evaluation benchmarks. By identifying current challenges and proposing future research directions, this survey not only highlights the transformative potential of LLMs, but also aims to inspire and guide researchers and practitioners in leveraging LLMs to advance scientific inquiry. Resources are available at the following repository: https://github.com/du-nlp-lab/LLM4SR
Critic-V: VLM Critics Help Catch VLM Errors in Multimodal Reasoning
Dec 02, 2024



Vision-language models (VLMs) have shown remarkable advancements in multimodal reasoning tasks. However, they still often generate inaccurate or irrelevant responses due to issues like hallucinated image understandings or unrefined reasoning paths. To address these challenges, we introduce Critic-V, a novel framework inspired by the Actor-Critic paradigm to boost the reasoning capability of VLMs. This framework decouples the reasoning process and critic process by integrating two independent components: the Reasoner, which generates reasoning paths based on visual and textual inputs, and the Critic, which provides constructive critique to refine these paths. In this approach, the Reasoner generates reasoning responses according to text prompts, which can evolve iteratively as a policy based on feedback from the Critic. This interaction process was theoretically driven by a reinforcement learning framework where the Critic offers natural language critiques instead of scalar rewards, enabling more nuanced feedback to boost the Reasoner's capability on complex reasoning tasks. The Critic model is trained using Direct Preference Optimization (DPO), leveraging a preference dataset of critiques ranked by Rule-based Reward~(RBR) to enhance its critic capabilities. Evaluation results show that the Critic-V framework significantly outperforms existing methods, including GPT-4V, on 5 out of 8 benchmarks, especially regarding reasoning accuracy and efficiency. Combining a dynamic text-based policy for the Reasoner and constructive feedback from the preference-optimized Critic enables a more reliable and context-sensitive multimodal reasoning process. Our approach provides a promising solution to enhance the reliability of VLMs, improving their performance in real-world reasoning-heavy multimodal applications such as autonomous driving and embodied intelligence.