 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Nearest Neighbor Network to Extract Digital Terrain Models from 3D Point Clouds
Jun 20, 2020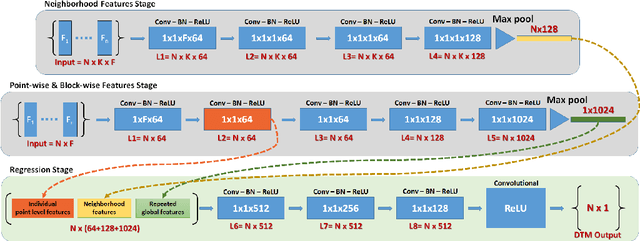
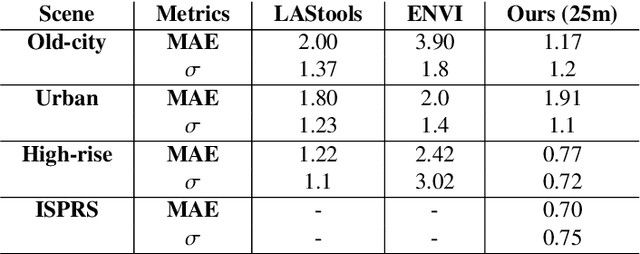
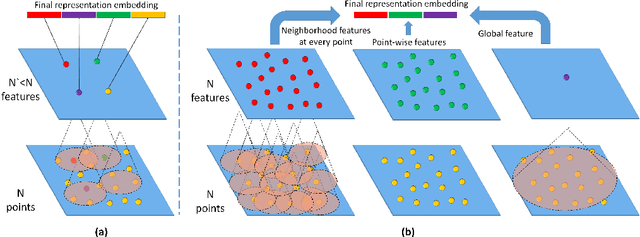

When 3D-point clouds from overhead sensors are used as input to remote sensing data exploitation pipelines, a large amount of effort is devoted to data preparation. Among the multiple stages of the preprocessing chain, estimating the Digital Terrain Model (DTM) model is considered to be of a high importance; however, this remains a challenge, especially for raw point clouds derived from optical imagery. Current algorithms estimate the ground points using either a set of geometrical rules that require tuning multiple parameters and human interaction, or cast the problem as a binary classification machine learning task where ground and non-ground classes are found. In contrast, here we present an algorithm that directly operates on 3D-point clouds and estimate the underlying DTM for the scene using an end-to-end approach without the need to classify points into ground and non-ground cover types. Our model learns neighborhood information and seamlessly integrates this with point-wise and block-wise global features. We validate our model using the ISPRS 3D Semantic Labeling Contest LiDAR data, as well as three scenes generated using dense stereo matching, representative of high-rise buildings, lower urban structures, and a dense old-city residential area. We compare our findings with two widely used software packages for DTM extraction, namely ENVI and LAStools. Our preliminary results show that the proposed method is able to achieve an overall Mean Absolute Error of 11.5% compared to 29% and 16% for ENVI and LAStools.
Batch-normalized Recurrent Highway Networks
Sep 26, 2018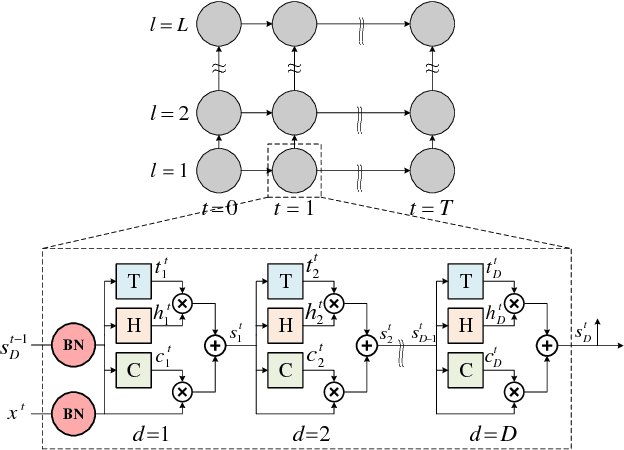

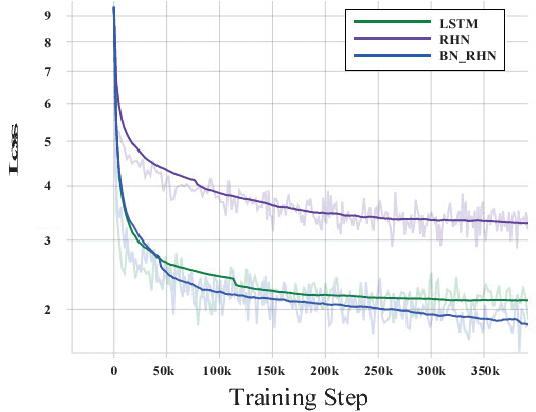

Gradient control plays an important role in feed-forward networks applied to various computer vision tasks. Previous work has shown that Recurrent Highway Networks minimize the problem of vanishing or exploding gradients. They achieve this by setting the eigenvalues of the temporal Jacobian to 1 across the time steps. In this work, batch normalized recurrent highway networks are proposed to control the gradient flow in an improved way for network convergence. Specifically, the introduced model can be formed by batch normalizing the inputs at each recurrence loop. The proposed model is tested on an image captioning task using MSCOCO dataset. Experimental results indicate that the batch normalized recurrent highway networks converge faster and performs better compared with the traditional LSTM and RHN based models.
Semantic Sentence Embeddings for Paraphrasing and Text Summarization
Sep 26, 2018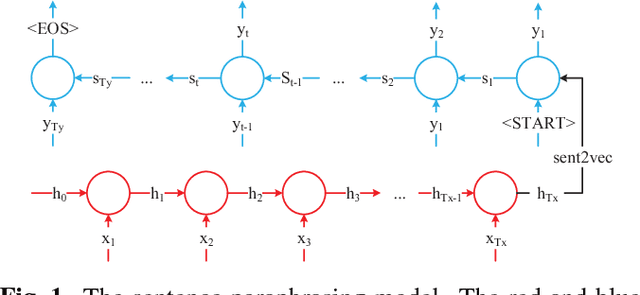
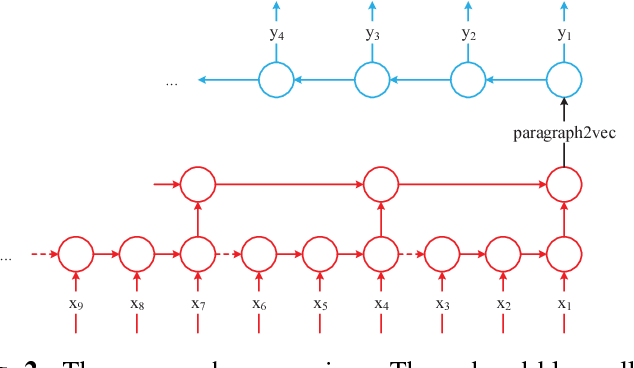
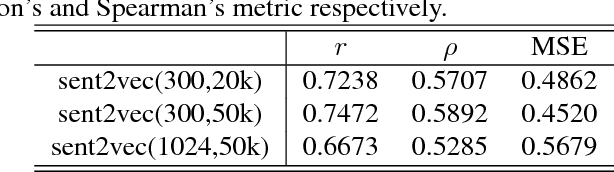
This paper introduces a sentence to vector encoding framework suitable for advanced natural language processing. Our latent representation is shown to encode sentences with common semantic information with similar vector representations. The vector representation is extracted from an encoder-decoder model which is trained on sentence paraphrase pairs. We demonstrate the application of the sentence representations for two different tasks -- sentence paraphrasing and paragraph summarization, making it attractive for commonly used recurrent frameworks that process text. Experimental results help gain insight how vector representations are suitable for advanced language embedding.
Algorithms for Semantic Segmentation of Multispectral Remote Sensing Imagery using Deep Learning
May 01, 2018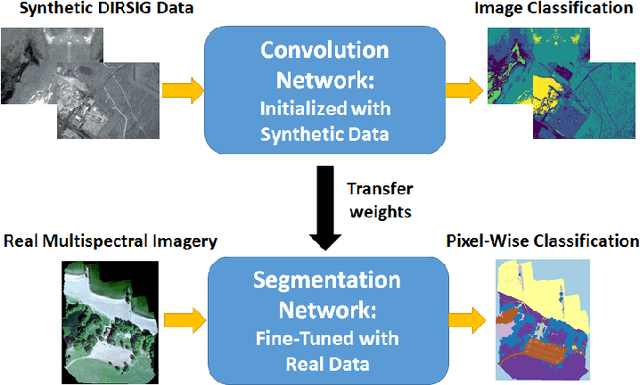
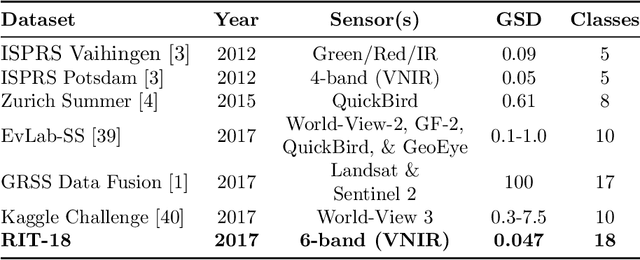
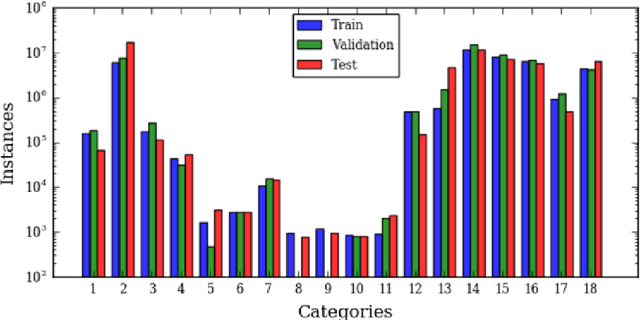

Deep convolutional neural networks (DCNNs) have been used to achieve state-of-the-art performance on many computer vision tasks (e.g., object recognition, object detection, semantic segmentation) thanks to a large repository of annotated image data. Large labeled datasets for other sensor modalities, e.g., multispectral imagery (MSI), are not available due to the large cost and manpower required. In this paper, we adapt state-of-the-art DCNN frameworks in computer vision for semantic segmentation for MSI imagery. To overcome label scarcity for MSI data, we substitute real MSI for generated synthetic MSI in order to initialize a DCNN framework. We evaluate our network initialization scheme on the new RIT-18 dataset that we present in this paper. This dataset contains very-high resolution MSI collected by an unmanned aircraft system. The models initialized with synthetic imagery were less prone to over-fitting and provide a state-of-the-art baseline for future work.
* 45 pages
A Fully Convolutional Network for Semantic Labeling of 3D Point Clouds
Oct 03, 2017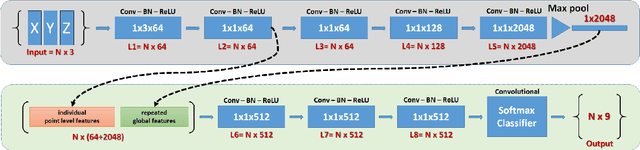
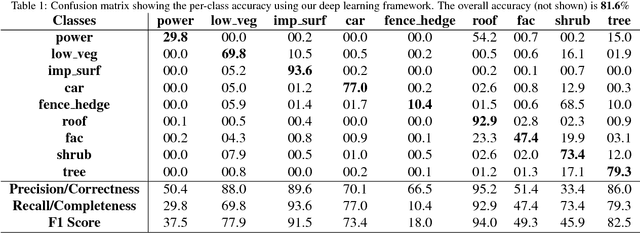

When classifying point clouds, a large amount of time is devoted to the process of engineering a reliable set of features which are then passed to a classifier of choice. Generally, such features - usually derived from the 3D-covariance matrix - are computed using the surrounding neighborhood of points. While these features capture local information, the process is usually time-consuming, and requires the application at multiple scales combined with contextual methods in order to adequately describe the diversity of objects within a scene. In this paper we present a 1D-fully convolutional network that consumes terrain-normalized points directly with the corresponding spectral data,if available, to generate point-wise labeling while implicitly learning contextual features in an end-to-end fashion. Our method uses only the 3D-coordinates and three corresponding spectral features for each point. Spectral features may either be extracted from 2D-georeferenced images, as shown here for Light Detection and Ranging (LiDAR) point clouds, or extracted directly for passive-derived point clouds,i.e. from muliple-view imagery. We train our network by splitting the data into square regions, and use a pooling layer that respects the permutation-invariance of the input points. Evaluated using the ISPRS 3D Semantic Labeling Contest, our method scored second place with an overall accuracy of 81.6%. We ranked third place with a mean F1-score of 63.32%, surpassing the F1-score of the method with highest accuracy by 1.69%. In addition to labeling 3D-point clouds, we also show that our method can be easily extended to 2D-semantic segmentation tasks, with promising initial results.
High-Resolution Multispectral Dataset for Semantic Segmentation
Mar 06, 2017
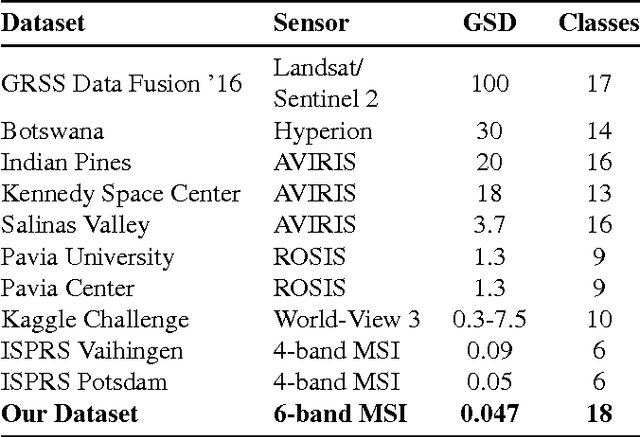


Unmanned aircraft have decreased the cost required to collect remote sensing imagery, which has enabled researchers to collect high-spatial resolution data from multiple sensor modalities more frequently and easily. The increase in data will push the need for semantic segmentation frameworks that are able to classify non-RGB imagery, but this type of algorithmic development requires an increase in publicly available benchmark datasets with class labels. In this paper, we introduce a high-resolution multispectral dataset with image labels. This new benchmark dataset has been pre-split into training/testing folds in order to standardize evaluation and continue to push state-of-the-art classification frameworks for non-RGB imagery.