 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMSMix:An Interpolation-Based Text Data Augmentation Method Manifold Swap Mixup
May 31, 2023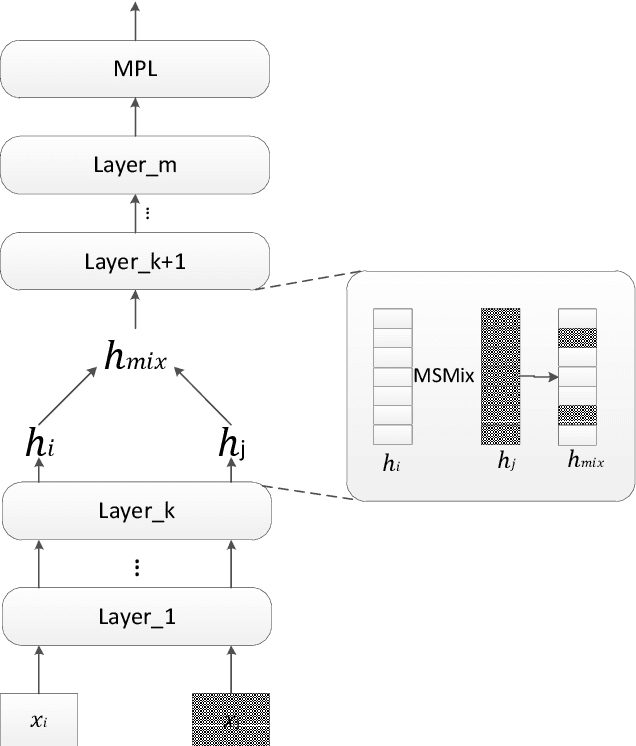
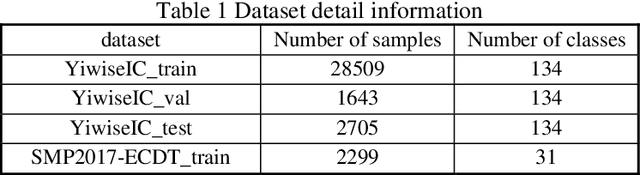
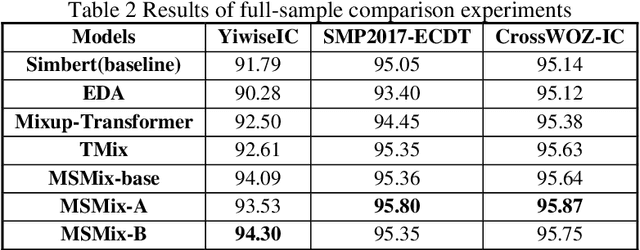
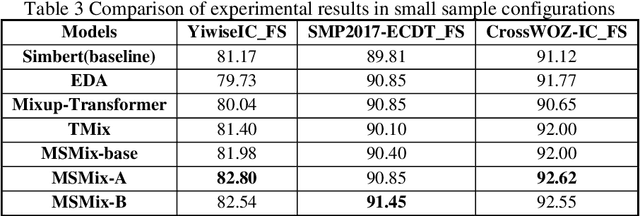
To solve the problem of poor performance of deep neural network models due to insufficient data, a simple yet effective interpolation-based data augmentation method is proposed: MSMix (Manifold Swap Mixup). This method feeds two different samples to the same deep neural network model, and then randomly select a specific layer and partially replace hidden features at that layer of one of the samples by the counterpart of the other. The mixed hidden features are fed to the model and go through the rest of the network. Two different selection strategies are also proposed to obtain richer hidden representation. Experiments are conducted on three Chinese intention recognition datasets, and the results show that the MSMix method achieves better results than other methods in both full-sample and small-sample configurations.
Dialogue Act Recognition via CRF-Attentive Structured Network
Nov 15, 2017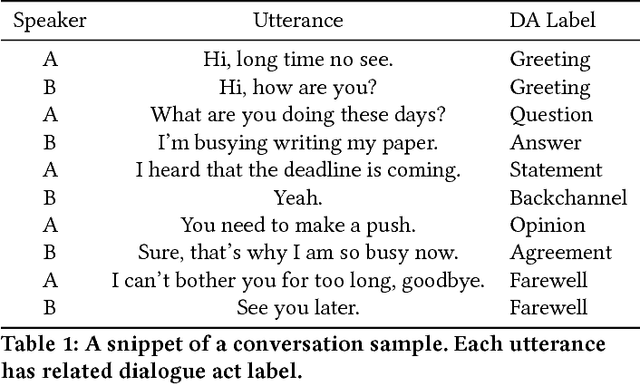

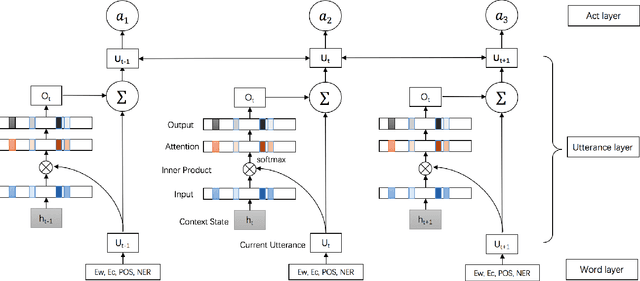

Dialogue Act Recognition (DAR) is a challenging problem in dialogue interpretation, which aims to attach semantic labels to utterances and characterize the speaker's intention. Currently, many existing approaches formulate the DAR problem ranging from multi-classification to structured prediction, which suffer from handcrafted feature extensions and attentive contextual structural dependencies. In this paper, we consider the problem of DAR from the viewpoint of extending richer Conditional Random Field (CRF) structural dependencies without abandoning end-to-end training. We incorporate hierarchical semantic inference with memory mechanism on the utterance modeling. We then extend structured attention network to the linear-chain conditional random field layer which takes into account both contextual utterances and corresponding dialogue acts. The extensive experiments on two major benchmark datasets Switchboard Dialogue Act (SWDA) and Meeting Recorder Dialogue Act (MRDA) datasets show that our method achieves better performance than other state-of-the-art solutions to the problem. It is a remarkable fact that our method is nearly close to the human annotator's performance on SWDA within 2% gap.
Smarnet: Teaching Machines to Read and Comprehend Like Human
Oct 08, 2017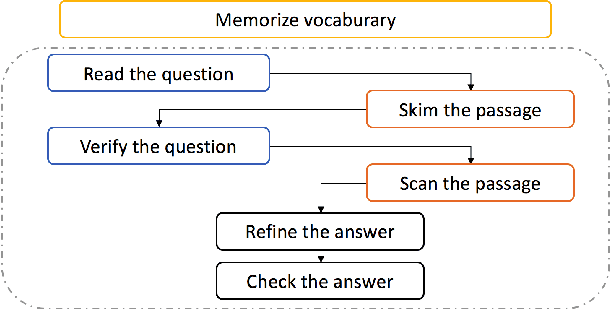
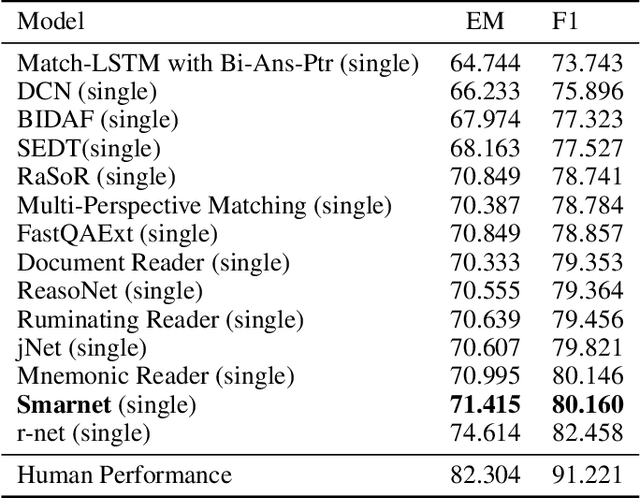
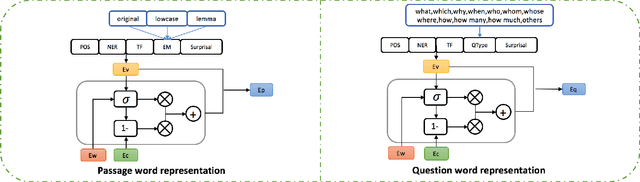
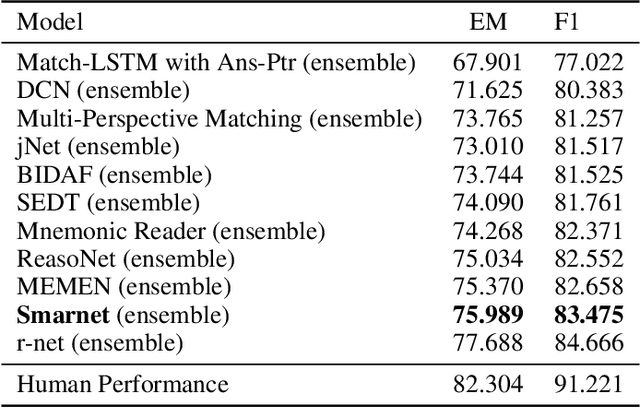
Machine Comprehension (MC) is a challenging task in Natural Language Processing field, which aims to guide the machine to comprehend a passage and answer the given question. Many existing approaches on MC task are suffering the inefficiency in some bottlenecks, such as insufficient lexical understanding, complex question-passage interaction, incorrect answer extraction and so on. In this paper, we address these problems from the viewpoint of how humans deal with reading tests in a scientific way. Specifically, we first propose a novel lexical gating mechanism to dynamically combine the words and characters representations. We then guide the machines to read in an interactive way with attention mechanism and memory network. Finally we add a checking layer to refine the answer for insurance. The extensive experiments on two popular datasets SQuAD and TriviaQA show that our method exceeds considerable performance than most state-of-the-art solutions at the time of submission.
Question Retrieval for Community-based Question Answering via Heterogeneous Network Integration Learning
Nov 24, 2016
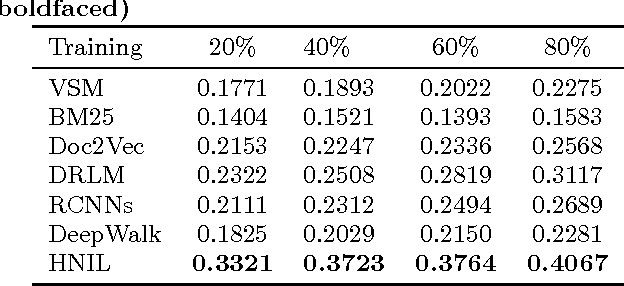
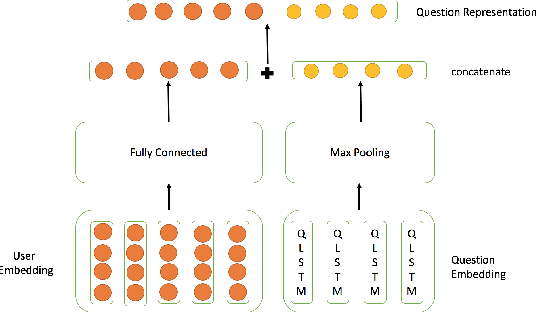
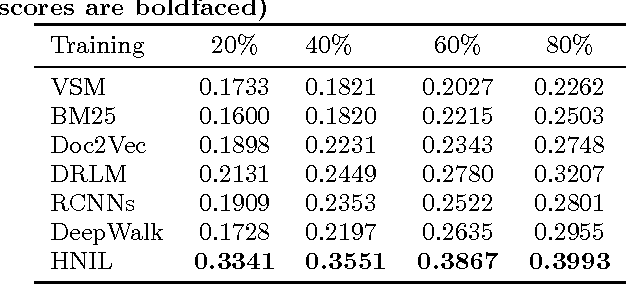
Community based question answering platforms have attracted substantial users to share knowledge and learn from each other. As the rapid enlargement of CQA platforms, quantities of overlapped questions emerge, which makes users confounded to select a proper reference. It is urgent for us to take effective automated algorithms to reuse historical questions with corresponding answers. In this paper we focus on the problem with question retrieval, which aims to match historical questions that are relevant or semantically equivalent to resolve one s query directly. The challenges in this task are the lexical gaps between questions for the word ambiguity and word mismatch problem. Furthermore, limited words in queried sentences cause sparsity of word features. To alleviate these challenges, we propose a novel framework named HNIL which encodes not only the question contents but also the askers social interactions to enhance the question embedding performance. More specifically, we apply random walk based learning method with recurrent neural network to match the similarities between askers question and historical questions proposed by other users. Extensive experiments on a large scale dataset from a real world CQA site show that employing the heterogeneous social network information outperforms the other state of the art solutions in this task.
User Personalized Satisfaction Prediction via Multiple Instance Deep Learning
Nov 24, 2016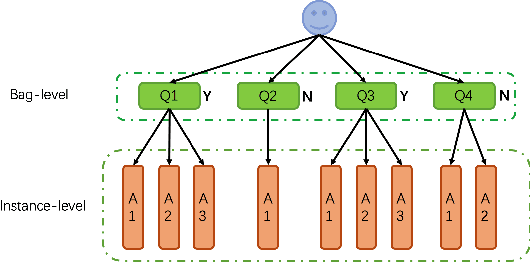



Community based question answering services have arisen as a popular knowledge sharing pattern for netizens. With abundant interactions among users, individuals are capable of obtaining satisfactory information. However, it is not effective for users to attain answers within minutes. Users have to check the progress over time until the satisfying answers submitted. We address this problem as a user personalized satisfaction prediction task. Existing methods usually exploit manual feature selection. It is not desirable as it requires careful design and is labor intensive. In this paper, we settle this issue by developing a new multiple instance deep learning framework. Specifically, in our settings, each question follows a weakly supervised learning multiple instance learning assumption, where its obtained answers can be regarded as instance sets and we define the question resolved with at least one satisfactory answer. We thus design an efficient framework exploiting multiple instance learning property with deep learning to model the question answer pairs. Extensive experiments on large scale datasets from Stack Exchange demonstrate the feasibility of our proposed framework in predicting askers personalized satisfaction. Our framework can be extended to numerous applications such as UI satisfaction Prediction, multi armed bandit problem, expert finding and so on.