 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Deep Learning and Statistical Target Detection Methods for PFM-1 Landmine Detection in UAV Hyperspectral Imagery
Feb 11, 2026In recent years, unmanned aerial vehicles (UAVs) equipped with imaging sensors and automated processing algorithms have emerged as a promising tool to accelerate large-area surveys while reducing risk to human operators. Although hyperspectral imaging (HSI) enables material discrimination using spectral signatures, standardized benchmarks for UAV-based landmine detection remain scarce. In this work, we present a systematic benchmark of four classical statistical detection algorithms, including Spectral Angle Mapper (SAM), Matched Filter (MF), Adaptive Cosine Estimator (ACE), and Constrained Energy Minimization (CEM), alongside a proposed lightweight Spectral Neural Network utilizing Parametric Mish activations for PFM-1 landmine detection. We also release pixel-level binary ground truth masks (target/background) to enable standardized, reproducible evaluation. Evaluations were conducted on inert PFM-1 targets across multiple scene crops using a recently released VNIR hyperspectral dataset. Metrics such as receiver operating characteristic (ROC) curve, area under the curve (AUC), precision-recall (PR) curve, and average precision (AP) were used. While all methods achieve high ROC-AUC on an independent test set, the ACE method observes the highest AUC of 0.989. However, because target pixels are extremely sparse relative to background, ROC-AUC alone can be misleading; under precision-focused evaluation (PR and AP), the Spectral-NN outperforms classical detectors, achieving the highest AP. These results emphasize the need for precision-focused evaluation, scene-aware benchmarking, and learning-based spectral models for reliable UAV-based hyperspectral landmine detection. The code and pixel-level annotations will be released.
Adaptive Contextual Embedding for Robust Far-View Borehole Detection
May 08, 2025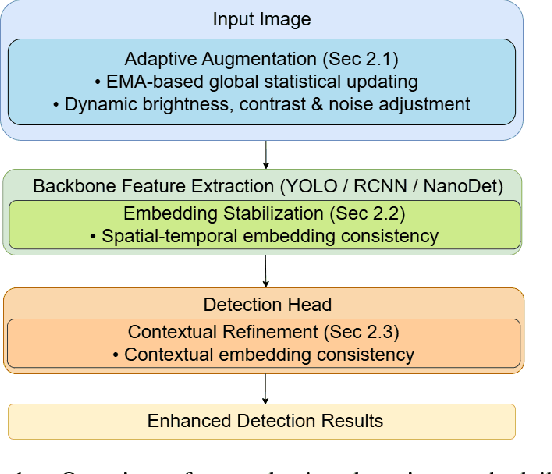
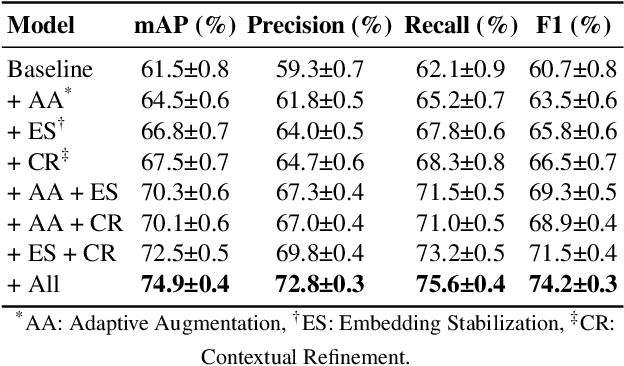

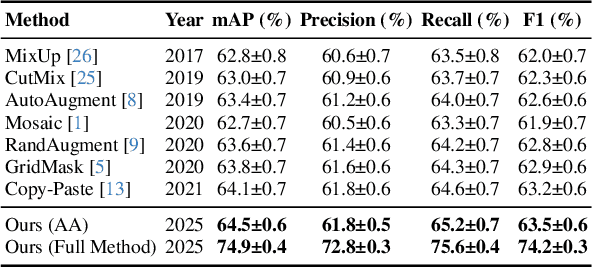
In controlled blasting operations, accurately detecting densely distributed tiny boreholes from far-view imagery is critical for operational safety and efficiency. However, existing detection methods often struggle due to small object scales, highly dense arrangements, and limited distinctive visual features of boreholes. To address these challenges, we propose an adaptive detection approach that builds upon existing architectures (e.g., YOLO) by explicitly leveraging consistent embedding representations derived through exponential moving average (EMA)-based statistical updates. Our method introduces three synergistic components: (1) adaptive augmentation utilizing dynamically updated image statistics to robustly handle illumination and texture variations; (2) embedding stabilization to ensure consistent and reliable feature extraction; and (3) contextual refinement leveraging spatial context for improved detection accuracy. The pervasive use of EMA in our method is particularly advantageous given the limited visual complexity and small scale of boreholes, allowing stable and robust representation learning even under challenging visual conditions. Experiments on a challenging proprietary quarry-site dataset demonstrate substantial improvements over baseline YOLO-based architectures, highlighting our method's effectiveness in realistic and complex industrial scenarios.
SmokeNet: Efficient Smoke Segmentation Leveraging Multiscale Convolutions and Multiview Attention Mechanisms
Feb 17, 2025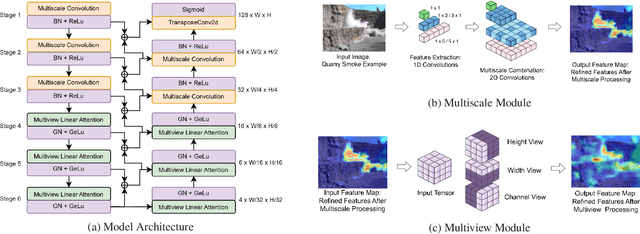
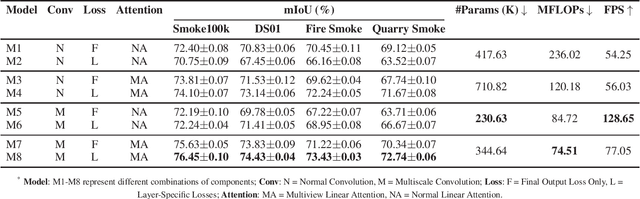
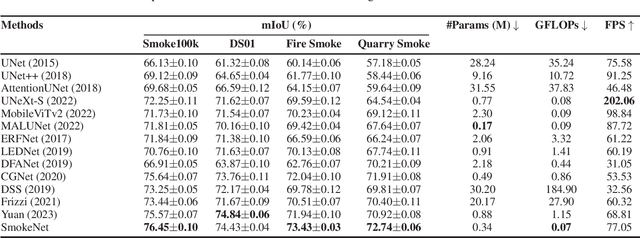

Efficient segmentation of smoke plumes is crucial for environmental monitoring and industrial safety, enabling the detection and mitigation of harmful emissions from activities like quarry blasts and wildfires. Accurate segmentation facilitates environmental impact assessments, timely interventions, and compliance with safety standards. However, existing models often face high computational demands and limited adaptability to diverse smoke appearances, restricting their deployment in resource-constrained environments. To address these issues, we introduce SmokeNet, a novel deep learning architecture that leverages multiscale convolutions and multiview linear attention mechanisms combined with layer-specific loss functions to handle the complex dynamics of diverse smoke plumes, ensuring efficient and accurate segmentation across varied environments. Additionally, we evaluate SmokeNet's performance and versatility using four datasets, including our quarry blast smoke dataset made available to the community. The results demonstrate that SmokeNet maintains a favorable balance between computational efficiency and segmentation accuracy, making it suitable for deployment in environmental monitoring and safety management systems. By contributing a new dataset and offering an efficient segmentation model, SmokeNet advances smoke segmentation capabilities in diverse and challenging environments.
A Fully Convolutional Network for Semantic Labeling of 3D Point Clouds
Oct 03, 2017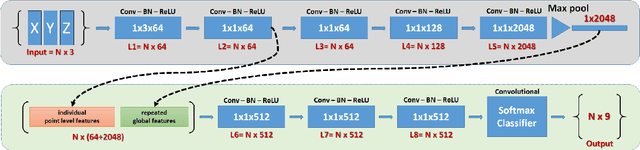
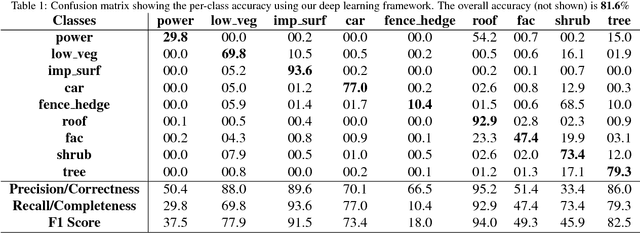

When classifying point clouds, a large amount of time is devoted to the process of engineering a reliable set of features which are then passed to a classifier of choice. Generally, such features - usually derived from the 3D-covariance matrix - are computed using the surrounding neighborhood of points. While these features capture local information, the process is usually time-consuming, and requires the application at multiple scales combined with contextual methods in order to adequately describe the diversity of objects within a scene. In this paper we present a 1D-fully convolutional network that consumes terrain-normalized points directly with the corresponding spectral data,if available, to generate point-wise labeling while implicitly learning contextual features in an end-to-end fashion. Our method uses only the 3D-coordinates and three corresponding spectral features for each point. Spectral features may either be extracted from 2D-georeferenced images, as shown here for Light Detection and Ranging (LiDAR) point clouds, or extracted directly for passive-derived point clouds,i.e. from muliple-view imagery. We train our network by splitting the data into square regions, and use a pooling layer that respects the permutation-invariance of the input points. Evaluated using the ISPRS 3D Semantic Labeling Contest, our method scored second place with an overall accuracy of 81.6%. We ranked third place with a mean F1-score of 63.32%, surpassing the F1-score of the method with highest accuracy by 1.69%. In addition to labeling 3D-point clouds, we also show that our method can be easily extended to 2D-semantic segmentation tasks, with promising initial results.