 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoisyRollout: Reinforcing Visual Reasoning with Data Augmentation
Apr 17, 2025Recent advances in reinforcement learning (RL) have strengthened the reasoning capabilities of vision-language models (VLMs). However, enhancing policy exploration to more effectively scale test-time compute remains underexplored in VLMs. In addition, VLMs continue to struggle with imperfect visual perception, which in turn affects the subsequent reasoning process. To this end, we propose NoisyRollout, a simple yet effective RL approach that mixes trajectories from both clean and moderately distorted images to introduce targeted diversity in visual perception and the resulting reasoning patterns. Without additional training cost, NoisyRollout enhances the exploration capabilities of VLMs by incorporating a vision-oriented inductive bias. Furthermore, NoisyRollout employs a noise annealing schedule that gradually reduces distortion strength over training, ensuring benefit from noisy signals early while maintaining training stability and scalability in later stages. With just 2.1K training samples, NoisyRollout achieves state-of-the-art performance among open-source RL-tuned models on 5 out-of-domain benchmarks spanning both reasoning and perception tasks, while preserving comparable or even better in-domain performance.
ResearchBench: Benchmarking LLMs in Scientific Discovery via Inspiration-Based Task Decomposition
Mar 27, 2025



Large language models (LLMs) have demonstrated potential in assisting scientific research, yet their ability to discover high-quality research hypotheses remains unexamined due to the lack of a dedicated benchmark. To address this gap, we introduce the first large-scale benchmark for evaluating LLMs with a near-sufficient set of sub-tasks of scientific discovery: inspiration retrieval, hypothesis composition, and hypothesis ranking. We develop an automated framework that extracts critical components - research questions, background surveys, inspirations, and hypotheses - from scientific papers across 12 disciplines, with expert validation confirming its accuracy. To prevent data contamination, we focus exclusively on papers published in 2024, ensuring minimal overlap with LLM pretraining data. Our evaluation reveals that LLMs perform well in retrieving inspirations, an out-of-distribution task, suggesting their ability to surface novel knowledge associations. This positions LLMs as "research hypothesis mines", capable of facilitating automated scientific discovery by generating innovative hypotheses at scale with minimal human intervention.
Long-Context Inference with Retrieval-Augmented Speculative Decoding
Feb 27, 2025The emergence of long-context large language models (LLMs) offers a promising alternative to traditional retrieval-augmented generation (RAG) for processing extensive documents. However, the computational overhead of long-context inference, particularly in managing key-value (KV) caches, presents significant efficiency challenges. While Speculative Decoding (SD) traditionally accelerates inference using smaller draft models, its effectiveness diminishes substantially in long-context scenarios due to memory-bound KV cache operations. We present Retrieval-Augmented Speculative Decoding (RAPID), which leverages RAG for both accelerating and enhancing generation quality in long-context inference. RAPID introduces the RAG drafter-a draft LLM operating on shortened retrieval contexts-to speculate on the generation of long-context target LLMs. Our approach enables a new paradigm where same-scale or even larger LLMs can serve as RAG drafters while maintaining computational efficiency. To fully leverage the potentially superior capabilities from stronger RAG drafters, we develop an inference-time knowledge transfer dynamic that enriches the target distribution by RAG. Extensive experiments on the LLaMA-3.1 and Qwen2.5 backbones demonstrate that RAPID effectively integrates the strengths of both approaches, achieving significant performance improvements (e.g., from 39.33 to 42.83 on InfiniteBench for LLaMA-3.1-8B) with more than 2x speedups. Our analyses reveal that RAPID achieves robust acceleration beyond 32K context length and demonstrates superior generation quality in real-world applications.
Boosting LLM via Learning from Data Iteratively and Selectively
Dec 23, 2024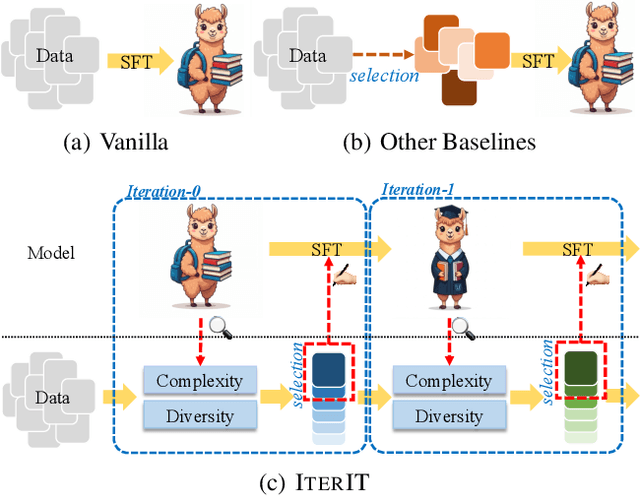
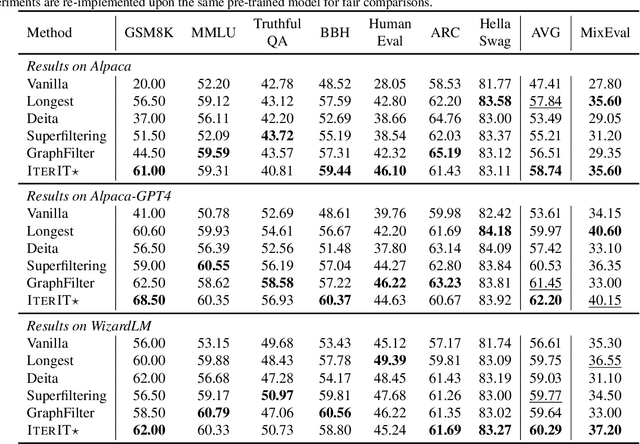
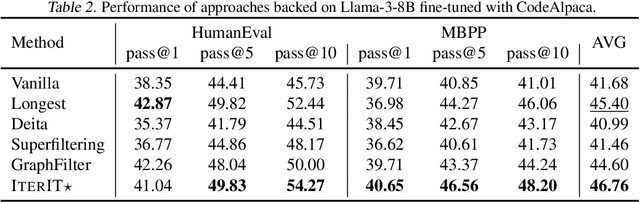
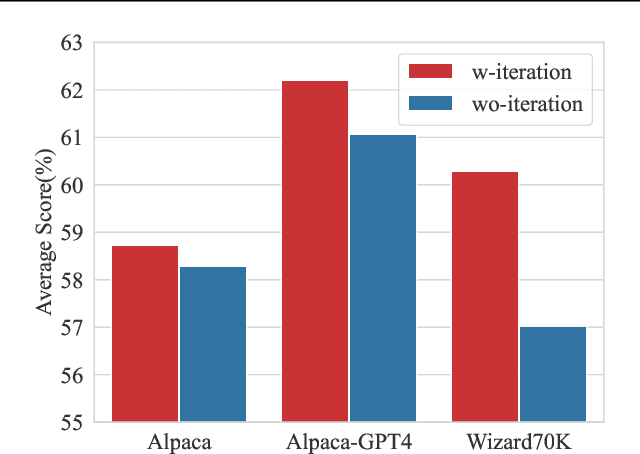
Datasets nowadays are generally constructed from multiple sources and using different synthetic techniques, making data de-noising and de-duplication crucial before being used for post-training. In this work, we propose to perform instruction tuning by iterative data selection (\ApproachName{}). We measure the quality of a sample from complexity and diversity simultaneously. Instead of calculating the complexity score once for all before fine-tuning, we highlight the importance of updating this model-specific score during fine-tuning to accurately accommodate the dynamic changes of the model. On the other hand, the diversity score is defined on top of the samples' responses under the consideration of their informativeness. IterIT integrates the strengths of both worlds by iteratively updating the complexity score for the top-ranked samples and greedily selecting the ones with the highest complexity-diversity score. Experiments on multiple instruction-tuning data demonstrate consistent improvements of IterIT over strong baselines. Moreover, our approach also generalizes well to domain-specific scenarios and different backbone models. All resources will be available at https://github.com/JiaQiSJTU/IterIT.
MixEval-X: Any-to-Any Evaluations from Real-World Data Mixtures
Oct 17, 2024



Perceiving and generating diverse modalities are crucial for AI models to effectively learn from and engage with real-world signals, necessitating reliable evaluations for their development. We identify two major issues in current evaluations: (1) inconsistent standards, shaped by different communities with varying protocols and maturity levels; and (2) significant query, grading, and generalization biases. To address these, we introduce MixEval-X, the first any-to-any real-world benchmark designed to optimize and standardize evaluations across input and output modalities. We propose multi-modal benchmark mixture and adaptation-rectification pipelines to reconstruct real-world task distributions, ensuring evaluations generalize effectively to real-world use cases. Extensive meta-evaluations show our approach effectively aligns benchmark samples with real-world task distributions and the model rankings correlate strongly with that of crowd-sourced real-world evaluations (up to 0.98). We provide comprehensive leaderboards to rerank existing models and organizations and offer insights to enhance understanding of multi-modal evaluations and inform future research.
MixEval: Deriving Wisdom of the Crowd from LLM Benchmark Mixtures
Jun 03, 2024



Evaluating large language models (LLMs) is challenging. Traditional ground-truth-based benchmarks fail to capture the comprehensiveness and nuance of real-world queries, while LLM-as-judge benchmarks suffer from grading biases and limited query quantity. Both of them may also become contaminated over time. User-facing evaluation, such as Chatbot Arena, provides reliable signals but is costly and slow. In this work, we propose MixEval, a new paradigm for establishing efficient, gold-standard LLM evaluation by strategically mixing off-the-shelf benchmarks. It bridges (1) comprehensive and well-distributed real-world user queries and (2) efficient and fairly-graded ground-truth-based benchmarks, by matching queries mined from the web with similar queries from existing benchmarks. Based on MixEval, we further build MixEval-Hard, which offers more room for model improvement. Our benchmarks' advantages lie in (1) a 0.96 model ranking correlation with Chatbot Arena arising from the highly impartial query distribution and grading mechanism, (2) fast, cheap, and reproducible execution (6% of the time and cost of MMLU), and (3) dynamic evaluation enabled by the rapid and stable data update pipeline. We provide extensive meta-evaluation and analysis for our and existing LLM benchmarks to deepen the community's understanding of LLM evaluation and guide future research directions.
OpenMoE: An Early Effort on Open Mixture-of-Experts Language Models
Jan 29, 2024



To help the open-source community have a better understanding of Mixture-of-Experts (MoE) based large language models (LLMs), we train and release OpenMoE, a series of fully open-sourced and reproducible decoder-only MoE LLMs, ranging from 650M to 34B parameters and trained on up to over 1T tokens. Our investigation confirms that MoE-based LLMs can offer a more favorable cost-effectiveness trade-off than dense LLMs, highlighting the potential effectiveness for future LLM development. One more important contribution of this study is an in-depth analysis of the routing mechanisms within our OpenMoE models, leading to three significant findings: Context-Independent Specialization, Early Routing Learning, and Drop-towards-the-End. We discovered that routing decisions in MoE models are predominantly based on token IDs, with minimal context relevance. The token-to-expert assignments are determined early in the pre-training phase and remain largely unchanged. This imperfect routing can result in performance degradation, particularly in sequential tasks like multi-turn conversations, where tokens appearing later in a sequence are more likely to be dropped. Finally, we rethink our design based on the above-mentioned observations and analysis. To facilitate future MoE LLM development, we propose potential strategies for mitigating the issues we found and further improving off-the-shelf MoE LLM designs.
A Survey on Semantic Processing Techniques
Oct 22, 2023Semantic processing is a fundamental research domain in computational linguistics. In the era of powerful pre-trained language models and large language models, the advancement of research in this domain appears to be decelerating. However, the study of semantics is multi-dimensional in linguistics. The research depth and breadth of computational semantic processing can be largely improved with new technologies. In this survey, we analyzed five semantic processing tasks, e.g., word sense disambiguation, anaphora resolution, named entity recognition, concept extraction, and subjectivity detection. We study relevant theoretical research in these fields, advanced methods, and downstream applications. We connect the surveyed tasks with downstream applications because this may inspire future scholars to fuse these low-level semantic processing tasks with high-level natural language processing tasks. The review of theoretical research may also inspire new tasks and technologies in the semantic processing domain. Finally, we compare the different semantic processing techniques and summarize their technical trends, application trends, and future directions.
Finding the Pillars of Strength for Multi-Head Attention
May 22, 2023



Recent studies have revealed some issues of Multi-Head Attention (MHA), e.g., redundancy and over-parameterization. Specifically, the heads of MHA were originally designed to attend to information from different representation subspaces, whereas prior studies found that some attention heads likely learn similar features and can be pruned without harming performance. Inspired by the minimum-redundancy feature selection, we assume that focusing on the most representative and distinctive features with minimum resources can mitigate the above issues and lead to more effective and efficient MHAs. In particular, we propose Grouped Head Attention, trained with a self-supervised group constraint that group attention heads, where each group focuses on an essential but distinctive feature subset. We additionally propose a Voting-to-Stay procedure to remove redundant heads, thus achieving a transformer with lighter weights. Moreover, our method achieves significant performance gains on three well-established tasks while considerably compressing parameters.
Logical Reasoning over Natural Language as Knowledge Representation: A Survey
Mar 21, 2023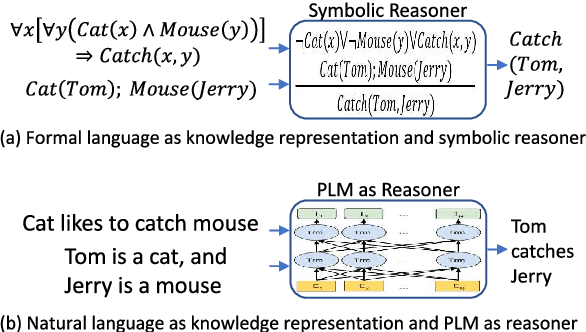
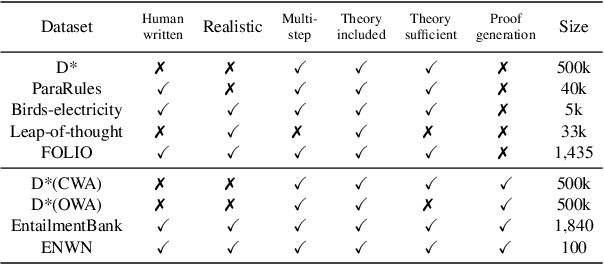
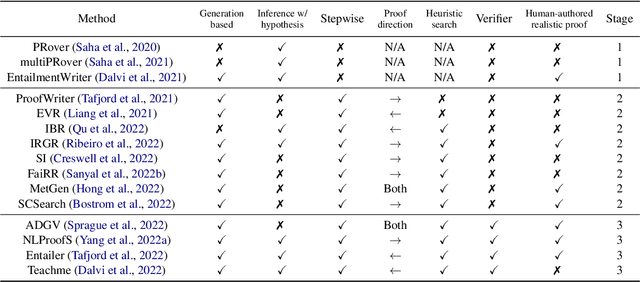
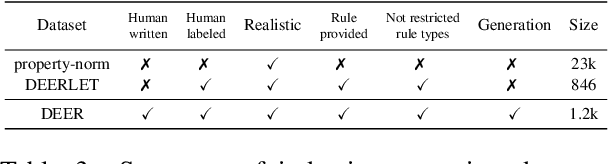
Logical reasoning is central to human cognition and intelligence. Past research of logical reasoning within AI uses formal language as knowledge representation~(and symbolic reasoners). However, reasoning with formal language has proved challenging~(e.g., brittleness and knowledge-acquisition bottleneck). This paper provides a comprehensive overview on a new paradigm of logical reasoning, which uses natural language as knowledge representation~(and pretrained language models as reasoners), including philosophical definition and categorization of logical reasoning, advantages of the new paradigm, benchmarks and methods, challenges of the new paradigm, desirable tasks & methods in the future, and relation to related NLP fields. This new paradigm is promising since it not only alleviates many challenges of formal representation but also has advantages over end-to-end neural methods.