 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Nearest Neighbor Network to Extract Digital Terrain Models from 3D Point Clouds
Jun 20, 2020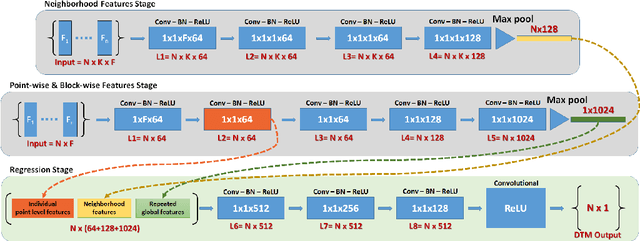
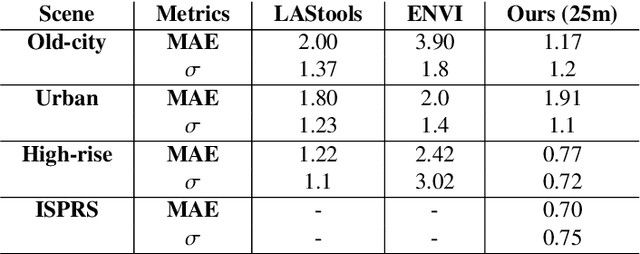
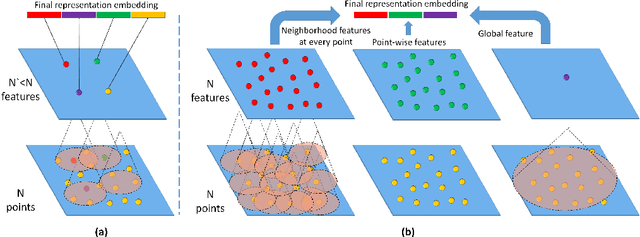

When 3D-point clouds from overhead sensors are used as input to remote sensing data exploitation pipelines, a large amount of effort is devoted to data preparation. Among the multiple stages of the preprocessing chain, estimating the Digital Terrain Model (DTM) model is considered to be of a high importance; however, this remains a challenge, especially for raw point clouds derived from optical imagery. Current algorithms estimate the ground points using either a set of geometrical rules that require tuning multiple parameters and human interaction, or cast the problem as a binary classification machine learning task where ground and non-ground classes are found. In contrast, here we present an algorithm that directly operates on 3D-point clouds and estimate the underlying DTM for the scene using an end-to-end approach without the need to classify points into ground and non-ground cover types. Our model learns neighborhood information and seamlessly integrates this with point-wise and block-wise global features. We validate our model using the ISPRS 3D Semantic Labeling Contest LiDAR data, as well as three scenes generated using dense stereo matching, representative of high-rise buildings, lower urban structures, and a dense old-city residential area. We compare our findings with two widely used software packages for DTM extraction, namely ENVI and LAStools. Our preliminary results show that the proposed method is able to achieve an overall Mean Absolute Error of 11.5% compared to 29% and 16% for ENVI and LAStools.
A Fully Convolutional Network for Semantic Labeling of 3D Point Clouds
Oct 03, 2017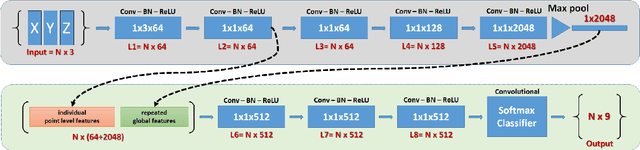
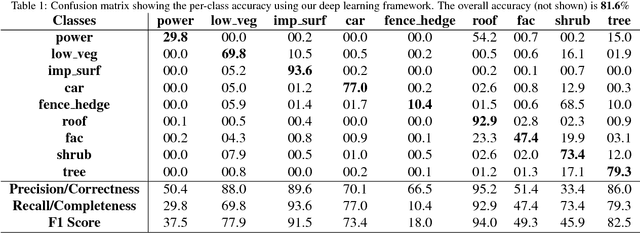

When classifying point clouds, a large amount of time is devoted to the process of engineering a reliable set of features which are then passed to a classifier of choice. Generally, such features - usually derived from the 3D-covariance matrix - are computed using the surrounding neighborhood of points. While these features capture local information, the process is usually time-consuming, and requires the application at multiple scales combined with contextual methods in order to adequately describe the diversity of objects within a scene. In this paper we present a 1D-fully convolutional network that consumes terrain-normalized points directly with the corresponding spectral data,if available, to generate point-wise labeling while implicitly learning contextual features in an end-to-end fashion. Our method uses only the 3D-coordinates and three corresponding spectral features for each point. Spectral features may either be extracted from 2D-georeferenced images, as shown here for Light Detection and Ranging (LiDAR) point clouds, or extracted directly for passive-derived point clouds,i.e. from muliple-view imagery. We train our network by splitting the data into square regions, and use a pooling layer that respects the permutation-invariance of the input points. Evaluated using the ISPRS 3D Semantic Labeling Contest, our method scored second place with an overall accuracy of 81.6%. We ranked third place with a mean F1-score of 63.32%, surpassing the F1-score of the method with highest accuracy by 1.69%. In addition to labeling 3D-point clouds, we also show that our method can be easily extended to 2D-semantic segmentation tasks, with promising initial results.