 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNMRTrans: Structure Elucidation from Experimental NMR Spectra via Set Transformers
Feb 10, 2026Nuclear Magnetic Resonance (NMR) spectroscopy is fundamental for molecular structure elucidation, yet interpreting spectra at scale remains time-consuming and highly expertise-dependent. While recent spectrum-as-language modeling and retrieval-based methods have shown promise, they rely heavily on large corpora of computed spectra and exhibit notable performance drops when applied to experimental measurements. To address these issues, we build NMRSpec, a large-scale corpus of experimental $^1$H and $^{13}$C spectra mined from chemical literature, and propose NMRTrans, which models spectra as unordered peak sets and aligns the model's inductive bias with the physical nature of NMR. To our best knowledge, NMRTrans is the first NMR Transformer trained solely on large-scale experimental spectra and achieves state-of-the-art performance on experimental benchmarks, improving Top-10 Accuracy over the strongest baseline by +17.82 points (61.15% vs. 43.33%), and underscoring the importance of experimental data and structure-aware architectures for reliable NMR structure elucidation.
MolAct: An Agentic RL Framework for Molecular Editing and Property Optimization
Dec 24, 2025Molecular editing and optimization are multi-step problems that require iteratively improving properties while keeping molecules chemically valid and structurally similar. We frame both tasks as sequential, tool-guided decisions and introduce MolAct, an agentic reinforcement learning framework that employs a two-stage training paradigm: first building editing capability, then optimizing properties while reusing the learned editing behaviors. To the best of our knowledge, this is the first work to formalize molecular design as an Agentic Reinforcement Learning problem, where an LLM agent learns to interleave reasoning, tool-use, and molecular optimization. The framework enables agents to interact in multiple turns, invoking chemical tools for validity checking, property assessment, and similarity control, and leverages their feedback to refine subsequent edits. We instantiate the MolAct framework to train two model families: MolEditAgent for molecular editing tasks and MolOptAgent for molecular optimization tasks. In molecular editing, MolEditAgent-7B delivers 100, 95, and 98 valid add, delete, and substitute edits, outperforming strong closed "thinking" baselines such as DeepSeek-R1; MolEditAgent-3B approaches the performance of much larger open "thinking" models like Qwen3-32B-think. In molecular optimization, MolOptAgent-7B (trained on MolEditAgent-7B) surpasses the best closed "thinking" baseline (e.g., Claude 3.7) on LogP and remains competitive on solubility, while maintaining balanced performance across other objectives. These results highlight that treating molecular design as a multi-step, tool-augmented process is key to reliable and interpretable improvements.
Conformal Online Learning of Deep Koopman Linear Embeddings
Nov 16, 2025We introduce Conformal Online Learning of Koopman embeddings (COLoKe), a novel framework for adaptively updating Koopman-invariant representations of nonlinear dynamical systems from streaming data. Our modeling approach combines deep feature learning with multistep prediction consistency in the lifted space, where the dynamics evolve linearly. To prevent overfitting, COLoKe employs a conformal-style mechanism that shifts the focus from evaluating the conformity of new states to assessing the consistency of the current Koopman model. Updates are triggered only when the current model's prediction error exceeds a dynamically calibrated threshold, allowing selective refinement of the Koopman operator and embedding. Empirical results on benchmark dynamical systems demonstrate the effectiveness of COLoKe in maintaining long-term predictive accuracy while significantly reducing unnecessary updates and avoiding overfitting.
ChemBOMAS: Accelerated BO in Chemistry with LLM-Enhanced Multi-Agent System
Sep 10, 2025The efficiency of Bayesian optimization (BO) in chemistry is often hindered by sparse experimental data and complex reaction mechanisms. To overcome these limitations, we introduce ChemBOMAS, a new framework named LLM-Enhanced Multi-Agent System for accelerating BO in chemistry. ChemBOMAS's optimization process is enhanced by LLMs and synergistically employs two strategies: knowledge-driven coarse-grained optimization and data-driven fine-grained optimization. First, in the knowledge-driven coarse-grained optimization stage, LLMs intelligently decompose the vast search space by reasoning over existing chemical knowledge to identify promising candidate regions. Subsequently, in the data-driven fine-grained optimization stage, LLMs enhance the BO process within these candidate regions by generating pseudo-data points, thereby improving data utilization efficiency and accelerating convergence. Benchmark evaluations** further confirm that ChemBOMAS significantly enhances optimization effectiveness and efficiency compared to various BO algorithms. Importantly, the practical utility of ChemBOMAS was validated through wet-lab experiments conducted under pharmaceutical industry protocols, targeting conditional optimization for a previously unreported and challenging chemical reaction. In the wet experiment, ChemBOMAS achieved an optimal objective value of 96%. This was substantially higher than the 15% achieved by domain experts. This real-world success, together with strong performance on benchmark evaluations, highlights ChemBOMAS as a powerful tool to accelerate chemical discovery.
MOOSE-Chem2: Exploring LLM Limits in Fine-Grained Scientific Hypothesis Discovery via Hierarchical Search
May 25, 2025



Large language models (LLMs) have shown promise in automating scientific hypothesis generation, yet existing approaches primarily yield coarse-grained hypotheses lacking critical methodological and experimental details. We introduce and formally define the novel task of fine-grained scientific hypothesis discovery, which entails generating detailed, experimentally actionable hypotheses from coarse initial research directions. We frame this as a combinatorial optimization problem and investigate the upper limits of LLMs' capacity to solve it when maximally leveraged. Specifically, we explore four foundational questions: (1) how to best harness an LLM's internal heuristics to formulate the fine-grained hypothesis it itself would judge as the most promising among all the possible hypotheses it might generate, based on its own internal scoring-thus defining a latent reward landscape over the hypothesis space; (2) whether such LLM-judged better hypotheses exhibit stronger alignment with ground-truth hypotheses; (3) whether shaping the reward landscape using an ensemble of diverse LLMs of similar capacity yields better outcomes than defining it with repeated instances of the strongest LLM among them; and (4) whether an ensemble of identical LLMs provides a more reliable reward landscape than a single LLM. To address these questions, we propose a hierarchical search method that incrementally proposes and integrates details into the hypothesis, progressing from general concepts to specific experimental configurations. We show that this hierarchical process smooths the reward landscape and enables more effective optimization. Empirical evaluations on a new benchmark of expert-annotated fine-grained hypotheses from recent chemistry literature show that our method consistently outperforms strong baselines.
ResearchBench: Benchmarking LLMs in Scientific Discovery via Inspiration-Based Task Decomposition
Mar 27, 2025



Large language models (LLMs) have demonstrated potential in assisting scientific research, yet their ability to discover high-quality research hypotheses remains unexamined due to the lack of a dedicated benchmark. To address this gap, we introduce the first large-scale benchmark for evaluating LLMs with a near-sufficient set of sub-tasks of scientific discovery: inspiration retrieval, hypothesis composition, and hypothesis ranking. We develop an automated framework that extracts critical components - research questions, background surveys, inspirations, and hypotheses - from scientific papers across 12 disciplines, with expert validation confirming its accuracy. To prevent data contamination, we focus exclusively on papers published in 2024, ensuring minimal overlap with LLM pretraining data. Our evaluation reveals that LLMs perform well in retrieving inspirations, an out-of-distribution task, suggesting their ability to surface novel knowledge associations. This positions LLMs as "research hypothesis mines", capable of facilitating automated scientific discovery by generating innovative hypotheses at scale with minimal human intervention.
MOOSE-Chem: Large Language Models for Rediscovering Unseen Chemistry Scientific Hypotheses
Oct 09, 2024Scientific discovery contributes largely to human society's prosperity, and recent progress shows that LLMs could potentially catalyze this process. However, it is still unclear whether LLMs can discover novel and valid hypotheses in chemistry. In this work, we investigate this central research question: Can LLMs automatically discover novel and valid chemistry research hypotheses given only a chemistry research background (consisting of a research question and/or a background survey), without limitation on the domain of the research question? After extensive discussions with chemistry experts, we propose an assumption that a majority of chemistry hypotheses can be resulted from a research background and several inspirations. With this key insight, we break the central question into three smaller fundamental questions. In brief, they are: (1) given a background question, whether LLMs can retrieve good inspirations; (2) with background and inspirations, whether LLMs can lead to hypothesis; and (3) whether LLMs can identify good hypotheses to rank them higher. To investigate these questions, we construct a benchmark consisting of 51 chemistry papers published in Nature, Science, or a similar level in 2024 (all papers are only available online since 2024). Every paper is divided by chemistry PhD students into three components: background, inspirations, and hypothesis. The goal is to rediscover the hypothesis, given only the background and a large randomly selected chemistry literature corpus consisting the ground truth inspiration papers, with LLMs trained with data up to 2023. We also develop an LLM-based multi-agent framework that leverages the assumption, consisting of three stages reflecting the three smaller questions. The proposed method can rediscover many hypotheses with very high similarity with the ground truth ones, covering the main innovations.
User Personalized Satisfaction Prediction via Multiple Instance Deep Learning
Nov 24, 2016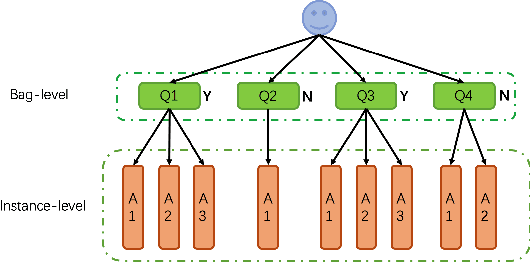



Community based question answering services have arisen as a popular knowledge sharing pattern for netizens. With abundant interactions among users, individuals are capable of obtaining satisfactory information. However, it is not effective for users to attain answers within minutes. Users have to check the progress over time until the satisfying answers submitted. We address this problem as a user personalized satisfaction prediction task. Existing methods usually exploit manual feature selection. It is not desirable as it requires careful design and is labor intensive. In this paper, we settle this issue by developing a new multiple instance deep learning framework. Specifically, in our settings, each question follows a weakly supervised learning multiple instance learning assumption, where its obtained answers can be regarded as instance sets and we define the question resolved with at least one satisfactory answer. We thus design an efficient framework exploiting multiple instance learning property with deep learning to model the question answer pairs. Extensive experiments on large scale datasets from Stack Exchange demonstrate the feasibility of our proposed framework in predicting askers personalized satisfaction. Our framework can be extended to numerous applications such as UI satisfaction Prediction, multi armed bandit problem, expert finding and so on.