 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Syntactic-Semantic Internet:Engineering Infrastructures for Autonomous Systems
Jan 31, 2026The Internet has evolved through successive architectural abstractions that enabled unprecedented scale, interoperability, and innovation. Packet-based networking enabled the reliable transport of bits; cloud-native systems enabled the orchestration of distributed computation. Today, the emergence of autonomous, learning-based systems introduces a new architectural challenge: intelligence is increasingly embedded directly into network control, computation, and decision-making, yet the Internet lacks a structural foundation for representing and exchanging meaning. In this paper, we argue that cognition alone: pattern recognition, prediction, and optimization, is insufficient for the next generation of networked systems. As autonomous agents act across safety-critical and socio-technical domains, systems must not only compute and communicate, but also comprehend intent, context, and consequence. We introduce the concept of a Semantic Layer: a new architectural stratum that treats meaning as a first-class construct, enabling interpretive alignment, semantic accountability, and intelligible autonomous behavior. We show that this evolution leads naturally to a Syntactic-Semantic Internet. The syntactic stack continues to transport bits, packets, and workloads with speed and reliability, while a parallel semantic stack transports meaning, grounding, and consequence. We describe the structure of this semantic stack-semantic communication, a semantic substrate, and an emerging Agentic Web, and draw explicit architectural parallels to TCP/IP and the World Wide Web. Finally, we examine current industry efforts, identify critical architectural gaps, and outline the engineering challenges required to make semantic interoperability a global, interoperable infrastructure.
A Survey on Semantic Communication for Vision: Categories, Frameworks, Enabling Techniques, and Applications
Jan 29, 2026Semantic communication (SemCom) emerges as a transformative paradigm for traffic-intensive visual data transmission, shifting focus from raw data to meaningful content transmission and relieving the increasing pressure on communication resources. However, to achieve SemCom, challenges are faced in accurate semantic quantization for visual data, robust semantic extraction and reconstruction under diverse tasks and goals, transceiver coordination with effective knowledge utilization, and adaptation to unpredictable wireless communication environments. In this paper, we present a systematic review of SemCom for visual data transmission (SemCom-Vision), wherein an interdisciplinary analysis integrating computer vision (CV) and communication engineering is conducted to provide comprehensive guidelines for the machine learning (ML)-empowered SemCom-Vision design. Specifically, this survey first elucidates the basics and key concepts of SemCom. Then, we introduce a novel classification perspective to categorize existing SemCom-Vision approaches as semantic preservation communication (SPC), semantic expansion communication (SEC), and semantic refinement communication (SRC) based on communication goals interpreted through semantic quantization schemes. Moreover, this survey articulates the ML-based encoder-decoder models and training algorithms for each SemCom-Vision category, followed by knowledge structure and utilization strategies. Finally, we discuss potential SemCom-Vision applications.
Adaptive Contextual Embedding for Robust Far-View Borehole Detection
May 08, 2025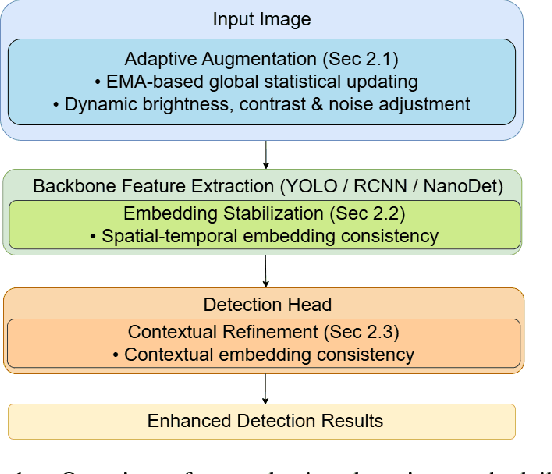
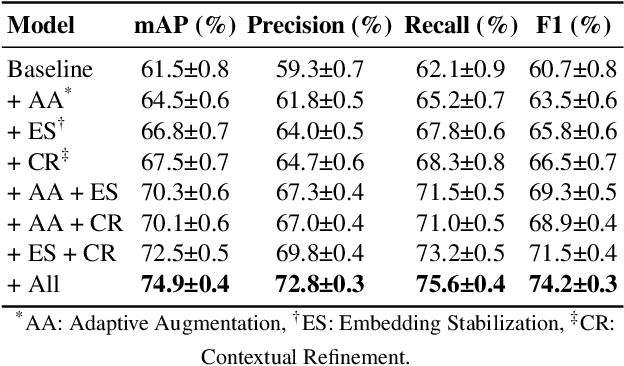

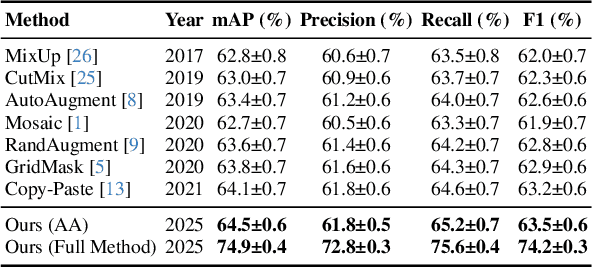
In controlled blasting operations, accurately detecting densely distributed tiny boreholes from far-view imagery is critical for operational safety and efficiency. However, existing detection methods often struggle due to small object scales, highly dense arrangements, and limited distinctive visual features of boreholes. To address these challenges, we propose an adaptive detection approach that builds upon existing architectures (e.g., YOLO) by explicitly leveraging consistent embedding representations derived through exponential moving average (EMA)-based statistical updates. Our method introduces three synergistic components: (1) adaptive augmentation utilizing dynamically updated image statistics to robustly handle illumination and texture variations; (2) embedding stabilization to ensure consistent and reliable feature extraction; and (3) contextual refinement leveraging spatial context for improved detection accuracy. The pervasive use of EMA in our method is particularly advantageous given the limited visual complexity and small scale of boreholes, allowing stable and robust representation learning even under challenging visual conditions. Experiments on a challenging proprietary quarry-site dataset demonstrate substantial improvements over baseline YOLO-based architectures, highlighting our method's effectiveness in realistic and complex industrial scenarios.
Joint Knowledge and Power Management for Secure Semantic Communication Networks
Apr 21, 2025Recently, semantic communication (SemCom) has shown its great superiorities in resource savings and information exchanges. However, while its unique background knowledge guarantees accurate semantic reasoning and recovery, semantic information security-related concerns are introduced at the same time. Since the potential eavesdroppers may have the same background knowledge to accurately decrypt the private semantic information transmitted between legal SemCom users, this makes the knowledge management in SemCom networks rather challenging in joint consideration with the power control. To this end, this paper focuses on jointly addressing three core issues of power allocation, knowledge base caching (KBC), and device-to-device (D2D) user pairing (DUP) in secure SemCom networks. We first develop a novel performance metric, namely semantic secrecy throughput (SST), to quantify the information security level that can be achieved at each pair of D2D SemCom users. Next, an SST maximization problem is formulated subject to secure SemCom-related delay and reliability constraints. Afterward, we propose a security-aware resource management solution using the Lagrange primal-dual method and a two-stage method. Simulation results demonstrate our proposed solution nearly doubles the SST performance and realizes less than half of the queuing delay performance compared to different benchmarks.
SmokeNet: Efficient Smoke Segmentation Leveraging Multiscale Convolutions and Multiview Attention Mechanisms
Feb 17, 2025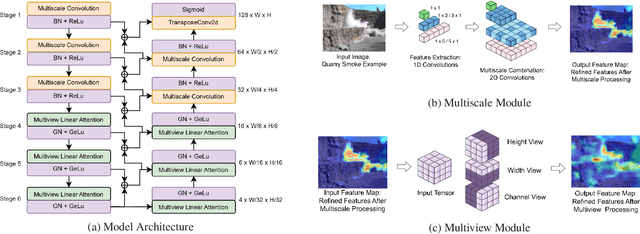
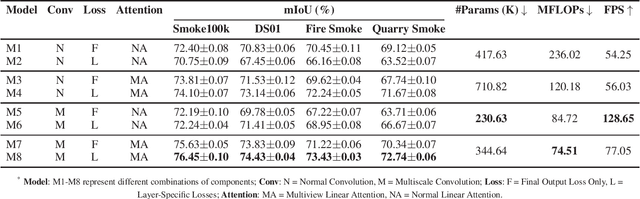
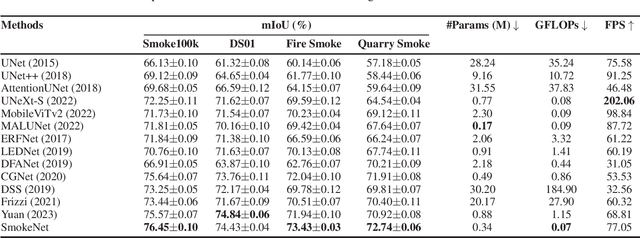

Efficient segmentation of smoke plumes is crucial for environmental monitoring and industrial safety, enabling the detection and mitigation of harmful emissions from activities like quarry blasts and wildfires. Accurate segmentation facilitates environmental impact assessments, timely interventions, and compliance with safety standards. However, existing models often face high computational demands and limited adaptability to diverse smoke appearances, restricting their deployment in resource-constrained environments. To address these issues, we introduce SmokeNet, a novel deep learning architecture that leverages multiscale convolutions and multiview linear attention mechanisms combined with layer-specific loss functions to handle the complex dynamics of diverse smoke plumes, ensuring efficient and accurate segmentation across varied environments. Additionally, we evaluate SmokeNet's performance and versatility using four datasets, including our quarry blast smoke dataset made available to the community. The results demonstrate that SmokeNet maintains a favorable balance between computational efficiency and segmentation accuracy, making it suitable for deployment in environmental monitoring and safety management systems. By contributing a new dataset and offering an efficient segmentation model, SmokeNet advances smoke segmentation capabilities in diverse and challenging environments.
URRL-IMVC: Unified and Robust Representation Learning for Incomplete Multi-View Clustering
Jul 12, 2024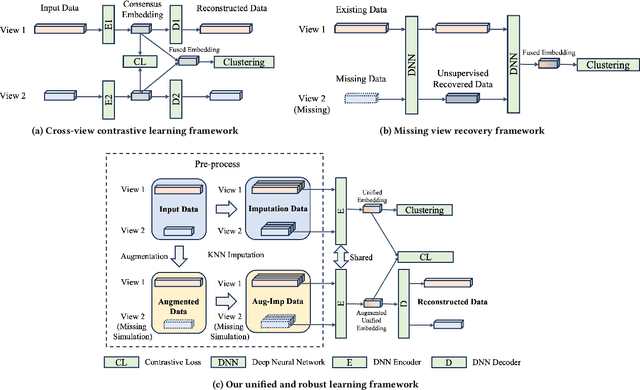
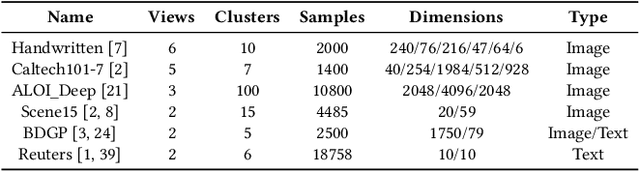
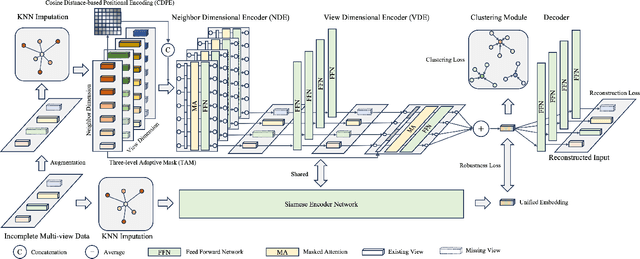
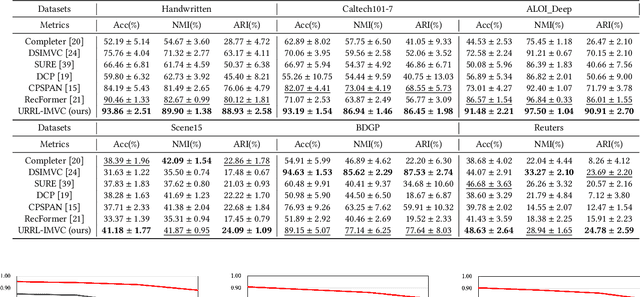
Incomplete multi-view clustering (IMVC) aims to cluster multi-view data that are only partially available. This poses two main challenges: effectively leveraging multi-view information and mitigating the impact of missing views. Prevailing solutions employ cross-view contrastive learning and missing view recovery techniques. However, they either neglect valuable complementary information by focusing only on consensus between views or provide unreliable recovered views due to the absence of supervision. To address these limitations, we propose a novel Unified and Robust Representation Learning for Incomplete Multi-View Clustering (URRL-IMVC). URRL-IMVC directly learns a unified embedding that is robust to view missing conditions by integrating information from multiple views and neighboring samples. Firstly, to overcome the limitations of cross-view contrastive learning, URRL-IMVC incorporates an attention-based auto-encoder framework to fuse multi-view information and generate unified embeddings. Secondly, URRL-IMVC directly enhances the robustness of the unified embedding against view-missing conditions through KNN imputation and data augmentation techniques, eliminating the need for explicit missing view recovery. Finally, incremental improvements are introduced to further enhance the overall performance, such as the Clustering Module and the customization of the Encoder. We extensively evaluate the proposed URRL-IMVC framework on various benchmark datasets, demonstrating its state-of-the-art performance. Furthermore, comprehensive ablation studies are performed to validate the effectiveness of our design.
Self-Learning Symmetric Multi-view Probabilistic Clustering
May 12, 2023



Multi-view Clustering (MVC) has achieved significant progress, with many efforts dedicated to learn knowledge from multiple views. However, most existing methods are either not applicable or require additional steps for incomplete multi-view clustering. Such a limitation results in poor-quality clustering performance and poor missing view adaptation. Besides, noise or outliers might significantly degrade the overall clustering performance, which are not handled well by most existing methods. Moreover, category information is required in most existing methods, which severely affects the clustering performance. In this paper, we propose a novel unified framework for incomplete and complete MVC named self-learning symmetric multi-view probabilistic clustering (SLS-MPC). SLS-MPC proposes a novel symmetric multi-view probability estimation and equivalently transforms multi-view pairwise posterior matching probability into composition of each view's individual distribution, which tolerates data missing and might extend to any number of views. Then, SLS-MPC proposes a novel self-learning probability function without any prior knowledge and hyper-parameters to learn each view's individual distribution from the aspect of consistency in single-view, cross-view and multi-view. Next, graph-context-aware refinement with path propagation and co-neighbor propagation is used to refine pairwise probability, which alleviates the impact of noise and outliers. Finally, SLS-MPC proposes a probabilistic clustering algorithm to adjust clustering assignments by maximizing the joint probability iteratively, in which category information is not required. Extensive experiments on multiple benchmarks for incomplete and complete MVC show that SLS-MPC significantly outperforms previous state-of-the-art methods.
Implicit Dual-domain Convolutional Network for Robust Color Image Compression Artifact Reduction
Oct 18, 2018

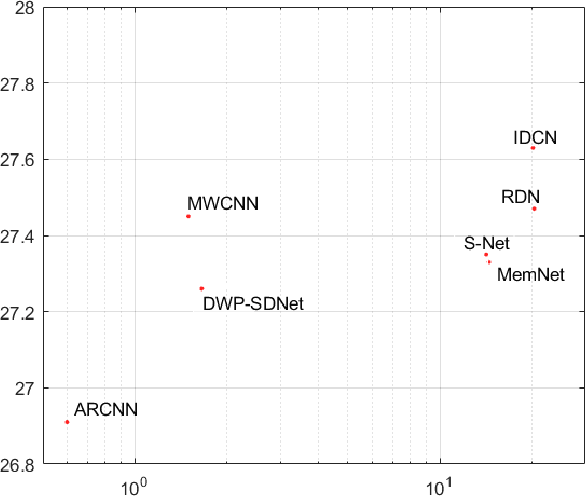
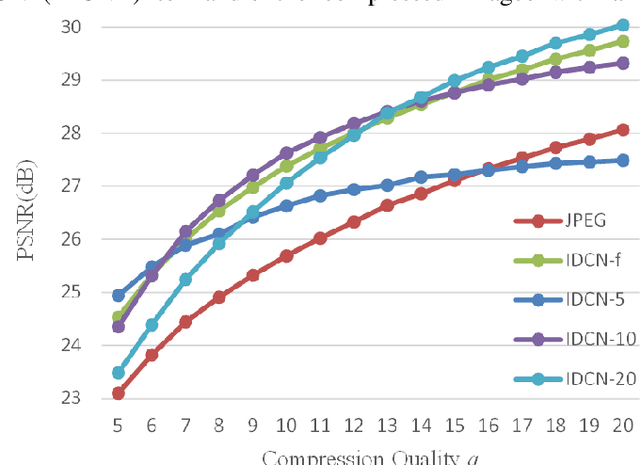
Several dual-domain convolutional neural network-based methods show outstanding performance in reducing image compression artifacts. However, they suffer from handling color images because the compression processes for gray-scale and color images are completely different. Moreover, these methods train a specific model for each compression quality and require multiple models to achieve different compression qualities. To address these problems, we proposed an implicit dual-domain convolutional network (IDCN) with the pixel position labeling map and the quantization tables as inputs. Specifically, we proposed an extractor-corrector framework-based dual-domain correction unit (DRU) as the basic component to formulate the IDCN. A dense block was introduced to improve the performance of extractor in DRU. The implicit dual-domain translation allows the IDCN to handle color images with the discrete cosine transform (DCT)-domain priors. A flexible version of IDCN (IDCN-f) was developed to handle a wide range of compression qualities. Experiments for both objective and subjective evaluations on benchmark datasets show that IDCN is superior to the state-of-the-art methods and IDCN-f exhibits excellent abilities to handle a wide range of compression qualities with little performance sacrifice and demonstrates great potential for practical applications.