 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBigger, Better, Faster: Human-level Atari with human-level efficiency
Jun 09, 2023



We introduce a value-based RL agent, which we call BBF, that achieves super-human performance in the Atari 100K benchmark. BBF relies on scaling the neural networks used for value estimation, as well as a number of other design choices that enable this scaling in a sample-efficient manner. We conduct extensive analyses of these design choices and provide insights for future work. We end with a discussion about updating the goalposts for sample-efficient RL research on the ALE. We make our code and data publicly available at https://github.com/google-research/google-research/tree/master/bigger_better_faster.
An Atari Model Zoo for Analyzing, Visualizing, and Comparing Deep Reinforcement Learning Agents
Dec 17, 2018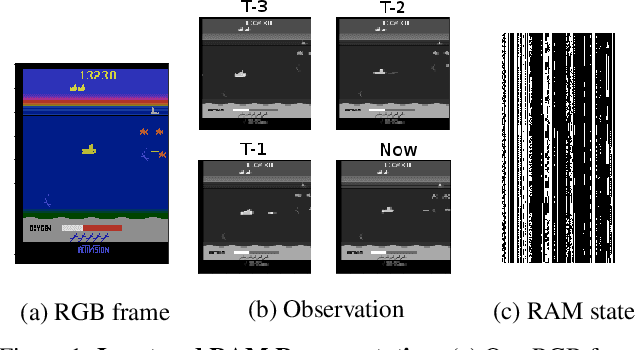

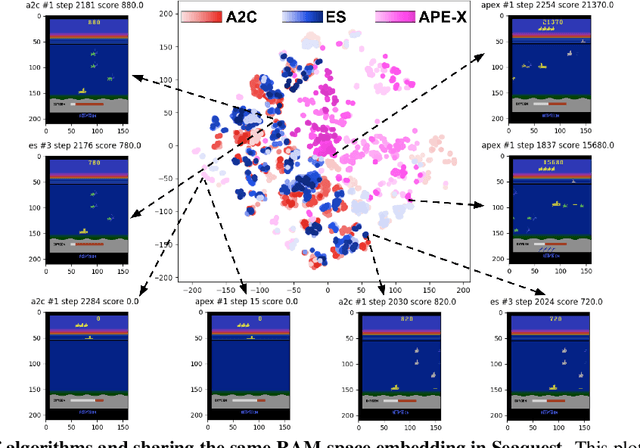
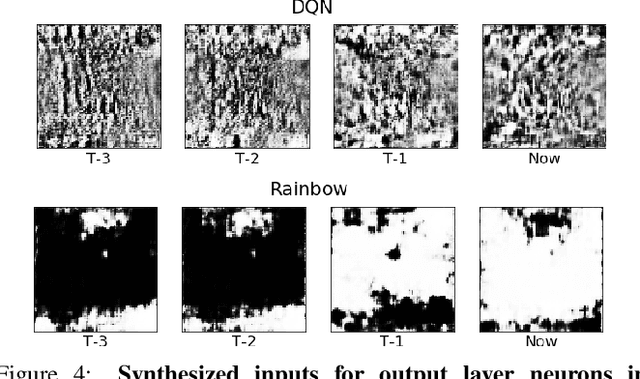
Much human and computational effort has aimed to improve how deep reinforcement learning algorithms perform on benchmarks such as the Atari Learning Environment. Comparatively less effort has focused on understanding what has been learned by such methods, and investigating and comparing the representations learned by different families of reinforcement learning (RL) algorithms. Sources of friction include the onerous computational requirements, and general logistical and architectural complications for running Deep RL algorithms at scale. We lessen this friction, by (1) training several algorithms at scale and releasing trained models, (2) integrating with a previous Deep RL model release, and (3) releasing code that makes it easy for anyone to load, visualize, and analyze such models. This paper introduces the Atari Zoo framework, which contains models trained across benchmark Atari games, in an easy-to-use format, as well as code that implements common modes of analysis and connects such models to a popular neural network visualization library. Further, to demonstrate the potential of this dataset and software package, we show initial quantitative and qualitative comparisons between the performance and representations of several deep RL algorithms, highlighting interesting and previously unknown distinctions between them.
The Barbados 2018 List of Open Issues in Continual Learning
Nov 16, 2018We want to make progress toward artificial general intelligence, namely general-purpose agents that autonomously learn how to competently act in complex environments. The purpose of this report is to sketch a research outline, share some of the most important open issues we are facing, and stimulate further discussion in the community. The content is based on some of our discussions during a week-long workshop held in Barbados in February 2018.
The Reactor: A fast and sample-efficient Actor-Critic agent for Reinforcement Learning
Jun 19, 2018



In this work we present a new agent architecture, called Reactor, which combines multiple algorithmic and architectural contributions to produce an agent with higher sample-efficiency than Prioritized Dueling DQN (Wang et al., 2016) and Categorical DQN (Bellemare et al., 2017), while giving better run-time performance than A3C (Mnih et al., 2016). Our first contribution is a new policy evaluation algorithm called Distributional Retrace, which brings multi-step off-policy updates to the distributional reinforcement learning setting. The same approach can be used to convert several classes of multi-step policy evaluation algorithms designed for expected value evaluation into distributional ones. Next, we introduce the \b{eta}-leave-one-out policy gradient algorithm which improves the trade-off between variance and bias by using action values as a baseline. Our final algorithmic contribution is a new prioritized replay algorithm for sequences, which exploits the temporal locality of neighboring observations for more efficient replay prioritization. Using the Atari 2600 benchmarks, we show that each of these innovations contribute to both the sample efficiency and final agent performance. Finally, we demonstrate that Reactor reaches state-of-the-art performance after 200 million frames and less than a day of training.