 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHallucination Begins Where Saliency Drops
Jan 28, 2026Recent studies have examined attention dynamics in large vision-language models (LVLMs) to detect hallucinations. However, existing approaches remain limited in reliably distinguishing hallucinated from factually grounded outputs, as they rely solely on forward-pass attention patterns and neglect gradient-based signals that reveal how token influence propagates through the network. To bridge this gap, we introduce LVLMs-Saliency, a gradient-aware diagnostic framework that quantifies the visual grounding strength of each output token by fusing attention weights with their input gradients. Our analysis uncovers a decisive pattern: hallucinations frequently arise when preceding output tokens exhibit low saliency toward the prediction of the next token, signaling a breakdown in contextual memory retention. Leveraging this insight, we propose a dual-mechanism inference-time framework to mitigate hallucinations: (1) Saliency-Guided Rejection Sampling (SGRS), which dynamically filters candidate tokens during autoregressive decoding by rejecting those whose saliency falls below a context-adaptive threshold, thereby preventing coherence-breaking tokens from entering the output sequence; and (2) Local Coherence Reinforcement (LocoRE), a lightweight, plug-and-play module that strengthens attention from the current token to its most recent predecessors, actively counteracting the contextual forgetting behavior identified by LVLMs-Saliency. Extensive experiments across multiple LVLMs demonstrate that our method significantly reduces hallucination rates while preserving fluency and task performance, offering a robust and interpretable solution for enhancing model reliability. Code is available at: https://github.com/zhangbaijin/LVLMs-Saliency
Distribution-Aligned Sequence Distillation for Superior Long-CoT Reasoning
Jan 14, 2026In this report, we introduce DASD-4B-Thinking, a lightweight yet highly capable, fully open-source reasoning model. It achieves SOTA performance among open-source models of comparable scale across challenging benchmarks in mathematics, scientific reasoning, and code generation -- even outperforming several larger models. We begin by critically reexamining a widely adopted distillation paradigm in the community: SFT on teacher-generated responses, also known as sequence-level distillation. Although a series of recent works following this scheme have demonstrated remarkable efficiency and strong empirical performance, they are primarily grounded in the SFT perspective. Consequently, these approaches focus predominantly on designing heuristic rules for SFT data filtering, while largely overlooking the core principle of distillation itself -- enabling the student model to learn the teacher's full output distribution so as to inherit its generalization capability. Specifically, we identify three critical limitations in current practice: i) Inadequate representation of the teacher's sequence-level distribution; ii) Misalignment between the teacher's output distribution and the student's learning capacity; and iii) Exposure bias arising from teacher-forced training versus autoregressive inference. In summary, these shortcomings reflect a systemic absence of explicit teacher-student interaction throughout the distillation process, leaving the essence of distillation underexploited. To address these issues, we propose several methodological innovations that collectively form an enhanced sequence-level distillation training pipeline. Remarkably, DASD-4B-Thinking obtains competitive results using only 448K training samples -- an order of magnitude fewer than those employed by most existing open-source efforts. To support community research, we publicly release our models and the training dataset.
Improving Complex Reasoning with Dynamic Prompt Corruption: A soft prompt Optimization Approach
Mar 17, 2025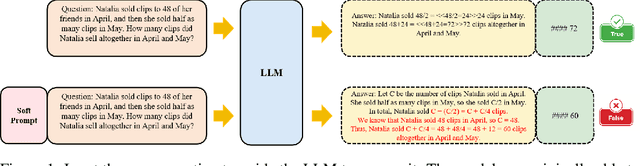

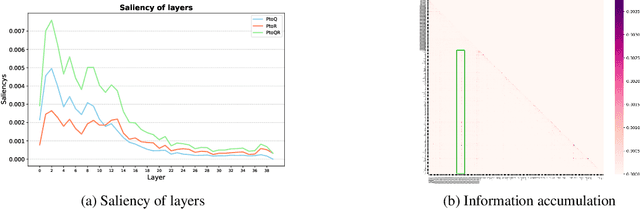

Prompt-tuning (PT) for large language models (LLMs) can facilitate the performance on various conventional NLP tasks with significantly fewer trainable parameters. However, our investigation reveals that PT provides limited improvement and may even degrade the primitive performance of LLMs on complex reasoning tasks. Such a phenomenon suggests that soft prompts can positively impact certain instances while negatively affecting others, particularly during the later phases of reasoning. To address these challenges, We first identify an information accumulation within the soft prompts. Through detailed analysis, we demonstrate that this phenomenon is often accompanied by erroneous information flow patterns in the deeper layers of the model, which ultimately lead to incorrect reasoning outcomes. we propose a novel method called \textbf{D}ynamic \textbf{P}rompt \textbf{C}orruption (DPC) to take better advantage of soft prompts in complex reasoning tasks, which dynamically adjusts the influence of soft prompts based on their impact on the reasoning process. Specifically, DPC consists of two stages: Dynamic Trigger and Dynamic Corruption. First, Dynamic Trigger measures the impact of soft prompts, identifying whether beneficial or detrimental. Then, Dynamic Corruption mitigates the negative effects of soft prompts by selectively masking key tokens that interfere with the reasoning process. We validate the proposed approach through extensive experiments on various LLMs and reasoning tasks, including GSM8K, MATH, and AQuA. Experimental results demonstrate that DPC can consistently enhance the performance of PT, achieving 4\%-8\% accuracy gains compared to vanilla prompt tuning, highlighting the effectiveness of our approach and its potential to enhance complex reasoning in LLMs.