 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
OpenAI o1 System Card
Dec 21, 2024



The o1 model series is trained with large-scale reinforcement learning to reason using chain of thought. These advanced reasoning capabilities provide new avenues for improving the safety and robustness of our models. In particular, our models can reason about our safety policies in context when responding to potentially unsafe prompts, through deliberative alignment. This leads to state-of-the-art performance on certain benchmarks for risks such as generating illicit advice, choosing stereotyped responses, and succumbing to known jailbreaks. Training models to incorporate a chain of thought before answering has the potential to unlock substantial benefits, while also increasing potential risks that stem from heightened intelligence. Our results underscore the need for building robust alignment methods, extensively stress-testing their efficacy, and maintaining meticulous risk management protocols. This report outlines the safety work carried out for the OpenAI o1 and OpenAI o1-mini models, including safety evaluations, external red teaming, and Preparedness Framework evaluations.
GPT-4o System Card
Oct 25, 2024GPT-4o is an autoregressive omni model that accepts as input any combination of text, audio, image, and video, and generates any combination of text, audio, and image outputs. It's trained end-to-end across text, vision, and audio, meaning all inputs and outputs are processed by the same neural network. GPT-4o can respond to audio inputs in as little as 232 milliseconds, with an average of 320 milliseconds, which is similar to human response time in conversation. It matches GPT-4 Turbo performance on text in English and code, with significant improvement on text in non-English languages, while also being much faster and 50\% cheaper in the API. GPT-4o is especially better at vision and audio understanding compared to existing models. In line with our commitment to building AI safely and consistent with our voluntary commitments to the White House, we are sharing the GPT-4o System Card, which includes our Preparedness Framework evaluations. In this System Card, we provide a detailed look at GPT-4o's capabilities, limitations, and safety evaluations across multiple categories, focusing on speech-to-speech while also evaluating text and image capabilities, and measures we've implemented to ensure the model is safe and aligned. We also include third-party assessments on dangerous capabilities, as well as discussion of potential societal impacts of GPT-4o's text and vision capabilities.
Text and Code Embeddings by Contrastive Pre-Training
Jan 24, 2022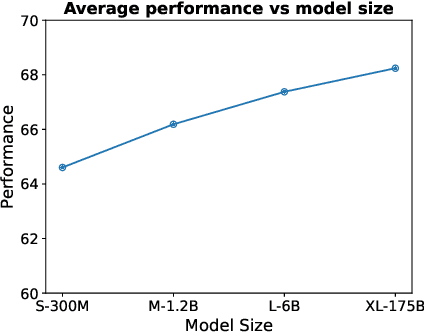
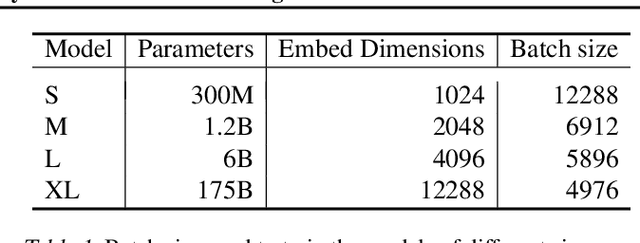
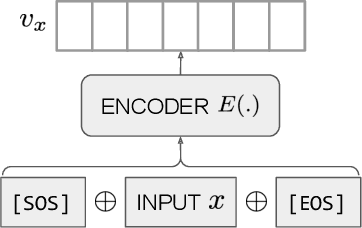
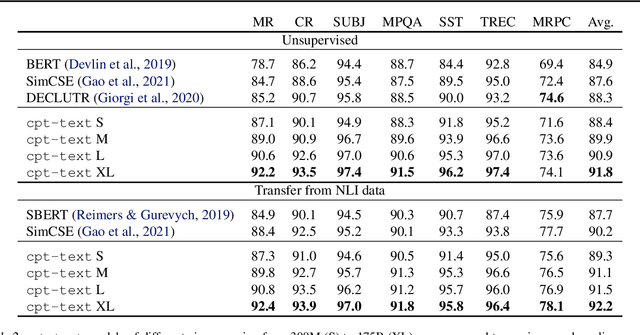
Text embeddings are useful features in many applications such as semantic search and computing text similarity. Previous work typically trains models customized for different use cases, varying in dataset choice, training objective and model architecture. In this work, we show that contrastive pre-training on unsupervised data at scale leads to high quality vector representations of text and code. The same unsupervised text embeddings that achieve new state-of-the-art results in linear-probe classification also display impressive semantic search capabilities and sometimes even perform competitively with fine-tuned models. On linear-probe classification accuracy averaging over 7 tasks, our best unsupervised model achieves a relative improvement of 4% and 1.8% over previous best unsupervised and supervised text embedding models respectively. The same text embeddings when evaluated on large-scale semantic search attains a relative improvement of 23.4%, 14.7%, and 10.6% over previous best unsupervised methods on MSMARCO, Natural Questions and TriviaQA benchmarks, respectively. Similarly to text embeddings, we train code embedding models on (text, code) pairs, obtaining a 20.8% relative improvement over prior best work on code search.
Evaluating Large Language Models Trained on Code
Jul 14, 2021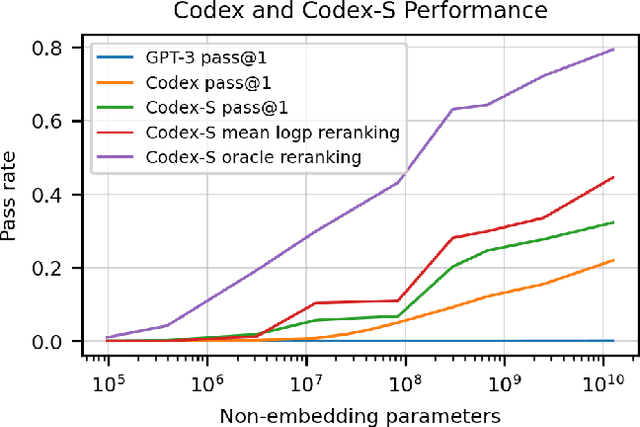
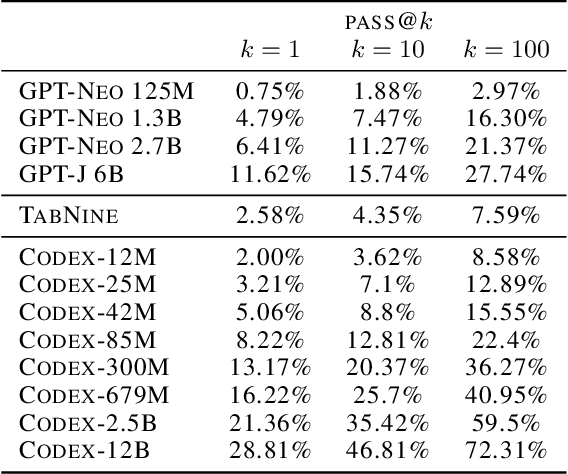
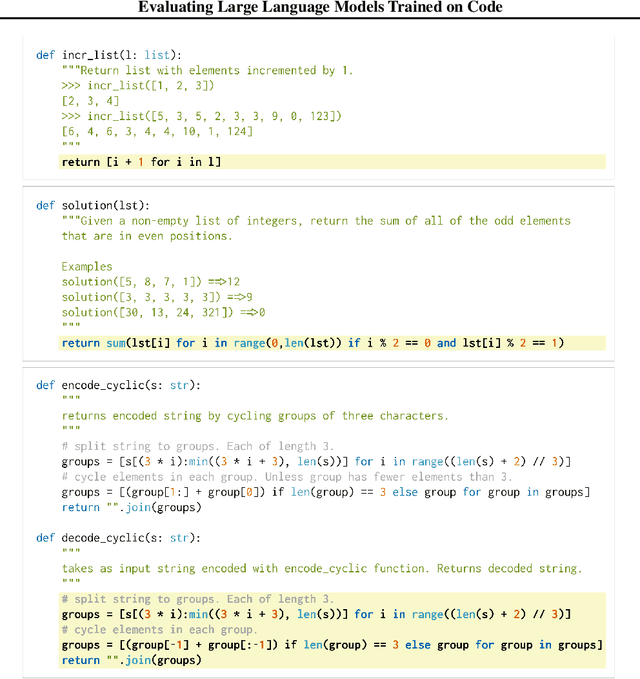
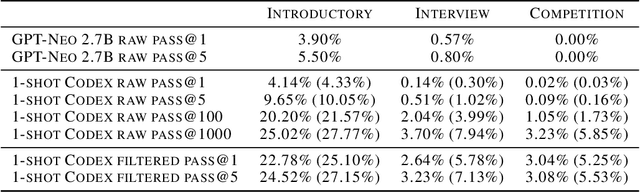
We introduce Codex, a GPT language model fine-tuned on publicly available code from GitHub, and study its Python code-writing capabilities. A distinct production version of Codex powers GitHub Copilot. On HumanEval, a new evaluation set we release to measure functional correctness for synthesizing programs from docstrings, our model solves 28.8% of the problems, while GPT-3 solves 0% and GPT-J solves 11.4%. Furthermore, we find that repeated sampling from the model is a surprisingly effective strategy for producing working solutions to difficult prompts. Using this method, we solve 70.2% of our problems with 100 samples per problem. Careful investigation of our model reveals its limitations, including difficulty with docstrings describing long chains of operations and with binding operations to variables. Finally, we discuss the potential broader impacts of deploying powerful code generation technologies, covering safety, security, and economics.
Synthetic Petri Dish: A Novel Surrogate Model for Rapid Architecture Search
May 27, 2020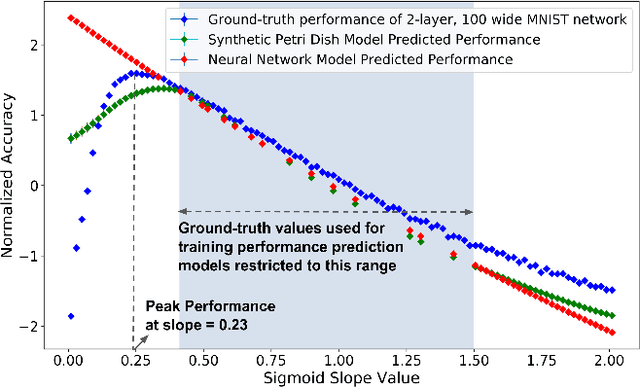
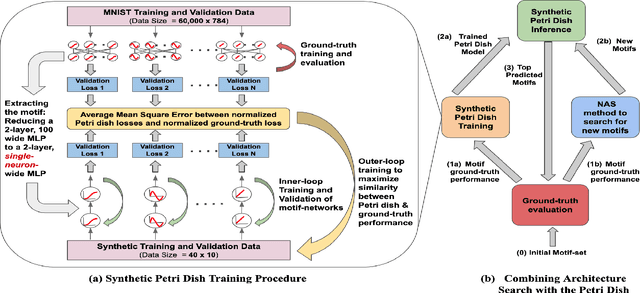
Neural Architecture Search (NAS) explores a large space of architectural motifs -- a compute-intensive process that often involves ground-truth evaluation of each motif by instantiating it within a large network, and training and evaluating the network with thousands of domain-specific data samples. Inspired by how biological motifs such as cells are sometimes extracted from their natural environment and studied in an artificial Petri dish setting, this paper proposes the Synthetic Petri Dish model for evaluating architectural motifs. In the Synthetic Petri Dish, architectural motifs are instantiated in very small networks and evaluated using very few learned synthetic data samples (to effectively approximate performance in the full problem). The relative performance of motifs in the Synthetic Petri Dish can substitute for their ground-truth performance, thus accelerating the most expensive step of NAS. Unlike other neural network-based prediction models that parse the structure of the motif to estimate its performance, the Synthetic Petri Dish predicts motif performance by training the actual motif in an artificial setting, thus deriving predictions from its true intrinsic properties. Experiments in this paper demonstrate that the Synthetic Petri Dish can therefore predict the performance of new motifs with significantly higher accuracy, especially when insufficient ground truth data is available. Our hope is that this work can inspire a new research direction in studying the performance of extracted components of models in an alternative controlled setting.
Generalized Hidden Parameter MDPs Transferable Model-based RL in a Handful of Trials
Feb 08, 2020
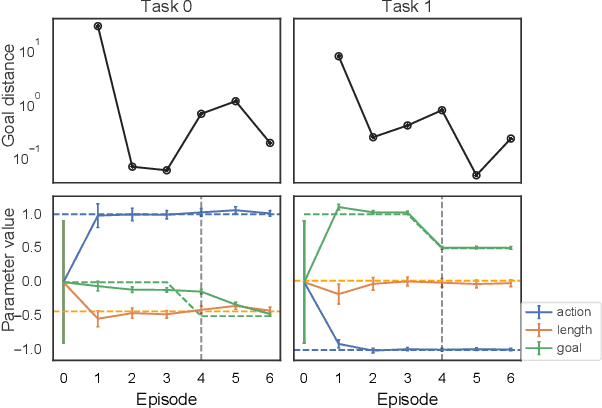

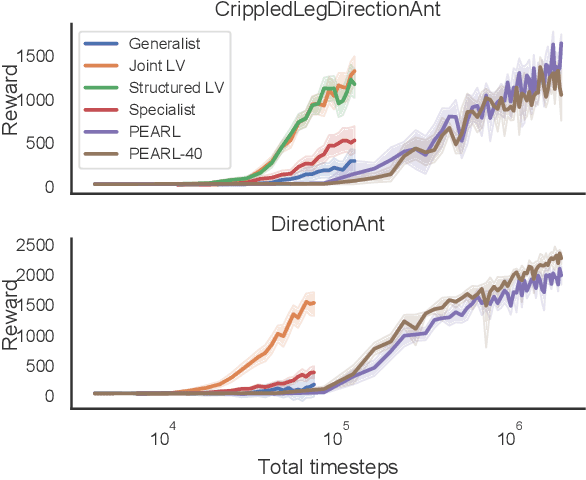
There is broad interest in creating RL agents that can solve many (related) tasks and adapt to new tasks and environments after initial training. Model-based RL leverages learned surrogate models that describe dynamics and rewards of individual tasks, such that planning in a good surrogate can lead to good control of the true system. Rather than solving each task individually from scratch, hierarchical models can exploit the fact that tasks are often related by (unobserved) causal factors of variation in order to achieve efficient generalization, as in learning how the mass of an item affects the force required to lift it can generalize to previously unobserved masses. We propose Generalized Hidden Parameter MDPs (GHP-MDPs) that describe a family of MDPs where both dynamics and reward can change as a function of hidden parameters that vary across tasks. The GHP-MDP augments model-based RL with latent variables that capture these hidden parameters, facilitating transfer across tasks. We also explore a variant of the model that incorporates explicit latent structure mirroring the causal factors of variation across tasks (for instance: agent properties, environmental factors, and goals). We experimentally demonstrate state-of-the-art performance and sample-efficiency on a new challenging MuJoCo task using reward and dynamics latent spaces, while beating a previous state-of-the-art baseline with $>10\times$ less data. Using test-time inference of the latent variables, our approach generalizes in a single episode to novel combinations of dynamics and reward, and to novel rewards.
Generative Teaching Networks: Accelerating Neural Architecture Search by Learning to Generate Synthetic Training Data
Dec 17, 2019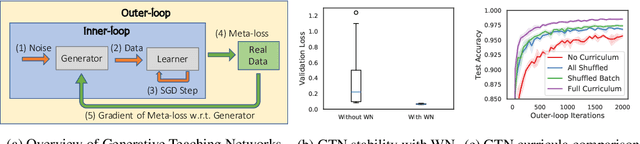
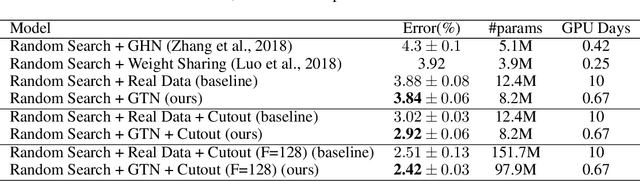
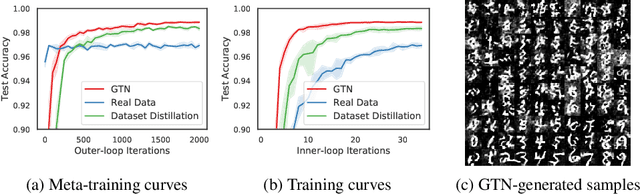
This paper investigates the intriguing question of whether we can create learning algorithms that automatically generate training data, learning environments, and curricula in order to help AI agents rapidly learn. We show that such algorithms are possible via Generative Teaching Networks (GTNs), a general approach that is, in theory, applicable to supervised, unsupervised, and reinforcement learning, although our experiments only focus on the supervised case. GTNs are deep neural networks that generate data and/or training environments that a learner (e.g. a freshly initialized neural network) trains on for a few SGD steps before being tested on a target task. We then differentiate through the entire learning process via meta-gradients to update the GTN parameters to improve performance on the target task. GTNs have the beneficial property that they can theoretically generate any type of data or training environment, making their potential impact large. This paper introduces GTNs, discusses their potential, and showcases that they can substantially accelerate learning. We also demonstrate a practical and exciting application of GTNs: accelerating the evaluation of candidate architectures for neural architecture search (NAS), which is rate-limited by such evaluations, enabling massive speed-ups in NAS. GTN-NAS improves the NAS state of the art, finding higher performing architectures when controlling for the search proposal mechanism. GTN-NAS also is competitive with the overall state of the art approaches, which achieve top performance while using orders of magnitude less computation than typical NAS methods. Speculating forward, GTNs may represent a first step toward the ambitious goal of algorithms that generate their own training data and, in doing so, open a variety of interesting new research questions and directions.
Fully Convolutional Networks for Handwriting Recognition
Jul 10, 2019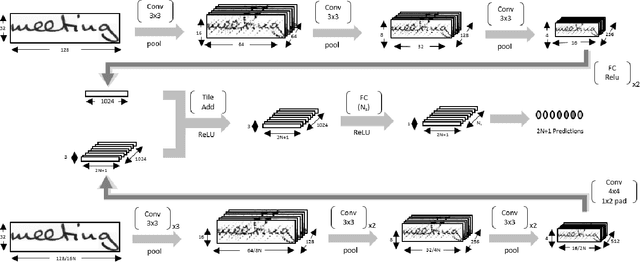
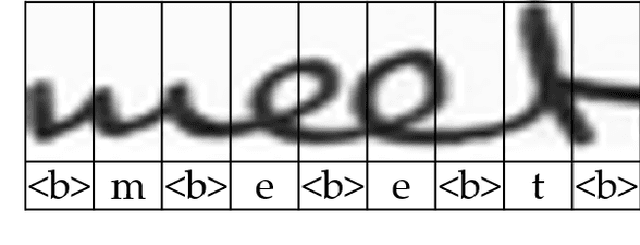
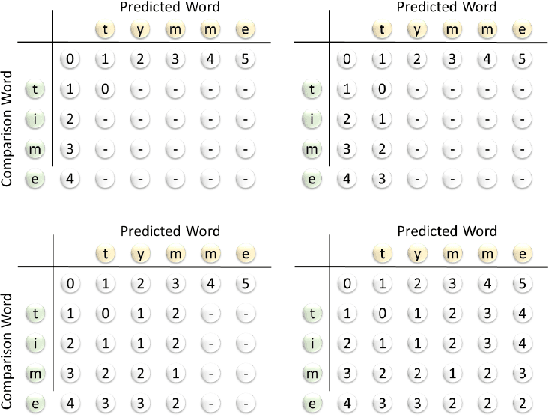
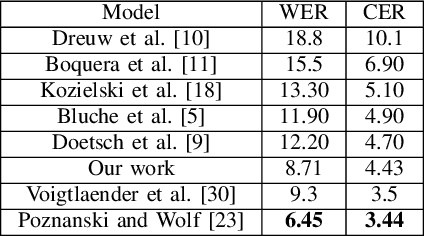
Handwritten text recognition is challenging because of the virtually infinite ways a human can write the same message. Our fully convolutional handwriting model takes in a handwriting sample of unknown length and outputs an arbitrary stream of symbols. Our dual stream architecture uses both local and global context and mitigates the need for heavy preprocessing steps such as symbol alignment correction as well as complex post processing steps such as connectionist temporal classification, dictionary matching or language models. Using over 100 unique symbols, our model is agnostic to Latin-based languages, and is shown to be quite competitive with state of the art dictionary based methods on the popular IAM and RIMES datasets. When a dictionary is known, we further allow a probabilistic character error rate to correct errant word blocks. Finally, we introduce an attention based mechanism which can automatically target variants of handwriting, such as slant, stroke width, or noise.
An Atari Model Zoo for Analyzing, Visualizing, and Comparing Deep Reinforcement Learning Agents
Dec 17, 2018

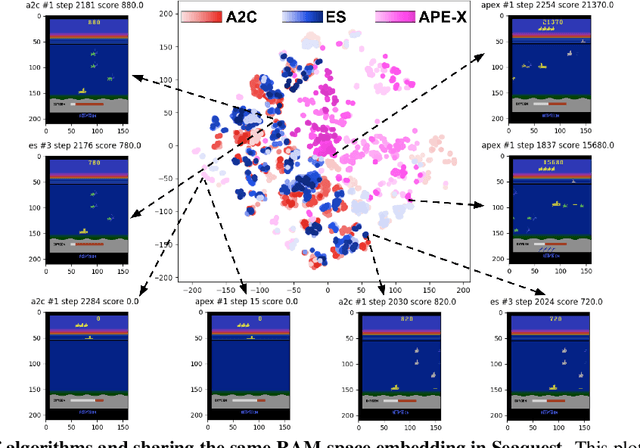
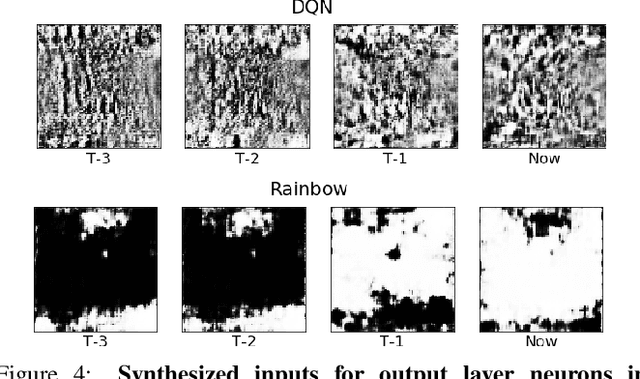
Much human and computational effort has aimed to improve how deep reinforcement learning algorithms perform on benchmarks such as the Atari Learning Environment. Comparatively less effort has focused on understanding what has been learned by such methods, and investigating and comparing the representations learned by different families of reinforcement learning (RL) algorithms. Sources of friction include the onerous computational requirements, and general logistical and architectural complications for running Deep RL algorithms at scale. We lessen this friction, by (1) training several algorithms at scale and releasing trained models, (2) integrating with a previous Deep RL model release, and (3) releasing code that makes it easy for anyone to load, visualize, and analyze such models. This paper introduces the Atari Zoo framework, which contains models trained across benchmark Atari games, in an easy-to-use format, as well as code that implements common modes of analysis and connects such models to a popular neural network visualization library. Further, to demonstrate the potential of this dataset and software package, we show initial quantitative and qualitative comparisons between the performance and representations of several deep RL algorithms, highlighting interesting and previously unknown distinctions between them.