 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuroraCap: Efficient, Performant Video Detailed Captioning and a New Benchmark
Oct 04, 2024



Video detailed captioning is a key task which aims to generate comprehensive and coherent textual descriptions of video content, benefiting both video understanding and generation. In this paper, we propose AuroraCap, a video captioner based on a large multimodal model. We follow the simplest architecture design without additional parameters for temporal modeling. To address the overhead caused by lengthy video sequences, we implement the token merging strategy, reducing the number of input visual tokens. Surprisingly, we found that this strategy results in little performance loss. AuroraCap shows superior performance on various video and image captioning benchmarks, for example, obtaining a CIDEr of 88.9 on Flickr30k, beating GPT-4V (55.3) and Gemini-1.5 Pro (82.2). However, existing video caption benchmarks only include simple descriptions, consisting of a few dozen words, which limits research in this field. Therefore, we develop VDC, a video detailed captioning benchmark with over one thousand carefully annotated structured captions. In addition, we propose a new LLM-assisted metric VDCscore for bettering evaluation, which adopts a divide-and-conquer strategy to transform long caption evaluation into multiple short question-answer pairs. With the help of human Elo ranking, our experiments show that this benchmark better correlates with human judgments of video detailed captioning quality.
DECORE: Deep Compression with Reinforcement Learning
Jun 11, 2021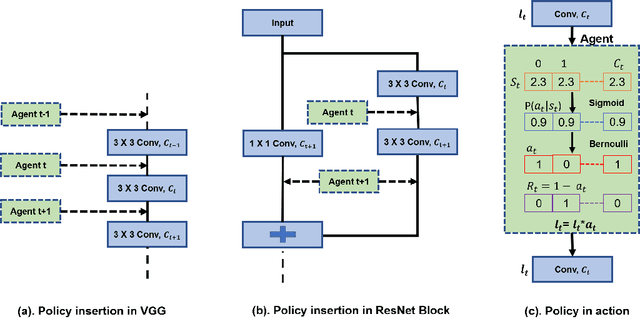


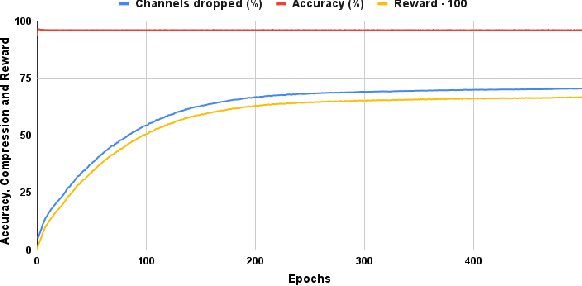
Deep learning has become an increasingly popular and powerful option for modern pattern recognition systems. However, many deep neural networks have millions to billions of parameters, making them untenable for real-world applications with constraints on memory or latency. As a result, powerful network compression techniques are a must for the widespread adoption of deep learning. We present DECORE, a reinforcement learning approach to automate the network compression process. Using a simple policy gradient method to learn which neurons or channels to keep or remove, we are able to achieve compression rates 3x to 5x greater than contemporary approaches. In contrast with other architecture search methods, DECORE is simple and quick to train, requiring only a few hours of training on 1 GPU. When applied to standard network architectures on different datasets, our approach achieves 11x to 103x compression on different architectures while maintaining accuracies similar to those of the original, large networks.
Scaling MAP-Elites to Deep Neuroevolution
Mar 03, 2020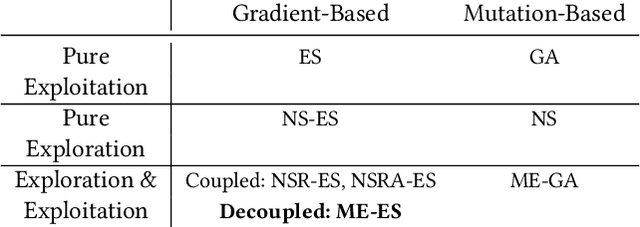
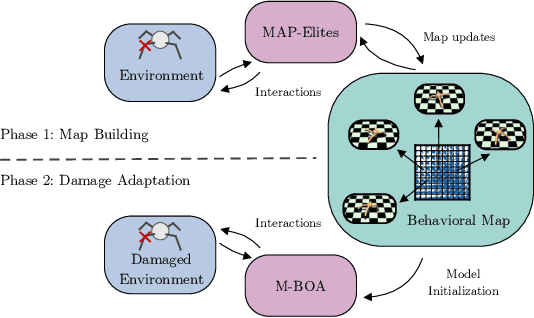
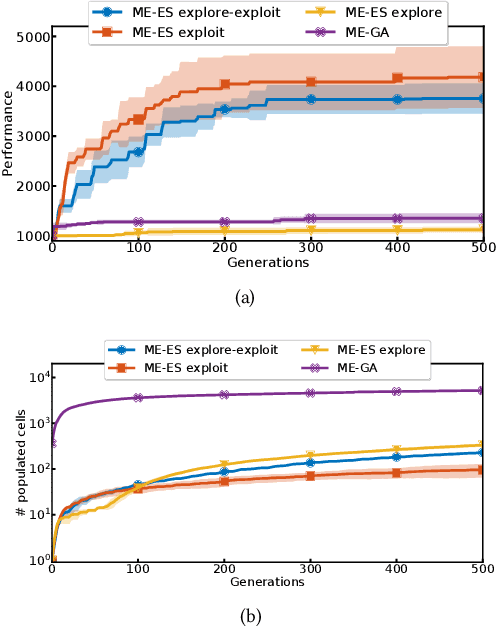

Quality-Diversity (QD) algorithms, and MAP-Elites (ME) in particular, have proven very useful for a broad range of applications including enabling real robots to recover quickly from joint damage, solving strongly deceptive maze tasks or evolving robot morphologies to discover new gaits. However, present implementations of MAP-Elites and other QD algorithms seem to be limited to low-dimensional controllers with far fewer parameters than modern deep neural network models. In this paper, we propose to leverage the efficiency of Evolution Strategies (ES) to scale MAP-Elites to high-dimensional controllers parameterized by large neural networks. We design and evaluate a new hybrid algorithm called MAP-Elites with Evolution Strategies (ME-ES) for post-damage recovery in a difficult high-dimensional control task where traditional ME fails. Additionally,we show that ME-ES performs efficient exploration, on par with state-of-the-art exploration algorithms in high-dimensional control tasks with strongly deceptive rewards.
An Atari Model Zoo for Analyzing, Visualizing, and Comparing Deep Reinforcement Learning Agents
Dec 17, 2018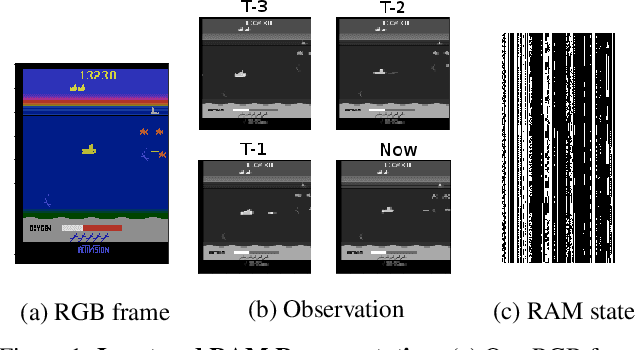

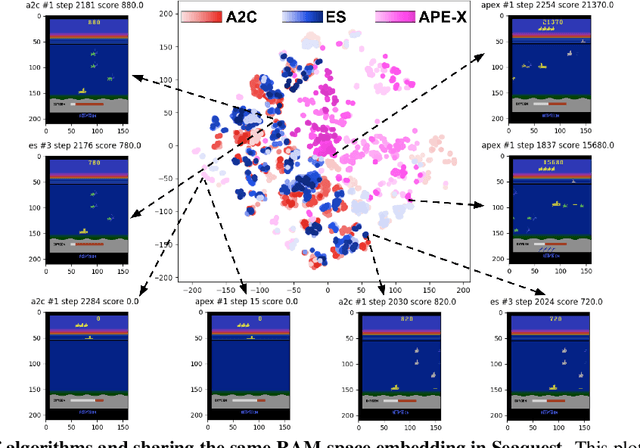
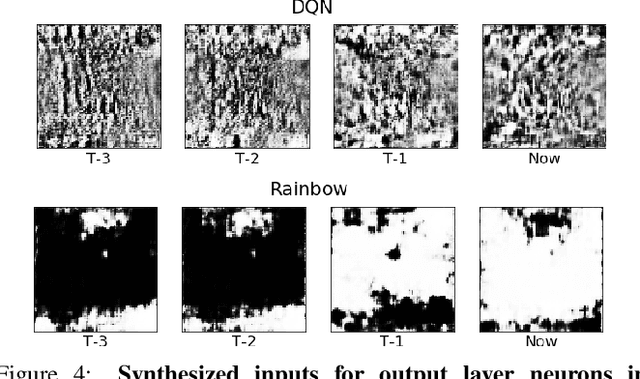
Much human and computational effort has aimed to improve how deep reinforcement learning algorithms perform on benchmarks such as the Atari Learning Environment. Comparatively less effort has focused on understanding what has been learned by such methods, and investigating and comparing the representations learned by different families of reinforcement learning (RL) algorithms. Sources of friction include the onerous computational requirements, and general logistical and architectural complications for running Deep RL algorithms at scale. We lessen this friction, by (1) training several algorithms at scale and releasing trained models, (2) integrating with a previous Deep RL model release, and (3) releasing code that makes it easy for anyone to load, visualize, and analyze such models. This paper introduces the Atari Zoo framework, which contains models trained across benchmark Atari games, in an easy-to-use format, as well as code that implements common modes of analysis and connects such models to a popular neural network visualization library. Further, to demonstrate the potential of this dataset and software package, we show initial quantitative and qualitative comparisons between the performance and representations of several deep RL algorithms, highlighting interesting and previously unknown distinctions between them.
Improving Exploration in Evolution Strategies for Deep Reinforcement Learning via a Population of Novelty-Seeking Agents
Oct 29, 2018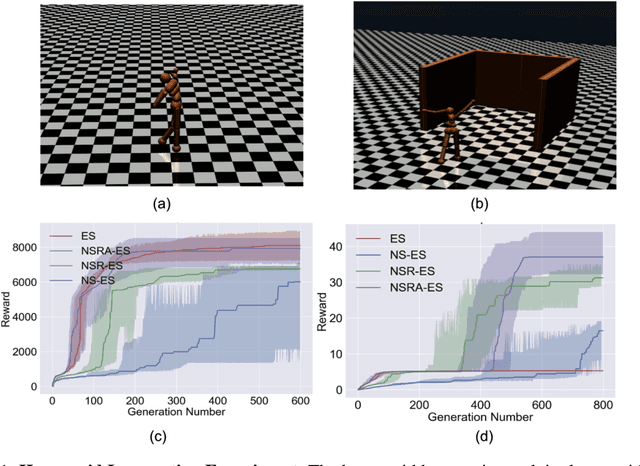
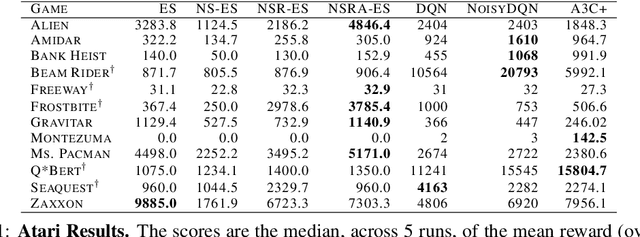

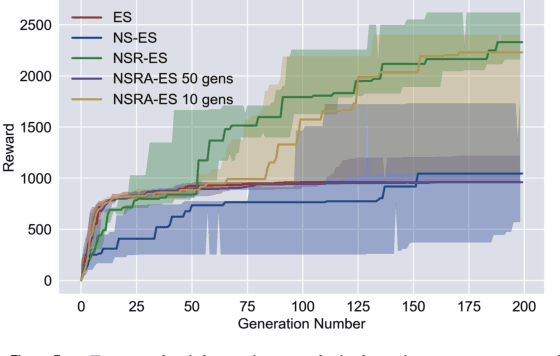
Evolution strategies (ES) are a family of black-box optimization algorithms able to train deep neural networks roughly as well as Q-learning and policy gradient methods on challenging deep reinforcement learning (RL) problems, but are much faster (e.g. hours vs. days) because they parallelize better. However, many RL problems require directed exploration because they have reward functions that are sparse or deceptive (i.e. contain local optima), and it is unknown how to encourage such exploration with ES. Here we show that algorithms that have been invented to promote directed exploration in small-scale evolved neural networks via populations of exploring agents, specifically novelty search (NS) and quality diversity (QD) algorithms, can be hybridized with ES to improve its performance on sparse or deceptive deep RL tasks, while retaining scalability. Our experiments confirm that the resultant new algorithms, NS-ES and two QD algorithms, NSR-ES and NSRA-ES, avoid local optima encountered by ES to achieve higher performance on Atari and simulated robots learning to walk around a deceptive trap. This paper thus introduces a family of fast, scalable algorithms for reinforcement learning that are capable of directed exploration. It also adds this new family of exploration algorithms to the RL toolbox and raises the interesting possibility that analogous algorithms with multiple simultaneous paths of exploration might also combine well with existing RL algorithms outside ES.
BDD100K: A Diverse Driving Video Database with Scalable Annotation Tooling
May 12, 2018

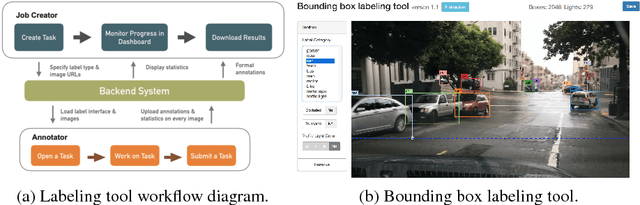
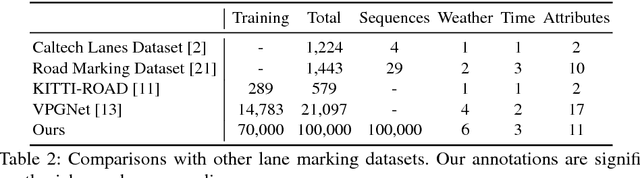
Datasets drive vision progress and autonomous driving is a critical vision application, yet existing driving datasets are impoverished in terms of visual content. Driving imagery is becoming plentiful, but annotation is slow and expensive, as annotation tools have not kept pace with the flood of data. Our first contribution is the design and implementation of a scalable annotation system that can provide a comprehensive set of image labels for large-scale driving datasets. Our second contribution is a new driving dataset, facilitated by our tooling, which is an order of magnitude larger than previous efforts, and is comprised of over 100K videos with diverse kinds of annotations including image level tagging, object bounding boxes, drivable areas, lane markings, and full-frame instance segmentation. The dataset possesses geographic, environmental, and weather diversity, which is useful for training models so that they are less likely to be surprised by new conditions. The dataset can be requested at http://bdd-data.berkeley.edu.
Deep Neuroevolution: Genetic Algorithms Are a Competitive Alternative for Training Deep Neural Networks for Reinforcement Learning
Apr 20, 2018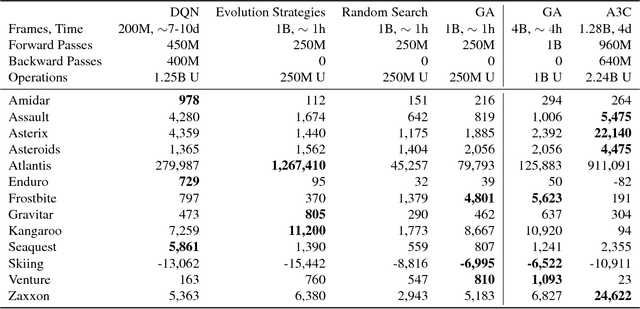
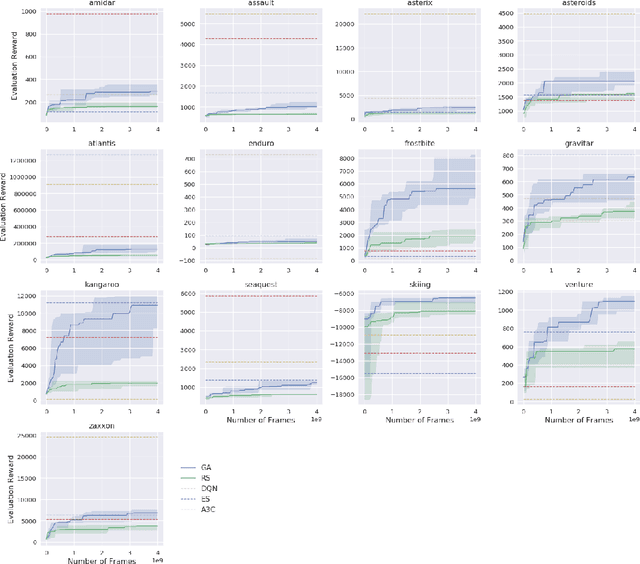
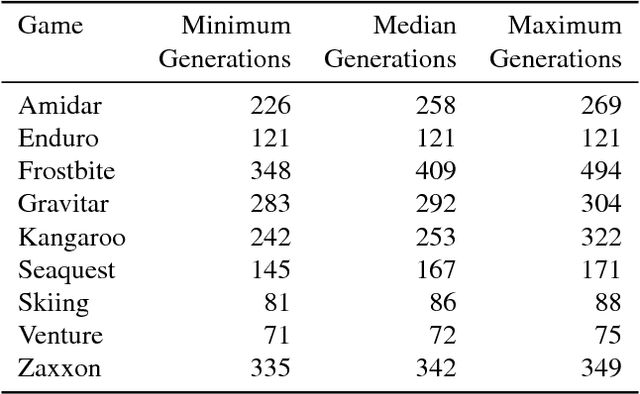
Deep artificial neural networks (DNNs) are typically trained via gradient-based learning algorithms, namely backpropagation. Evolution strategies (ES) can rival backprop-based algorithms such as Q-learning and policy gradients on challenging deep reinforcement learning (RL) problems. However, ES can be considered a gradient-based algorithm because it performs stochastic gradient descent via an operation similar to a finite-difference approximation of the gradient. That raises the question of whether non-gradient-based evolutionary algorithms can work at DNN scales. Here we demonstrate they can: we evolve the weights of a DNN with a simple, gradient-free, population-based genetic algorithm (GA) and it performs well on hard deep RL problems, including Atari and humanoid locomotion. The Deep GA successfully evolves networks with over four million free parameters, the largest neural networks ever evolved with a traditional evolutionary algorithm. These results (1) expand our sense of the scale at which GAs can operate, (2) suggest intriguingly that in some cases following the gradient is not the best choice for optimizing performance, and (3) make immediately available the multitude of neuroevolution techniques that improve performance. We demonstrate the latter by showing that combining DNNs with novelty search, which encourages exploration on tasks with deceptive or sparse reward functions, can solve a high-dimensional problem on which reward-maximizing algorithms (e.g.\ DQN, A3C, ES, and the GA) fail. Additionally, the Deep GA is faster than ES, A3C, and DQN (it can train Atari in ${\raise.17ex\hbox{$\scriptstyle\sim$}}$4 hours on one desktop or ${\raise.17ex\hbox{$\scriptstyle\sim$}}$1 hour distributed on 720 cores), and enables a state-of-the-art, up to 10,000-fold compact encoding technique.