 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhanced POET: Open-Ended Reinforcement Learning through Unbounded Invention of Learning Challenges and their Solutions
Apr 13, 2020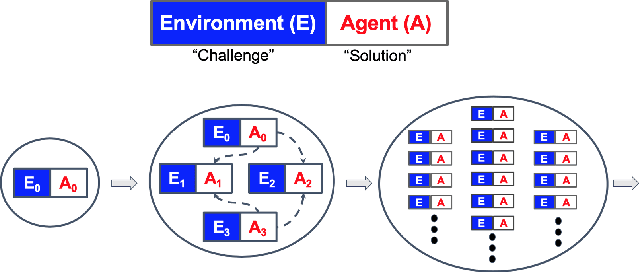

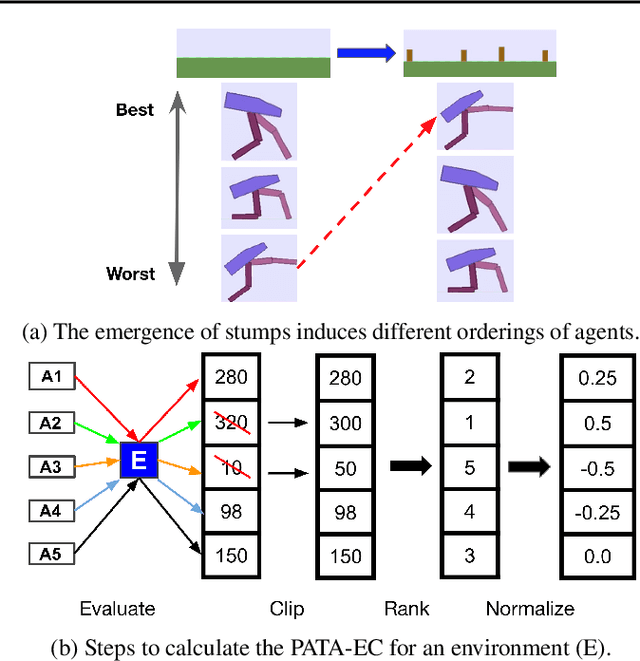
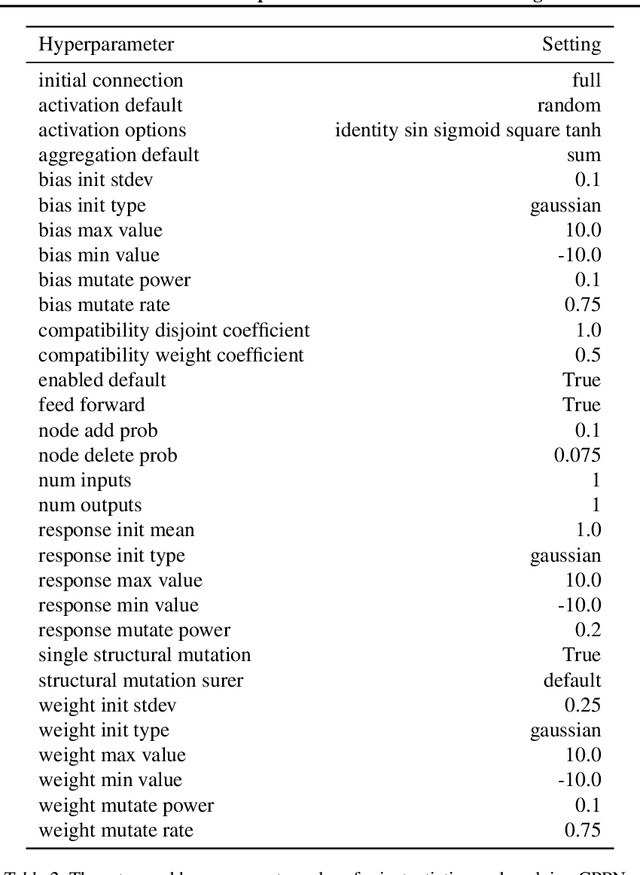
Creating open-ended algorithms, which generate their own never-ending stream of novel and appropriately challenging learning opportunities, could help to automate and accelerate progress in machine learning. A recent step in this direction is the Paired Open-Ended Trailblazer (POET), an algorithm that generates and solves its own challenges, and allows solutions to goal-switch between challenges to avoid local optima. However, the original POET was unable to demonstrate its full creative potential because of limitations of the algorithm itself and because of external issues including a limited problem space and lack of a universal progress measure. Importantly, both limitations pose impediments not only for POET, but for the pursuit of open-endedness in general. Here we introduce and empirically validate two new innovations to the original algorithm, as well as two external innovations designed to help elucidate its full potential. Together, these four advances enable the most open-ended algorithmic demonstration to date. The algorithmic innovations are (1) a domain-general measure of how meaningfully novel new challenges are, enabling the system to potentially create and solve interesting challenges endlessly, and (2) an efficient heuristic for determining when agents should goal-switch from one problem to another (helping open-ended search better scale). Outside the algorithm itself, to enable a more definitive demonstration of open-endedness, we introduce (3) a novel, more flexible way to encode environmental challenges, and (4) a generic measure of the extent to which a system continues to exhibit open-ended innovation. Enhanced POET produces a diverse range of sophisticated behaviors that solve a wide range of environmental challenges, many of which cannot be solved through other means.
An Atari Model Zoo for Analyzing, Visualizing, and Comparing Deep Reinforcement Learning Agents
Dec 17, 2018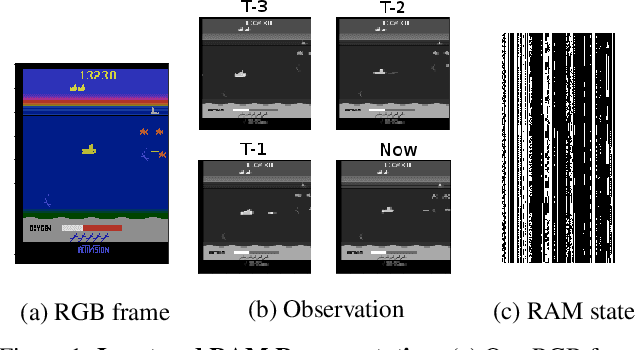

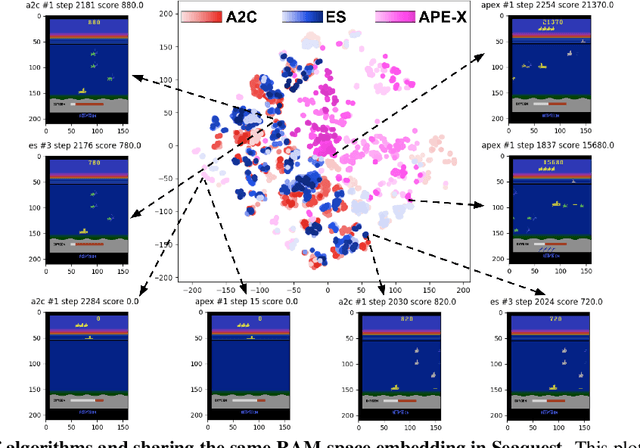
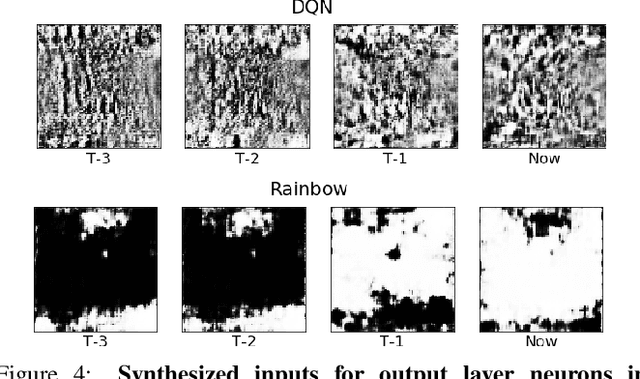
Much human and computational effort has aimed to improve how deep reinforcement learning algorithms perform on benchmarks such as the Atari Learning Environment. Comparatively less effort has focused on understanding what has been learned by such methods, and investigating and comparing the representations learned by different families of reinforcement learning (RL) algorithms. Sources of friction include the onerous computational requirements, and general logistical and architectural complications for running Deep RL algorithms at scale. We lessen this friction, by (1) training several algorithms at scale and releasing trained models, (2) integrating with a previous Deep RL model release, and (3) releasing code that makes it easy for anyone to load, visualize, and analyze such models. This paper introduces the Atari Zoo framework, which contains models trained across benchmark Atari games, in an easy-to-use format, as well as code that implements common modes of analysis and connects such models to a popular neural network visualization library. Further, to demonstrate the potential of this dataset and software package, we show initial quantitative and qualitative comparisons between the performance and representations of several deep RL algorithms, highlighting interesting and previously unknown distinctions between them.