 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Hierarchical Decomposition of Large Deep Networks
Jul 17, 2020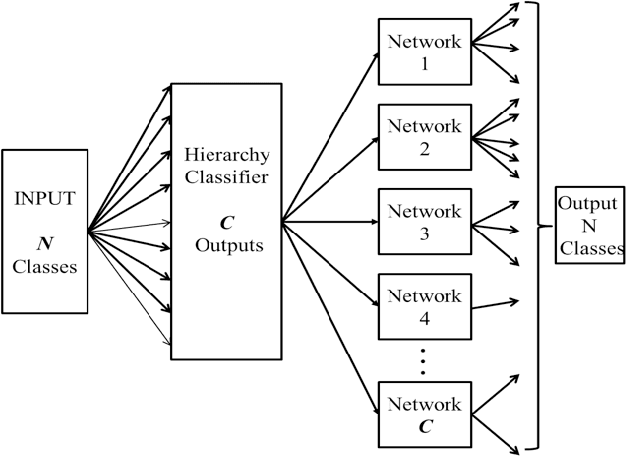
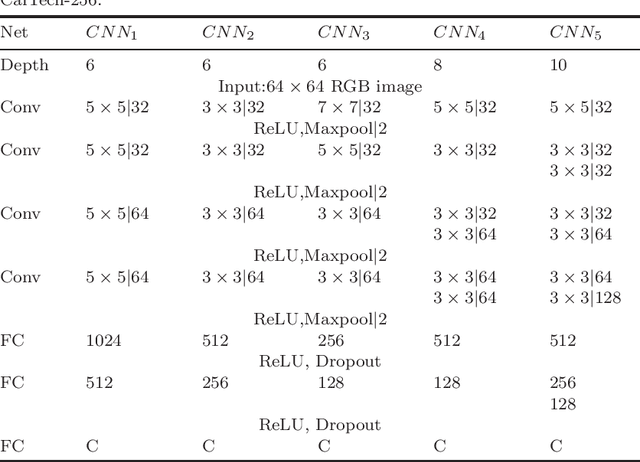

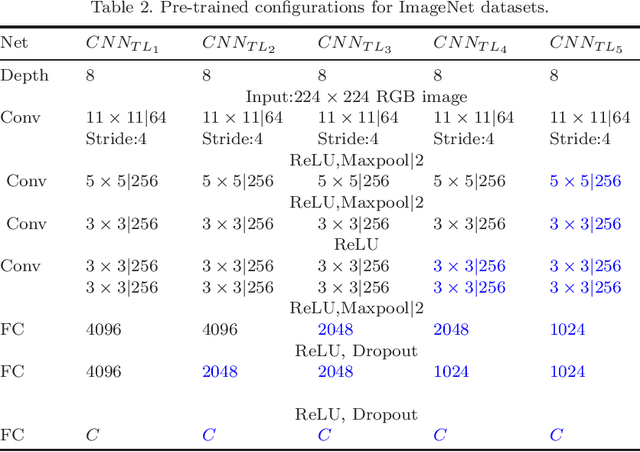
Deep learning has recently demonstrated its ability to rival the human brain for visual object recognition. As datasets get larger, a natural question to ask is if existing deep learning architectures can be extended to handle the 50+K classes thought to be perceptible by a typical human. Most deep learning architectures concentrate on splitting diverse categories, while ignoring the similarities amongst them. This paper introduces a framework that automatically analyzes and configures a family of smaller deep networks as a replacement to a singular, larger network. Class similarities guide the creation of a family from course to fine classifiers which solve categorical problems more effectively than a single large classifier. The resulting smaller networks are highly scalable, parallel and more practical to train, and achieve higher classification accuracy. This paper also proposes a method to adaptively select the configuration of the hierarchical family of classifiers using linkage statistics from overall and sub-classification confusion matrices. Depending on the number of classes and the complexity of the problem, a deep learning model is selected and the complexity is determined. Numerous experiments on network classes, layers, and architecture configurations validate our results.
Show, Translate and Tell
Mar 14, 2019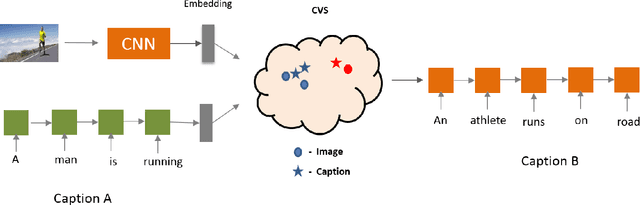
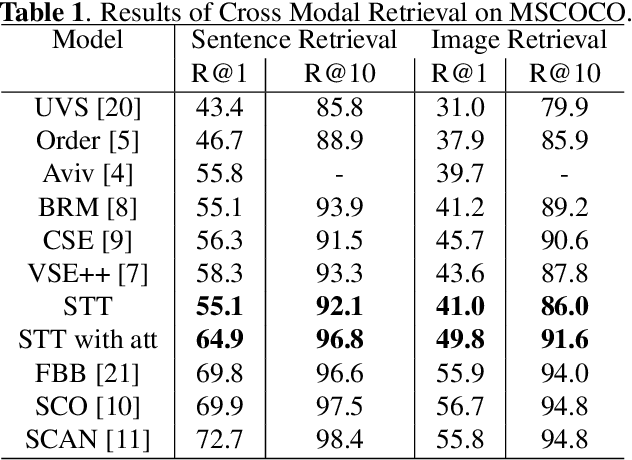
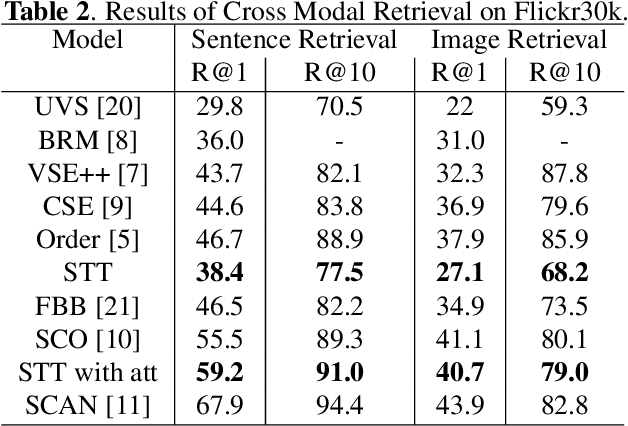
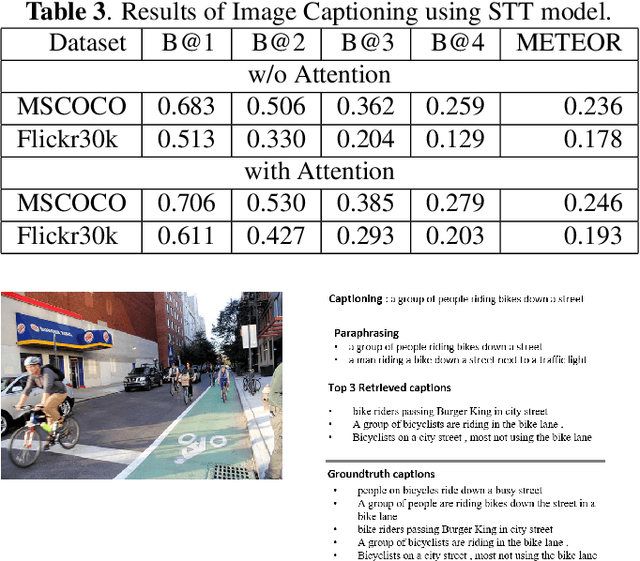
Humans have an incredible ability to process and understand information from multiple sources such as images, video, text, and speech. Recent success of deep neural networks has enabled us to develop algorithms which give machines the ability to understand and interpret this information. There is a need to both broaden their applicability and develop methods which correlate visual information along with semantic content. We propose a unified model which jointly trains on images and captions, and learns to generate new captions given either an image or a caption query. We evaluate our model on three different tasks namely cross-modal retrieval, image captioning, and sentence paraphrasing. Our model gains insight into cross-modal vector embeddings, generalizes well on multiple tasks and is competitive to state of the art methods on retrieval.
Vector Learning for Cross Domain Representations
Sep 27, 2018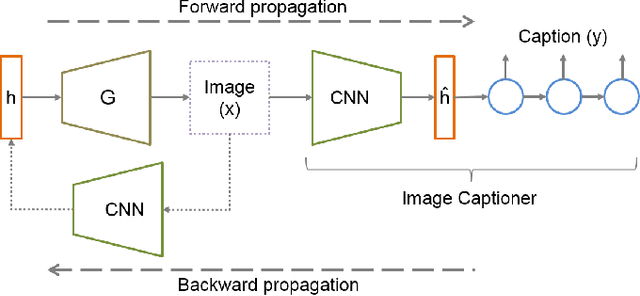


Recently, generative adversarial networks have gained a lot of popularity for image generation tasks. However, such models are associated with complex learning mechanisms and demand very large relevant datasets. This work borrows concepts from image and video captioning models to form an image generative framework. The model is trained in a similar fashion as recurrent captioning model and uses the learned weights for image generation. This is done in an inverse direction, where the input is a caption and the output is an image. The vector representation of the sentence and frames are extracted from an encoder-decoder model which is initially trained on similar sentence and image pairs. Our model conditions image generation on a natural language caption. We leverage a sequence-to-sequence model to generate synthetic captions that have the same meaning for having a robust image generation. One key advantage of our method is that the traditional image captioning datasets can be used for synthetic sentence paraphrases. Results indicate that images generated through multiple captions are better at capturing the semantic meaning of the family of captions.
Semantically Invariant Text-to-Image Generation
Sep 27, 2018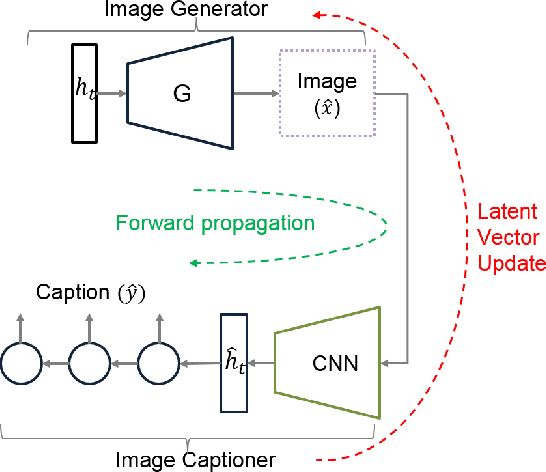
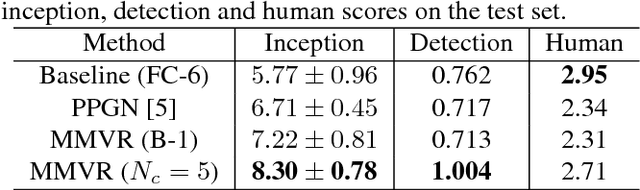

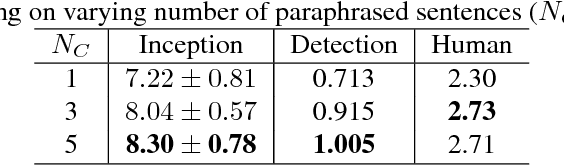
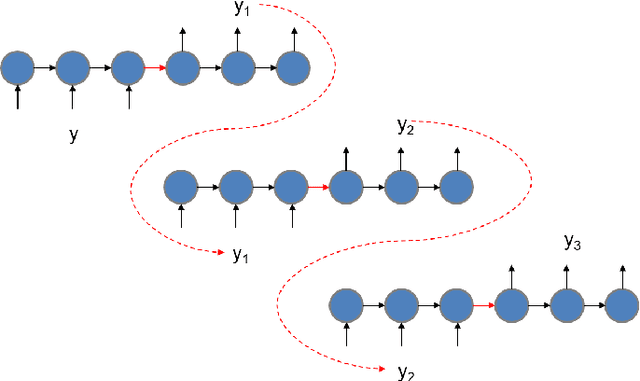
Image captioning has demonstrated models that are capable of generating plausible text given input images or videos. Further, recent work in image generation has shown significant improvements in image quality when text is used as a prior. Our work ties these concepts together by creating an architecture that can enable bidirectional generation of images and text. We call this network Multi-Modal Vector Representation (MMVR). Along with MMVR, we propose two improvements to the text conditioned image generation. Firstly, a n-gram metric based cost function is introduced that generalizes the caption with respect to the image. Secondly, multiple semantically similar sentences are shown to help in generating better images. Qualitative and quantitative evaluations demonstrate that MMVR improves upon existing text conditioned image generation results by over 20%, while integrating visual and text modalities.
Batch-normalized Recurrent Highway Networks
Sep 26, 2018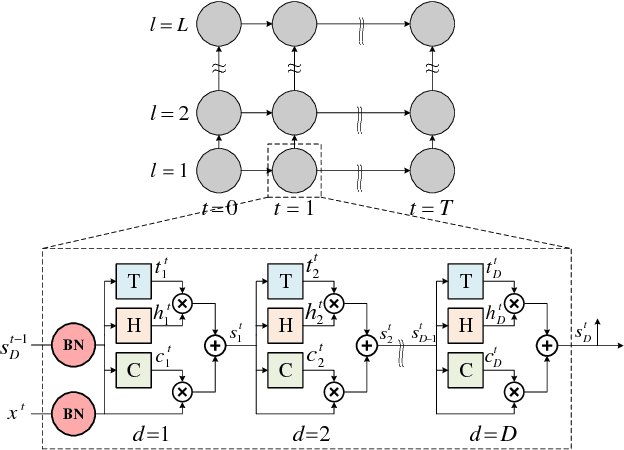

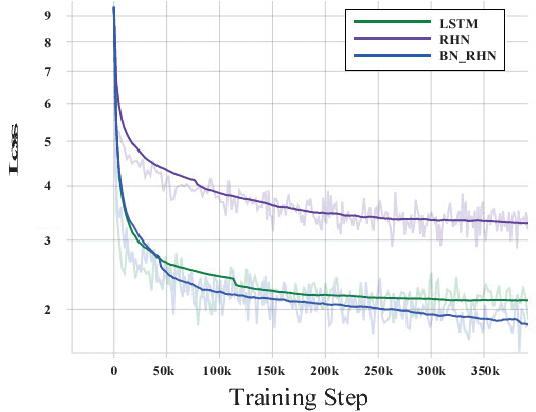

Gradient control plays an important role in feed-forward networks applied to various computer vision tasks. Previous work has shown that Recurrent Highway Networks minimize the problem of vanishing or exploding gradients. They achieve this by setting the eigenvalues of the temporal Jacobian to 1 across the time steps. In this work, batch normalized recurrent highway networks are proposed to control the gradient flow in an improved way for network convergence. Specifically, the introduced model can be formed by batch normalizing the inputs at each recurrence loop. The proposed model is tested on an image captioning task using MSCOCO dataset. Experimental results indicate that the batch normalized recurrent highway networks converge faster and performs better compared with the traditional LSTM and RHN based models.
Semantic Sentence Embeddings for Paraphrasing and Text Summarization
Sep 26, 2018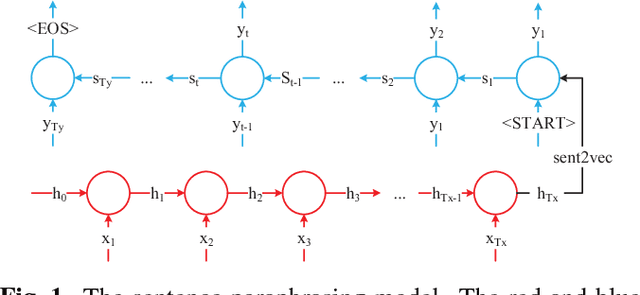
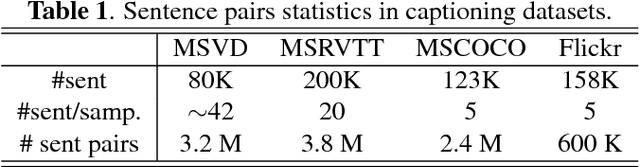
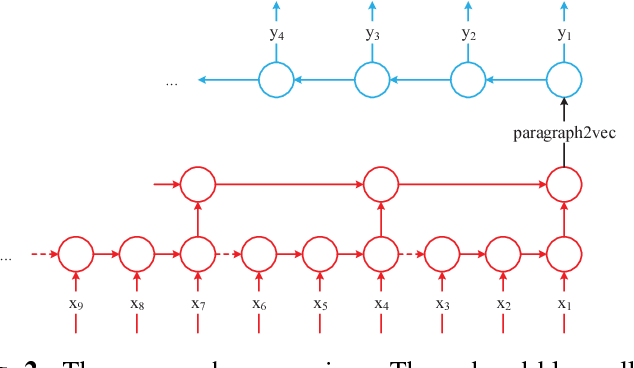
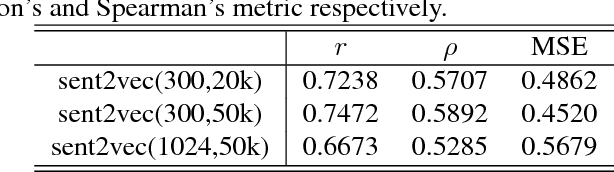
This paper introduces a sentence to vector encoding framework suitable for advanced natural language processing. Our latent representation is shown to encode sentences with common semantic information with similar vector representations. The vector representation is extracted from an encoder-decoder model which is trained on sentence paraphrase pairs. We demonstrate the application of the sentence representations for two different tasks -- sentence paraphrasing and paragraph summarization, making it attractive for commonly used recurrent frameworks that process text. Experimental results help gain insight how vector representations are suitable for advanced language embedding.
Robust Spatial Filtering with Graph Convolutional Neural Networks
Jul 14, 2017
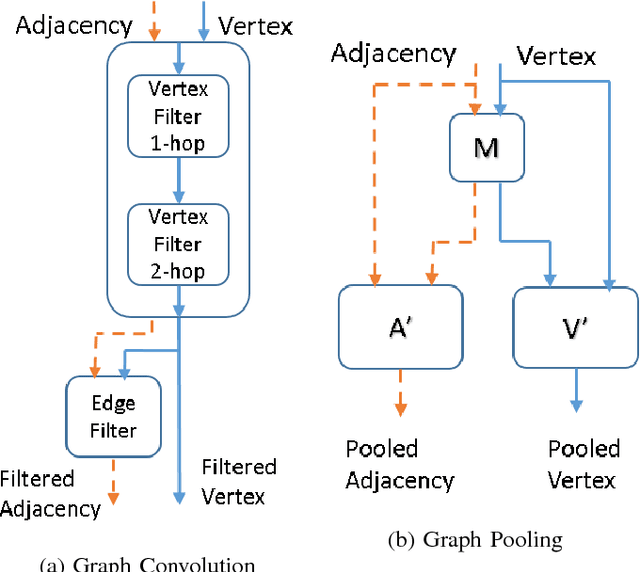
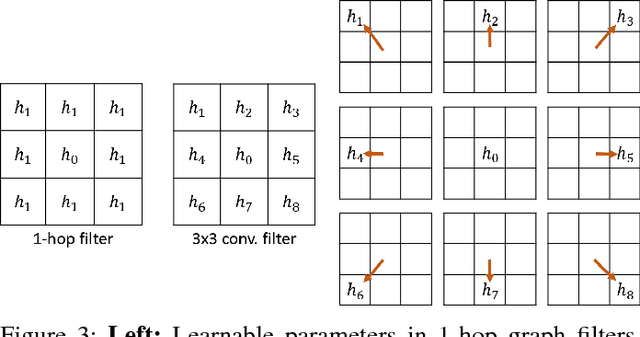
Convolutional Neural Networks (CNNs) have recently led to incredible breakthroughs on a variety of pattern recognition problems. Banks of finite impulse response filters are learned on a hierarchy of layers, each contributing more abstract information than the previous layer. The simplicity and elegance of the convolutional filtering process makes them perfect for structured problems such as image, video, or voice, where vertices are homogeneous in the sense of number, location, and strength of neighbors. The vast majority of classification problems, for example in the pharmaceutical, homeland security, and financial domains are unstructured. As these problems are formulated into unstructured graphs, the heterogeneity of these problems, such as number of vertices, number of connections per vertex, and edge strength, cannot be tackled with standard convolutional techniques. We propose a novel neural learning framework that is capable of handling both homogeneous and heterogeneous data, while retaining the benefits of traditional CNN successes. Recently, researchers have proposed variations of CNNs that can handle graph data. In an effort to create learnable filter banks of graphs, these methods either induce constraints on the data or require preprocessing. As opposed to spectral methods, our framework, which we term Graph-CNNs, defines filters as polynomials of functions of the graph adjacency matrix. Graph-CNNs can handle both heterogeneous and homogeneous graph data, including graphs having entirely different vertex or edge sets. We perform experiments to validate the applicability of Graph-CNNs to a variety of structured and unstructured classification problems and demonstrate state-of-the-art results on document and molecule classification problems.