 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnchor Forcing: Anchor Memory and Tri-Region RoPE for Interactive Streaming Video Diffusion
Mar 12, 2026Interactive long video generation requires prompt switching to introduce new subjects or events, while maintaining perceptual fidelity and coherent motion over extended horizons. Recent distilled streaming video diffusion models reuse a rolling KV cache for long-range generation, enabling prompt-switch interaction through re-cache at each switch. However, existing streaming methods still exhibit progressive quality degradation and weakened motion dynamics. We identify two failure modes specific to interactive streaming generation: (i) at each prompt switch, current cache maintenance cannot simultaneously retain KV-based semantic context and recent latent cues, resulting in weak boundary conditioning and reduced perceptual quality; and (ii) during distillation, unbounded time indexing induces a positional distribution shift from the pretrained backbone's bounded RoPE regime, weakening pretrained motion priors and long-horizon motion retention. To address these issues, we propose \textbf{Anchor Forcing}, a cache-centric framework with two designs. First, an anchor-guided re-cache mechanism stores KV states in anchor caches and warm-starts re-cache from these anchors at each prompt switch, reducing post-switch evidence loss and stabilizing perceptual quality. Second, a tri-region RoPE with region-specific reference origins, together with RoPE re-alignment distillation, reconciles unbounded streaming indices with the pretrained RoPE regime to better retain motion priors. Experiments on long videos show that our method improves perceptual quality and motion metrics over prior streaming baselines in interactive settings. Project page: https://github.com/vivoCameraResearch/Anchor-Forcing
HeteroCache: A Dynamic Retrieval Approach to Heterogeneous KV Cache Compression for Long-Context LLM Inference
Jan 20, 2026The linear memory growth of the KV cache poses a significant bottleneck for LLM inference in long-context tasks. Existing static compression methods often fail to preserve globally important information, principally because they overlook the attention drift phenomenon where token significance evolves dynamically. Although recent dynamic retrieval approaches attempt to address this issue, they typically suffer from coarse-grained caching strategies and incur high I/O overhead due to frequent data transfers. To overcome these limitations, we propose HeteroCache, a training-free dynamic compression framework. Our method is built on two key insights: attention heads exhibit diverse temporal heterogeneity, and there is significant spatial redundancy among heads within the same layer. Guided by these insights, HeteroCache categorizes heads based on stability and redundancy. Consequently, we apply a fine-grained weighting strategy that allocates larger cache budgets to heads with rapidly shifting attention to capture context changes, thereby addressing the inefficiency of coarse-grained strategies. Furthermore, we employ a hierarchical storage mechanism in which a subset of representative heads monitors attention shift, and trigger an asynchronous, on-demand retrieval of contexts from the CPU, effectively hiding I/O latency. Finally, experiments demonstrate that HeteroCache achieves state-of-the-art performance on multiple long-context benchmarks and accelerates decoding by up to $3\times$ compared to the original model in the 224K context. Our code will be open-source.
PhyRPR: Training-Free Physics-Constrained Video Generation
Jan 14, 2026Recent diffusion-based video generation models can synthesize visually plausible videos, yet they often struggle to satisfy physical constraints. A key reason is that most existing approaches remain single-stage: they entangle high-level physical understanding with low-level visual synthesis, making it hard to generate content that require explicit physical reasoning. To address this limitation, we propose a training-free three-stage pipeline,\textit{PhyRPR}:\textit{Phy\uline{R}eason}--\textit{Phy\uline{P}lan}--\textit{Phy\uline{R}efine}, which decouples physical understanding from visual synthesis. Specifically, \textit{PhyReason} uses a large multimodal model for physical state reasoning and an image generator for keyframe synthesis; \textit{PhyPlan} deterministically synthesizes a controllable coarse motion scaffold; and \textit{PhyRefine} injects this scaffold into diffusion sampling via a latent fusion strategy to refine appearance while preserving the planned dynamics. This staged design enables explicit physical control during generation. Extensive experiments under physics constraints show that our method consistently improves physical plausibility and motion controllability.
Any-to-Bokeh: One-Step Video Bokeh via Multi-Plane Image Guided Diffusion
May 27, 2025Recent advances in diffusion based editing models have enabled realistic camera simulation and image-based bokeh, but video bokeh remains largely unexplored. Existing video editing models cannot explicitly control focus planes or adjust bokeh intensity, limiting their applicability for controllable optical effects. Moreover, naively extending image-based bokeh methods to video often results in temporal flickering and unsatisfactory edge blur transitions due to the lack of temporal modeling and generalization capability. To address these challenges, we propose a novel one-step video bokeh framework that converts arbitrary input videos into temporally coherent, depth-aware bokeh effects. Our method leverages a multi-plane image (MPI) representation constructed through a progressively widening depth sampling function, providing explicit geometric guidance for depth-dependent blur synthesis. By conditioning a single-step video diffusion model on MPI layers and utilizing the strong 3D priors from pre-trained models such as Stable Video Diffusion, our approach achieves realistic and consistent bokeh effects across diverse scenes. Additionally, we introduce a progressive training strategy to enhance temporal consistency, depth robustness, and detail preservation. Extensive experiments demonstrate that our method produces high-quality, controllable bokeh effects and achieves state-of-the-art performance on multiple evaluation benchmarks.
SUDO: Enhancing Text-to-Image Diffusion Models with Self-Supervised Direct Preference Optimization
Apr 20, 2025



Previous text-to-image diffusion models typically employ supervised fine-tuning (SFT) to enhance pre-trained base models. However, this approach primarily minimizes the loss of mean squared error (MSE) at the pixel level, neglecting the need for global optimization at the image level, which is crucial for achieving high perceptual quality and structural coherence. In this paper, we introduce Self-sUpervised Direct preference Optimization (SUDO), a novel paradigm that optimizes both fine-grained details at the pixel level and global image quality. By integrating direct preference optimization into the model, SUDO generates preference image pairs in a self-supervised manner, enabling the model to prioritize global-level learning while complementing the pixel-level MSE loss. As an effective alternative to supervised fine-tuning, SUDO can be seamlessly applied to any text-to-image diffusion model. Importantly, it eliminates the need for costly data collection and annotation efforts typically associated with traditional direct preference optimization methods. Through extensive experiments on widely-used models, including Stable Diffusion 1.5 and XL, we demonstrate that SUDO significantly enhances both global and local image quality. The codes are provided at \href{https://github.com/SPengLiang/SUDO}{this link}.
Discriminator-Free Direct Preference Optimization for Video Diffusion
Apr 11, 2025Direct Preference Optimization (DPO), which aligns models with human preferences through win/lose data pairs, has achieved remarkable success in language and image generation. However, applying DPO to video diffusion models faces critical challenges: (1) Data inefficiency. Generating thousands of videos per DPO iteration incurs prohibitive costs; (2) Evaluation uncertainty. Human annotations suffer from subjective bias, and automated discriminators fail to detect subtle temporal artifacts like flickering or motion incoherence. To address these, we propose a discriminator-free video DPO framework that: (1) Uses original real videos as win cases and their edited versions (e.g., reversed, shuffled, or noise-corrupted clips) as lose cases; (2) Trains video diffusion models to distinguish and avoid artifacts introduced by editing. This approach eliminates the need for costly synthetic video comparisons, provides unambiguous quality signals, and enables unlimited training data expansion through simple editing operations. We theoretically prove the framework's effectiveness even when real videos and model-generated videos follow different distributions. Experiments on CogVideoX demonstrate the efficiency of the proposed method.
Improving Complex Reasoning with Dynamic Prompt Corruption: A soft prompt Optimization Approach
Mar 17, 2025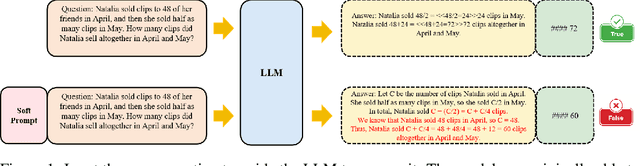

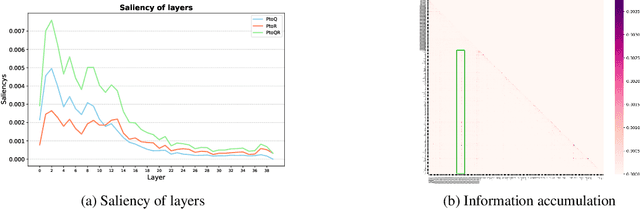

Prompt-tuning (PT) for large language models (LLMs) can facilitate the performance on various conventional NLP tasks with significantly fewer trainable parameters. However, our investigation reveals that PT provides limited improvement and may even degrade the primitive performance of LLMs on complex reasoning tasks. Such a phenomenon suggests that soft prompts can positively impact certain instances while negatively affecting others, particularly during the later phases of reasoning. To address these challenges, We first identify an information accumulation within the soft prompts. Through detailed analysis, we demonstrate that this phenomenon is often accompanied by erroneous information flow patterns in the deeper layers of the model, which ultimately lead to incorrect reasoning outcomes. we propose a novel method called \textbf{D}ynamic \textbf{P}rompt \textbf{C}orruption (DPC) to take better advantage of soft prompts in complex reasoning tasks, which dynamically adjusts the influence of soft prompts based on their impact on the reasoning process. Specifically, DPC consists of two stages: Dynamic Trigger and Dynamic Corruption. First, Dynamic Trigger measures the impact of soft prompts, identifying whether beneficial or detrimental. Then, Dynamic Corruption mitigates the negative effects of soft prompts by selectively masking key tokens that interfere with the reasoning process. We validate the proposed approach through extensive experiments on various LLMs and reasoning tasks, including GSM8K, MATH, and AQuA. Experimental results demonstrate that DPC can consistently enhance the performance of PT, achieving 4\%-8\% accuracy gains compared to vanilla prompt tuning, highlighting the effectiveness of our approach and its potential to enhance complex reasoning in LLMs.
SAMRefiner: Taming Segment Anything Model for Universal Mask Refinement
Feb 10, 2025



In this paper, we explore a principal way to enhance the quality of widely pre-existing coarse masks, enabling them to serve as reliable training data for segmentation models to reduce the annotation cost. In contrast to prior refinement techniques that are tailored to specific models or tasks in a close-world manner, we propose SAMRefiner, a universal and efficient approach by adapting SAM to the mask refinement task. The core technique of our model is the noise-tolerant prompting scheme. Specifically, we introduce a multi-prompt excavation strategy to mine diverse input prompts for SAM (i.e., distance-guided points, context-aware elastic bounding boxes, and Gaussian-style masks) from initial coarse masks. These prompts can collaborate with each other to mitigate the effect of defects in coarse masks. In particular, considering the difficulty of SAM to handle the multi-object case in semantic segmentation, we introduce a split-then-merge (STM) pipeline. Additionally, we extend our method to SAMRefiner++ by introducing an additional IoU adaption step to further boost the performance of the generic SAMRefiner on the target dataset. This step is self-boosted and requires no additional annotation. The proposed framework is versatile and can flexibly cooperate with existing segmentation methods. We evaluate our mask framework on a wide range of benchmarks under different settings, demonstrating better accuracy and efficiency. SAMRefiner holds significant potential to expedite the evolution of refinement tools. Our code is available at https://github.com/linyq2117/SAMRefiner.
Enhancing Multiple Dimensions of Trustworthiness in LLMs via Sparse Activation Control
Nov 04, 2024



As the development and application of Large Language Models (LLMs) continue to advance rapidly, enhancing their trustworthiness and aligning them with human preferences has become a critical area of research. Traditional methods rely heavily on extensive data for Reinforcement Learning from Human Feedback (RLHF), but representation engineering offers a new, training-free approach. This technique leverages semantic features to control the representation of LLM's intermediate hidden states, enabling the model to meet specific requirements such as increased honesty or heightened safety awareness. However, a significant challenge arises when attempting to fulfill multiple requirements simultaneously. It proves difficult to encode various semantic contents, like honesty and safety, into a singular semantic feature, restricting its practicality. In this work, we address this issue through ``Sparse Activation Control''. By delving into the intrinsic mechanisms of LLMs, we manage to identify and pinpoint components that are closely related to specific tasks within the model, i.e., attention heads. These heads display sparse characteristics that allow for near-independent control over different tasks. Our experiments, conducted on the open-source Llama series models, have yielded encouraging results. The models were able to align with human preferences on issues of safety, factuality, and bias concurrently.
SciPIP: An LLM-based Scientific Paper Idea Proposer
Oct 30, 2024



The exponential growth of knowledge and the increasing complexity of interdisciplinary research pose significant challenges for researchers, including information overload and difficulties in exploring novel ideas. The advancements in large language models (LLMs), such as GPT-4, have shown great potential in enhancing idea proposals, but how to effectively utilize large models for reasonable idea proposal has not been thoroughly explored. This paper proposes a scientific paper idea proposer (SciPIP). Based on a user-provided research background, SciPIP retrieves helpful papers from a literature database while leveraging the capabilities of LLMs to generate more novel and feasible ideas. To this end, 1) we construct a literature retrieval database, extracting lots of papers' multi-dimension information for fast access. Then, a literature retrieval method based on semantics, entity, and citation co-occurrences is proposed to search relevant literature from multiple aspects based on the user-provided background. 2) After literature retrieval, we introduce dual-path idea proposal strategies, where one path infers solutions from the retrieved literature and the other path generates original ideas through model brainstorming. We then combine the two to achieve a good balance between feasibility and originality. Through extensive experiments on the natural language processing (NLP) field, we demonstrate that SciPIP can retrieve citations similar to those of existing top conference papers and generate many ideas consistent with them. Additionally, we evaluate the originality of other ideas generated by SciPIP using large language models, further validating the effectiveness of our proposed method. The code and the database are released at https://github.com/cheerss/SciPIP.