 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBatch-normalized Recurrent Highway Networks
Sep 26, 2018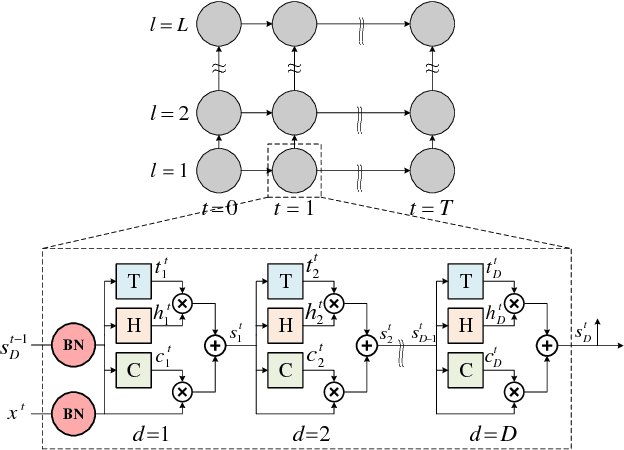

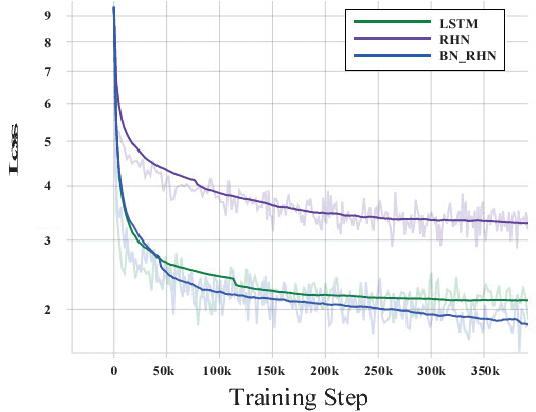

Gradient control plays an important role in feed-forward networks applied to various computer vision tasks. Previous work has shown that Recurrent Highway Networks minimize the problem of vanishing or exploding gradients. They achieve this by setting the eigenvalues of the temporal Jacobian to 1 across the time steps. In this work, batch normalized recurrent highway networks are proposed to control the gradient flow in an improved way for network convergence. Specifically, the introduced model can be formed by batch normalizing the inputs at each recurrence loop. The proposed model is tested on an image captioning task using MSCOCO dataset. Experimental results indicate that the batch normalized recurrent highway networks converge faster and performs better compared with the traditional LSTM and RHN based models.
Semantic Sentence Embeddings for Paraphrasing and Text Summarization
Sep 26, 2018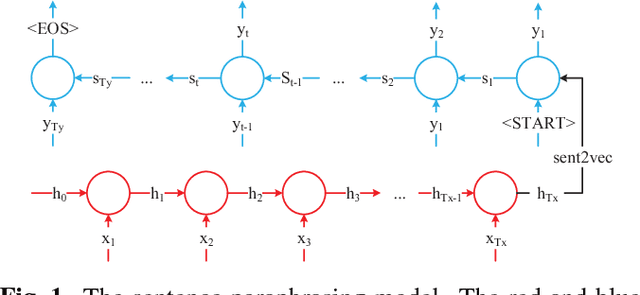
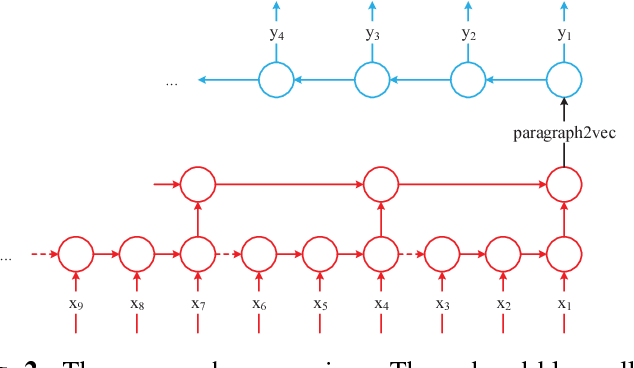
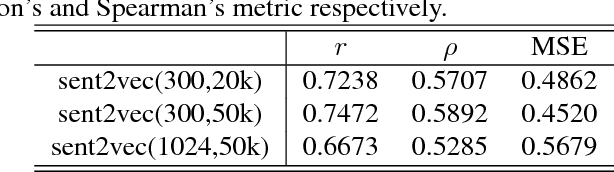
This paper introduces a sentence to vector encoding framework suitable for advanced natural language processing. Our latent representation is shown to encode sentences with common semantic information with similar vector representations. The vector representation is extracted from an encoder-decoder model which is trained on sentence paraphrase pairs. We demonstrate the application of the sentence representations for two different tasks -- sentence paraphrasing and paragraph summarization, making it attractive for commonly used recurrent frameworks that process text. Experimental results help gain insight how vector representations are suitable for advanced language embedding.
A Coarse-To-Fine Framework For Video Object Segmentation
Sep 26, 2018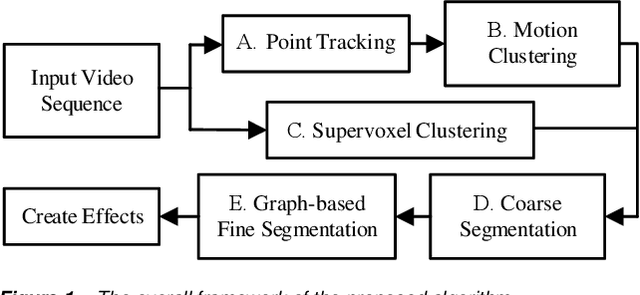


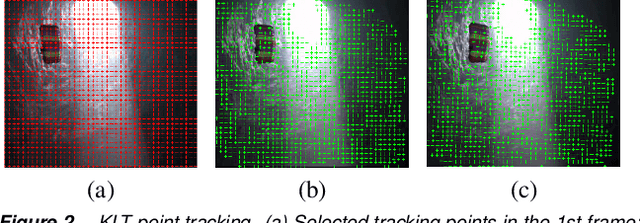
In this study, we develop an unsupervised coarse-to-fine video analysis framework and prototype system to extract a salient object in a video sequence. This framework starts from tracking grid-sampled points along temporal frames, typically using KLT tracking method. The tracking points could be divided into several groups due to their inconsistent movements. At the same time, the SLIC algorithm is extended into 3D space to generate supervoxels. Coarse segmentation is achieved by combining the categorized tracking points and supervoxels of the corresponding frame in the video sequence. Finally, a graph-based fine segmentation algorithm is used to extract the moving object in the scene. Experimental results reveal that this method outperforms the previous approaches in terms of accuracy and robustness.