 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Complex Reasoning with Dynamic Prompt Corruption: A soft prompt Optimization Approach
Mar 17, 2025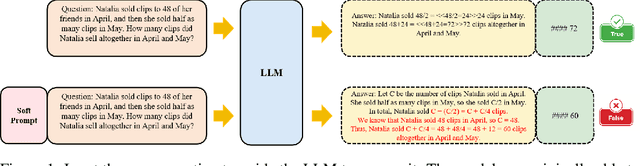

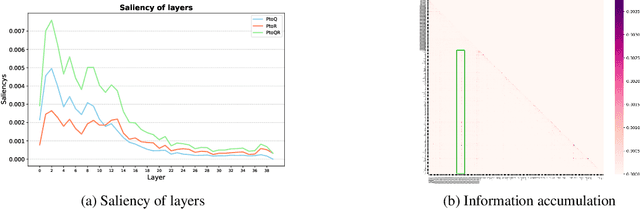

Prompt-tuning (PT) for large language models (LLMs) can facilitate the performance on various conventional NLP tasks with significantly fewer trainable parameters. However, our investigation reveals that PT provides limited improvement and may even degrade the primitive performance of LLMs on complex reasoning tasks. Such a phenomenon suggests that soft prompts can positively impact certain instances while negatively affecting others, particularly during the later phases of reasoning. To address these challenges, We first identify an information accumulation within the soft prompts. Through detailed analysis, we demonstrate that this phenomenon is often accompanied by erroneous information flow patterns in the deeper layers of the model, which ultimately lead to incorrect reasoning outcomes. we propose a novel method called \textbf{D}ynamic \textbf{P}rompt \textbf{C}orruption (DPC) to take better advantage of soft prompts in complex reasoning tasks, which dynamically adjusts the influence of soft prompts based on their impact on the reasoning process. Specifically, DPC consists of two stages: Dynamic Trigger and Dynamic Corruption. First, Dynamic Trigger measures the impact of soft prompts, identifying whether beneficial or detrimental. Then, Dynamic Corruption mitigates the negative effects of soft prompts by selectively masking key tokens that interfere with the reasoning process. We validate the proposed approach through extensive experiments on various LLMs and reasoning tasks, including GSM8K, MATH, and AQuA. Experimental results demonstrate that DPC can consistently enhance the performance of PT, achieving 4\%-8\% accuracy gains compared to vanilla prompt tuning, highlighting the effectiveness of our approach and its potential to enhance complex reasoning in LLMs.
URRL-IMVC: Unified and Robust Representation Learning for Incomplete Multi-View Clustering
Jul 12, 2024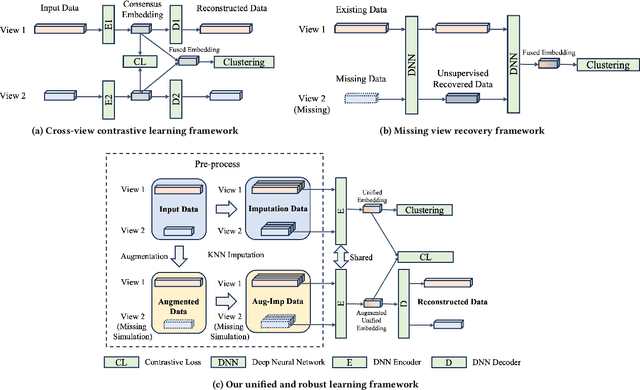
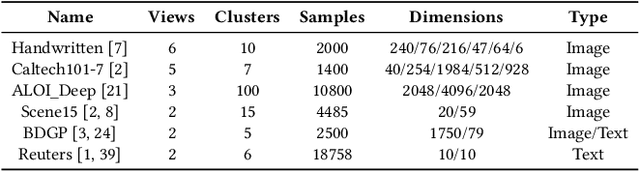
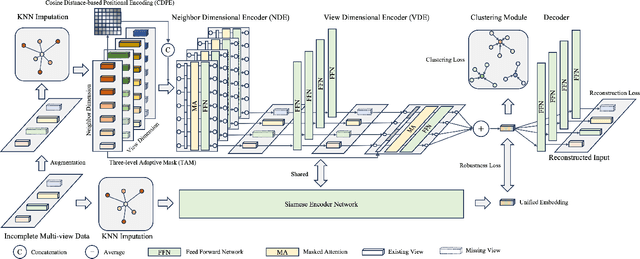
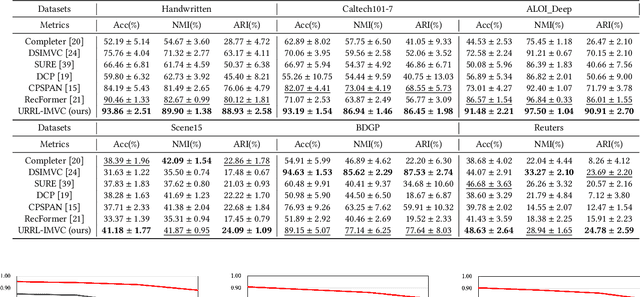
Incomplete multi-view clustering (IMVC) aims to cluster multi-view data that are only partially available. This poses two main challenges: effectively leveraging multi-view information and mitigating the impact of missing views. Prevailing solutions employ cross-view contrastive learning and missing view recovery techniques. However, they either neglect valuable complementary information by focusing only on consensus between views or provide unreliable recovered views due to the absence of supervision. To address these limitations, we propose a novel Unified and Robust Representation Learning for Incomplete Multi-View Clustering (URRL-IMVC). URRL-IMVC directly learns a unified embedding that is robust to view missing conditions by integrating information from multiple views and neighboring samples. Firstly, to overcome the limitations of cross-view contrastive learning, URRL-IMVC incorporates an attention-based auto-encoder framework to fuse multi-view information and generate unified embeddings. Secondly, URRL-IMVC directly enhances the robustness of the unified embedding against view-missing conditions through KNN imputation and data augmentation techniques, eliminating the need for explicit missing view recovery. Finally, incremental improvements are introduced to further enhance the overall performance, such as the Clustering Module and the customization of the Encoder. We extensively evaluate the proposed URRL-IMVC framework on various benchmark datasets, demonstrating its state-of-the-art performance. Furthermore, comprehensive ablation studies are performed to validate the effectiveness of our design.