 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Complex Reasoning with Dynamic Prompt Corruption: A soft prompt Optimization Approach
Paper and Code
Mar 17, 2025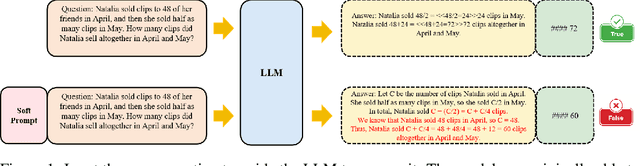

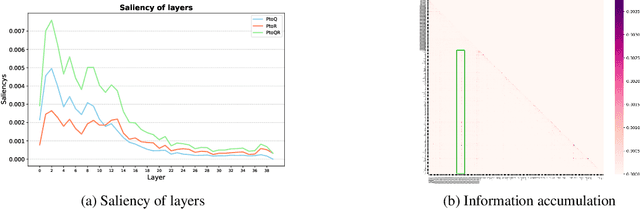

Prompt-tuning (PT) for large language models (LLMs) can facilitate the performance on various conventional NLP tasks with significantly fewer trainable parameters. However, our investigation reveals that PT provides limited improvement and may even degrade the primitive performance of LLMs on complex reasoning tasks. Such a phenomenon suggests that soft prompts can positively impact certain instances while negatively affecting others, particularly during the later phases of reasoning. To address these challenges, We first identify an information accumulation within the soft prompts. Through detailed analysis, we demonstrate that this phenomenon is often accompanied by erroneous information flow patterns in the deeper layers of the model, which ultimately lead to incorrect reasoning outcomes. we propose a novel method called \textbf{D}ynamic \textbf{P}rompt \textbf{C}orruption (DPC) to take better advantage of soft prompts in complex reasoning tasks, which dynamically adjusts the influence of soft prompts based on their impact on the reasoning process. Specifically, DPC consists of two stages: Dynamic Trigger and Dynamic Corruption. First, Dynamic Trigger measures the impact of soft prompts, identifying whether beneficial or detrimental. Then, Dynamic Corruption mitigates the negative effects of soft prompts by selectively masking key tokens that interfere with the reasoning process. We validate the proposed approach through extensive experiments on various LLMs and reasoning tasks, including GSM8K, MATH, and AQuA. Experimental results demonstrate that DPC can consistently enhance the performance of PT, achieving 4\%-8\% accuracy gains compared to vanilla prompt tuning, highlighting the effectiveness of our approach and its potential to enhance complex reasoning in LLMs.